Kafka vs. RabbitMQ #2: Head-To-Head
August 11, 2022
As dealing with microservice-based systems, we often encounter the ever-repeating question , “Should I use RabbitMQ or Kafka?” For some reason, many developers view these technologies as interchangeable. While this is true for some cases, there are various underlying differences between these platforms.
As a result, different scenarios require a different solution, and choosing the wrong one might severely impact your ability to design, develop, and maintain your software solution.
Part 1 of this series explains the internal implementation concepts of both RabbitMQ and Apache Kafka. This part continues to review notable differences between these two platforms, differences that we should note as software architects and developers.
Then, it proceeds to explain the architecture patterns we usually try to implement with these tools and assess when to use each.
RabbitMQ is a message broker, while Apache Kafka is a distributed streaming platform. This difference might seem semantic, but it entails severe implications that impact our ability to implement various use cases comfortably.
For example, Kafka is best used for processing streams of data, while RabbitMQ has minimal guarantees regarding the ordering of messages within a stream.
On the other hand, RabbitMQ has built-in support for retry logic and dead-letter exchanges, while Kafka leaves such implementations in the hands of its users.
This section highlights these and other notable differences between these distinct platforms.
Message ordering #
RabbitMQ provides few guarantees regarding the ordering of messages sent to a queue or exchange. While it may seem evident that consumers process messages in the order in which producers sent them, this is very misleading.
The RabbitMQ documentation states the following regarding its ordering guarantees:
messages published in one channel, passing through one exchange and one queue and one outgoing channel will be received in the same order that they were sent. – RabbitMQ Broker Semantics
it is still possible for individual consumers to observe messages out of order if the queue has multiple subscribers. This is due to the actions of other subscribers who may requeue messages. – RabbitMQ Broker Semantics
Differently put, as long as we have a single message consumer, it receives messages in order. However, once we have multiple consumers reading messages from the same queue, we have no guarantee regarding the processing order of messages.
This lack of ordering guarantee happens because consumers might return (or redeliver) messages to the queue after reading them (e.g., in the case of processing failure).
Once a message is returned, another consumer can pick it up for processing even if it has already consumed a later message. Thus, consumer groups process messages out-of-order, as can be seen in the following diagram.
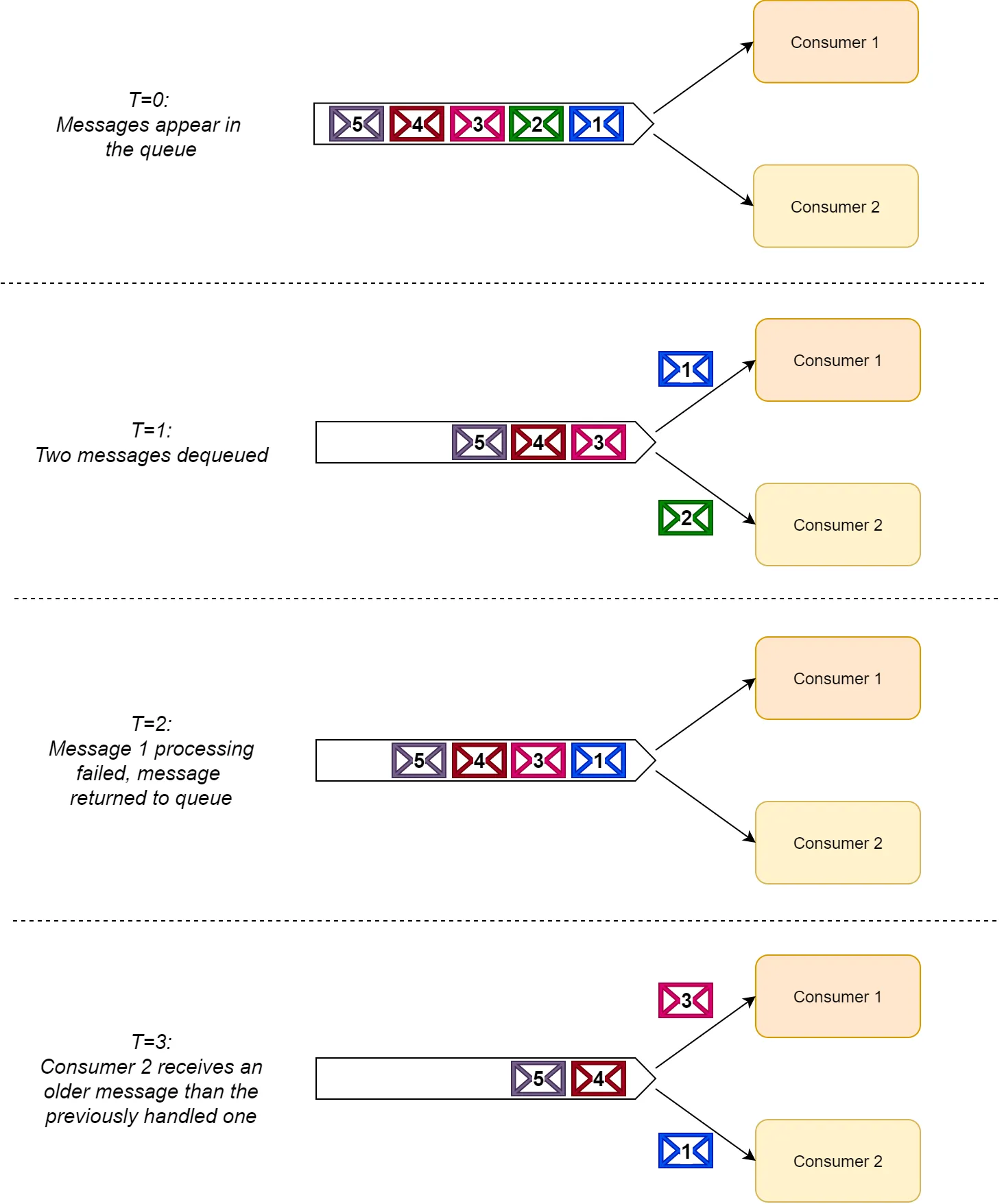 |
|---|
| An example of lost message ordering when using RabbitMQ |
Of course, we could regain message ordering in RabbitMQ by limiting consumer concurrency to one. More precisely, the thread count within the single consumer should be limited to one since any parallel message processing can cause the same out-of-order issue.
However, limiting ourselves to one single-threaded consumer severely impacts our ability to scale message processing as our system grows. As a result, we should not light-heartedly perform this tradeoff.
Kafka, on the other hand, provides a reliable ordering guarantee on message processing. Kafka guarantees that all messages sent to the same topic partition are processed in-order.
If you recall from Part 1, by default, Kafka places messages in partitions with a round-robin partitioner. However, a producer can set a partition key on each message to create logical streams of data (such as messages from the same device, or message belonging to the same tenant).
All messages from the same stream are then placed within the same partition, causing them to be processed in-order by consumer groups.
We should note, however, that within a consumer group, each partition is processed by a single thread of a single consumer. As a result, we cannot scale the processing of a single partition.
However, in Kafka, we can scale the number of partitions within a topic, causing each partition to receive fewer messages and add additional consumers for the additional partitions.
Winner
Kafka is the clear winner as it allows processing messages in order. RabbitMQ only has weak guarantees in this regard.
Message routing #
RabbitMQ can route messages to subscribers of a message exchange based on subscriber-defined routing rules. A topic exchange can route messages based on a dedicated header named routing_key.
Alternatively, a headers exchange can route messages based on arbitrary message headers. Both exchanges effectively allow consumers to specify the type of messages they are interested in receiving, thus providing solution architects with great flexibility.
Kafka, on the other hand, does not allow consumers to filter messages in a topic before polling them. A subscribed consumer receives all messages in a partition without exception.
As a developer, you could use a Kafka stream job, which reads messages from the topic, filters them, and pushes them to another topic to which a consumer can subscribe. Nonetheless, this requires more effort and maintenance and has more moving parts.
Winner
RabbitMQ provides superior support when it comes to routing and filtering messages for consumers to use.
Message timing #
RabbitMQ provides various capabilities in regards to timing a message sent to a queue:
Message Time-To-Live (TTL)
A TTL attribute can be associated with each message sent to RabbitMQ. Setting the TTL is done either directly by the publisher, or as a policy on the queue itself.
Specifying a TTL allows the system to limit the validity period of the message. If a consumer does not process it in due time, then it is automatically removed from the queue (and transferred to a dead-letter exchange, but more on that later).
TTL is especially useful for time-sensitive commands that become irrelevant after some time has passed without processing.
Delayed/scheduled messages
RabbitMQ supports delayed/scheduled messages via the use of a plugin. When this plugin is enabled on a message exchange, a producer can send a message to RabbitMQ, and the producer can delay the time in which RabbitMQ routes this message to a consumer’s queue.
This feature allows a developer to schedule future commands, which are not meant to be handled before then. E.g., when a producer hits a throttling rule, we might want to delay the execution of specific commands to a later time.
Kafka provides no support for such features. It writes messages to partitions as they arrive, where they are immediately available for consumers to consume.
Also, Kafka provides no TTL mechanism for messages, although we could implement one at the application level.
We must also remember that a Kafka partition is an append-only transaction log. As a result, it cannot manipulate the message time (or location within the partition).
Winner
RabbitMQ wins this hands-down, as the nature of its implementation limits Kafka.
Message retention #
RabbitMQ evicts messages from storage as soon as consumers successfully consume them. This behavior cannot be modified. It is part of almost all message brokers’ design.
In contrast, Kafka persists all messages by design up to a configured timeout per topic. In regards to message retention, Kafka does not care regarding the consumption status of its consumers as it acts as a message log.
Consumers can consume every message as much as they want, and they can travel back and forth “in time” by manipulating their partition offset. Periodically, Kafka reviews the age of messages in topics and evicts those messages that are old enough.
Kafka’s performance is not dependant on storage size. So, in theory, one can store messages almost indefinitely without impacting performance (as long as your nodes are large enough to store these partitions).
Winner
Kafka is designed to retain messages, while RabbitMQ is not. There is no competition here, and Kafka is declared the winner.
Fault handling #
When dealing with messages, queues, and events, developers are often under the impression that message processing always succeeds. After all, since producers place each message in a queue or topic, even if a consumer fails to process a message, it can simply retry until it succeeds.
While this is true on the surface, we should put additional thought into this process. We should acknowledge that message processing can fail in some scenarios. We should gracefully handle these situations, even if the solution is partly composed of human intervention.
There are two types of possible errors when processing messages:
-
Transient failures — Failures that occur due to a temporary issue such as network connectivity, CPU load, or a service crash. We can usually mitigate this kind of failure by retrying over and over again.
-
Persistent failures — Failures that occur due to a permanent issue that cannot be resolved via additional retries. Common causes of these failures are software bugs or an invalid message schema (i.e., a poison message).
As architects and developers, we should ask ourselves: “How many times should we retry upon a message processing failure? How long should we wait between retries? How do we distinguish between transient and persistent failures?”
And most importantly: “What do we do when all retries fail, or we encounter a persistent failure?”
While the answers to these questions are domain-specific, messaging platforms typically provide us with the tools to implement our solution.
RabbitMQ provides tools such as delivery retries and dead-letter exchanges (DLX) to handle message processing failures.
The main idea of a DLX is that RabbitMQ can automatically route failed messages to a DLX based on an appropriate configuration, and apply further processing rules on the message at this exchange, including delayed retries, retry counts, and delivery to a “human intervention” queue.
This article provides additional insights on possible patterns for handling retries in RabbitMQ.
The most important thing to remember here is that in RabbitMQ, when a consumer is busy processing and retrying a specific message (even before returning it to the queue), other consumers can concurrently process the messages that follow it.
Message processing as a whole is not stuck while a specific consumer retries a specific message. As a result, a message consumer can synchronously retry a message for as much as it wants without affecting the entire system.
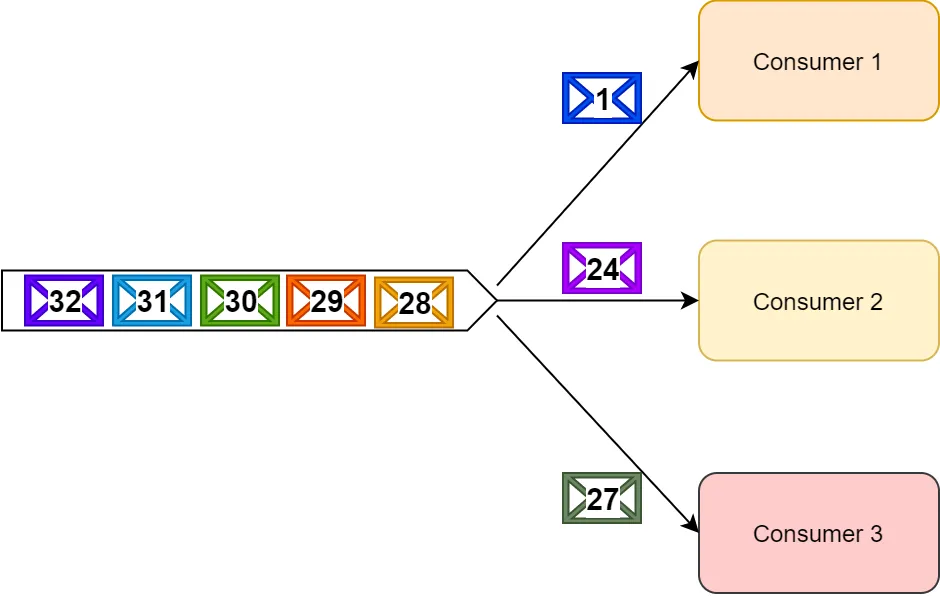 |
|---|
| Consumer 1 can continue retries on message 1, while other consumers continue processing messages |
Contrary to RabbitMQ, Kafka does not provide any such mechanisms out of the box. With Kafka, it is up to us to provide and implement message retry mechanisms at the application level.
Also, we should note that when a consumer is busy synchronously retrying a specific message, other messages from the same partition cannot be processed.
We cannot reject and retry a specific message and commit a message that came after it since the consumer cannot change the message order. As you remember, the partition is merely an append-only log.
An application-level solution can commit failed messages to a “retry topic” and handle retries from there; however, we lose message ordering in this type of solution.
An example of such an implementation by Uber Engineering can be found on Uber.com. If message processing latency is not an issue, then the vanilla Kafka solution with adequate monitoring for errors might suffice.
|
|---|
| Messages in the bottom partition are not handled if the consumer is stuck retrying a message |
Winner
RabbitMQ is a winner on points since it provides a mechanism to solve this problem out of the box.
Scale #
There are multiple benchmarks out there, checking the performance of RabbitMQ and Kafka.
While generic benchmarks have limited applicability towards specific cases, Kafka is generally considered to have better performance than RabbitMQ. Kafka uses sequential disk I/O to boost performance.
Its architecture using partitions means it scales better horizontally (scale-out) than RabbitMQ, which scales better vertically (scale-up).
Large Kafka deployments can commonly handle hundreds of thousands of messages per second, and even millions of messages per second.
In the past, Pivotal recorded a RabbitMQ cluster handling one million messages per second; however, it did this on a 30-node cluster with load optimally spread across multiple queues and exchanges.
Typical RabbitMQ deployments include three to seven node clusters that do not necessarily optimally divide the load between queues. These typical clusters can usually expect to handle a load of several tens of thousands of messages per second.
Winner
While both platforms can handle massive loads, Kafka typically scales better and can achieve higher throughput than RabbitMQ and thus wins this round.
It is important to note, however, that most systems do not ever reach any of these limitations! So, unless you’re building the next millions-of-users smash-hit software system, you don’t need to care about scale so much, as both platforms can serve you well.
Consumer complexity #
RabbitMQ uses a smart-broker and dumb-consumer approach. Consumers register to consume queues, and RabbitMQ pushes them with messages to process as they come in. RabbitMQ also has a pull API; however, it is much less-used.
RabbitMQ manages the distribution of messages to consumers and the removal of messages from queues (possibly to DLXs). The consumer does not need to worry about any of this.
RabbitMQ’s structure also means that a queue’s consumer group can efficiently scale from just one consumer to multiple consumers when the load increases, without any changes to the system.
|
|---|
| RabbitMQ consumers efficiently scale-up and scale-down |
Kafka, on the other hand, uses a dumb-broker and smart-consumer approach. Consumers in a consumer group need to coordinate leases on topic partitions between them (so that only one consumer in a consumer group listens to a specific partition).
Consumers also need to manage and store their partitions’ offset index. Fortunately, the Kafka SDK takes care of these for us, so we don’t need to manage it ourselves.
However, when we have a low load, a single consumer needs to process and keep track of multiple partitions in parallel, which requires more resources on the consumer side.
Also, as the load increases, we can only scale the consumer group up to the point where the number of consumers is equal to the number of partitions in the topic. Above that, we need to configure Kafka to add additional partitions.
However, as load decreases again, we cannot remove the partitions we already added, adding more to the work consumers need to do. Albeit, as mentioned above, the SDK handles this extra work.
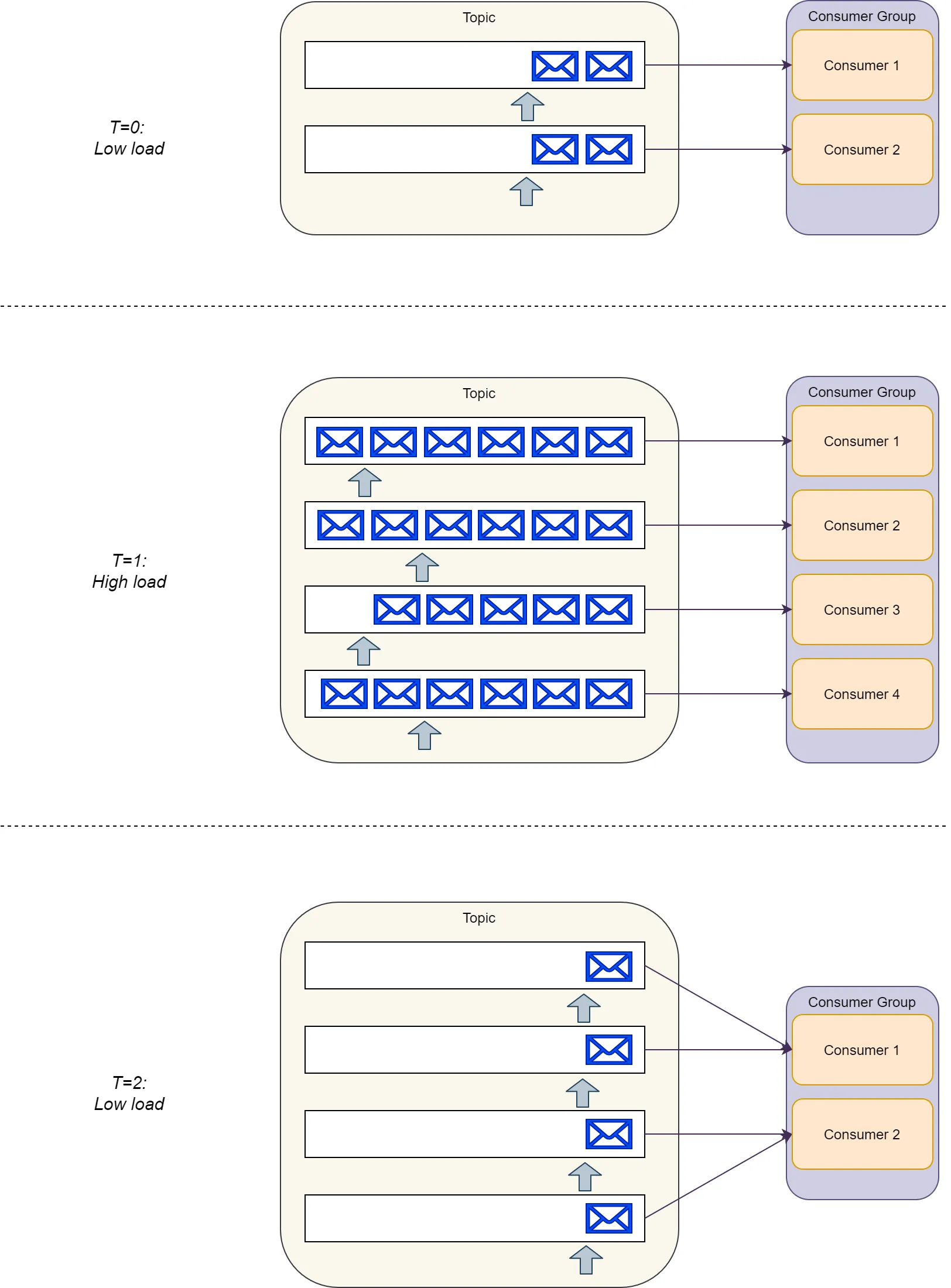 |
|---|
| Kafka partitions cannot be removed, leaving consumers with more work after scaling down |
Winner
RabbitMQ, by design, is built for dumb-consumers in mind. As a result, it is the winner of this round.
When to Use Which? #
Now we’re at the million-dollar question: “When should we use RabbitMQ, and when should we use Kafka?”
If we summarize the above differences, we arrive at the following conclusion:
RabbitMQ is preferable when we need:
- Advanced and flexible routing rules.
- Message timing control (controlling either message expiry or message delay).
- Advanced fault handling capabilities, in cases when consumers are more likely to fail to process messages (either temporarily or permanently).
- Simpler consumer implementations.
Kafka is preferable when we require:
- Strict message ordering.
- Message retention for extended periods, including the possibility of replaying past messages.
- The ability to reach a high scale when traditional solutions do not suffice.
We can implement most use cases using both platforms. However, it is up to us as solution architects to choose the most suitable tool for the job. When making this choice, we should take into consideration both functional differences, as highlighted above, and non-functional constraints below.
These constraints include things such as:
- Existing developer knowledge of these platforms.
- Availability of a managed cloud solution if applicable.
- The operational cost of each solution.
- Availability of SDKs for our target stack.
When developing complex software systems, we might be tempted to implement all required messaging use cases using the same platform. Nevertheless, from my experience, more often than not, using both platforms can have many benefits.
For example, in an event-driven architecture-based system, we could use RabbitMQ to send commands between services and use Kafka to implement business event notifications.
The reason for this is that event notifications are often used for event sourcing, batch operations (ETL style), or required for audit purposes, thus making Kafka very valuable for its message retention capabilities.
Commands, on the other hand, typically require additional processing on the consumer side, processing that could fail and require advanced fault handling capabilities.
Closing Thoughts #
This two-post series with the observation that many developers view RabbitMQ and Kafka as interchangeable. I hope that reviewing these posts assisted in gaining insight into these platforms’ implementation, and the technical differences between them.
The differences, in turn, affect the use-cases that these platforms serve well. Both platforms are great and can serve multiple use cases.
However, as solution architects, it is up to us to understand each use case’s requirements, prioritize them, and choose the most suitable solution.
Reference #
- https://www.rabbitmq.com/confirms.html
- https://www.rabbitmq.com/consumers.html#fetching
- https://www.rabbitmq.com/consumers.html#consuming
- https://www.rabbitmq.com/quorum-queues.html
- https://www.simplilearn.com/kafka-vs-rabbitmq-article
- https://www.interviewbit.com/blog/rabbitmq-vs-kafka/
- https://cloud.ibm.com/docs/EventStreams?topic=EventStreams-ES_understanding_reserved_disk_usage
- https://blog.ippon.tech/event-driven-architecture-getting-started-with-kafka-part-1/
- https://betterprogramming.pub/rabbitmq-vs-kafka-1ef22a041793
- https://betterprogramming.pub/rabbitmq-vs-kafka-1779b5b70c41