Programming paradigms #
A censorship circumvention tool may be required to open the links in this post from mainland of china.
A learning note for Clean Architecture Part II.
Introduction #
Paradigms are ways of programming, relatively unrelated to languages. A paradigm tells you which programming structures to use, and when to use them. To date, there have been three such paradigms, and it’s unlikely to be any other.
The three paradigms are structured programming, object-orient programming, and functional programming.
- Structured programming imposes discipline on direct transfer of control, i.e., disciplined
gotostatement. - Object-oriented programming imposes discipline on indirect transfer of control, i.e., disciplined use of function pointers(the foundation of polymorphism).
- Functional programming imposes discipline upon assignment. The notion of immutability and disciplined value modification.
Each of the paradigms removes capabilities from the programmer. None of them adds new capabilities. Each imposes some kind of extra discipline that is negative in its intent. The paradigms tell us what not to do, more than what to do.
What does this history lesson on paradigms have to do with architecture? Everything. We use polymorphism as the mechanism to cross architectural boundaries; we use functional programming to impose discipline on the location of and access to data; and we use structured programming as the algorithmic foundation of our modules.
Notice how well those three align with the three big concerns of architecture: function, separation of components, and data management.
Structured Programming #
In the early days of programming, code was typically written in an unstructured manner, with programs consisting of a series of “go to” statements that could jump to any other point in the program’s execution. This made it difficult to read, understand, and modify code, and it was also prone to errors and bugs.
Movement and discovery #
Böhm and Jacopini proved in 1966 that all programs can be constructed from just three structures: sequence, selection, and iteration. Their paper, Flow Diagrams, Turing Machines, and Languages with Only Two Formation Rules was published in the Communications of the ACM journal in April 1966.
Dijkstra believed that programming was essentially a mathematical activity and that the key to producing correct programs was to use rigorous mathematical reasoning to prove that they were correct. When he was trying to demonstrate the technique for writing basic proofs of simple algorithms, He discovered that certain uses of goto statements prevent modules from being decomposed recursively into smaller and smaller units, thereby preventing the use of the divide-and-conquer approach for reasonable proofs.
Other uses of goto, however, did not have this problem. Dijkstra realized that these “good” use of goto corresponded to simple selection and iteration control structures such as if/then/else and do/while. Modules that used only those kinds of control structures could be recursively subdivided into provable units.
Dijkstra knew that those control structures, when combined with sequential execution, were special. Combined with the work that Böhm and Jacopini proved that all programs can be constructed from just three structures: sequence, selection, and iteration.
This discovery was remarkable: The very control structures that made a module provable were the same minimum set of control structures from which all programs can be built. Thus structured programming was born.
Functional decomposition #
Structured programming allows modules to be recursively decomposed into provable units, which in turn means that modules can be functionally decomposed. That is, A large-scale problem statement can be decomposed into high-level functions. Each of those functions can then be decomposed into smaller, more specific functions, which can then be further broken down into even smaller functions, and so on, without limit. Moreover, each of those decomposed functions can be represented using the restricted control structures of structured programming.
Structured programming requires us to recursively decompose a program into a set of small provable functions. We can then use tests to try to prove those small provable functions incorrect. If such tests fail to prove incorrectness, then we deem the functions to be correct enough for our purpose.
Conclusion #
It is this ability to create falsifiable units of programming via decomposition approach that make structured programming valuable today. This is the reason that modern languages do not typically support unrestrained goto statements. Moreover, at the architectural level, this is why we still consider functional decomposition to be one of our best practices.
Object-oriented programming #
The basis of good architecture is the understanding and application of the principles of object-oriented design (OO), But just what is OO?
One answer to this question is “The combination of data and function.” Although often cited, this is a very unsatisfying answer because it implies that o.f() is somehow different from f(o). This is absurd. Programmers were passing data structures into functions long before 1966 when Dahl and Nygaard moved the function call stack frame to the heap and invented OO.
Some folks fall back on three magic words to explain the nature of OO: encapsulation, inheritance, and polymorphism. The implication is that OO is the proper admixture of these three things, or at least that OO language must support these three things.
Let’s go through each of these concepts in turn.
Encapsulation? #
This idea is certainly not unique to OO.
The reason encapsulation is cited as part of the definition of OO is that OO languages provide easy and effective encapsulation of data and functions. Outside of that line, the data is hidden and only some of the functioins are known. We see this concept in action as the private data members and the public functions of a class.
Again, This idea is certainly not unique to OO. Indeed, we had perfect encapsulation in C. Consider this simple C program:
point.h
-----------
struct Point;
struct Point* makePoint(double x, double y);
double distance (struct Point *p1, struct Point *p2);
point.c
-------------
#include "point.h"
#include <stdlib.h>
#include <math.h>
struct Point {
double x,y;
};
struct Point* makepoint(double x, double y) {
struct Point *p = malloc(sizeof(struct Poing));
p->x = x;
p->y = y;
return p;
}
double distance(struct Point* p1, struct Point* p2) {
double dx = p1->x - p2->x;
double dy = p1->y - p2->y;
return sqrt(dx*dx + dy*dy);
}
The users of point.h have no access whatsoever to the member of struct Point. Then can call the makePoint() function, and the distance() function, but they have absolutely no knowledge of the implication of either the Point data structure or the functions.
This is perfect encapsulation in a non-OO language. C programmers used to do this kind of thing all the time. We would forward declare data structures and functions in header files, and then implement them in implementation files. Our user never had access to the elements in those implementation files.
But the came OO in the form of C++, the perfect encapsulation of C was broken.
The C++ compiler, for technical reasons(e.g., C++ compiler need to to know the size of instances of a class), needed the member variables of a class to be declared in the header file of that class. So our Point program changed to look like this:
point.h
-------------
class Point {
public:
Point(double x, double y);
double distance(const Point& p) const;
private:
double x;
double y;
};
point.cc
------------
#include "point.h"
#include <math.h>
Point::Point(double x, double y): x(x), y(y){}
double Point::distance(const Point &p) const {
double dx = x - p.x;
double dy = y - py;
return sqrt(dx*dx - dy*dy);
}
Clients of the header file point.h know about the member variables x and y! The compiler will prevent access to them, but the client still knows they exist. For example, if those member names are changed, the point.cc file must be recompiled! Encapsulation has been broken.
Indeed, the way encapsulation is partially repaired is by introducing the public, private, and protected keywords into the language. This, however, was a hack necessitated by the technical need for the compiler to see those variables in the header file.
Java and Kotlin simply abolished the header/implementation split altogether, thereby weakening encapsulation even more. In these languages, it is impossible to separate the declaration and definition of a class.
For these reasons, it it difficult to accept that OO depends on strong encapsulation. Indeed, many OO languages have little or no enforced encapsulation.
OO certainly does depend on the idea that programmers are well-behaved enough to not circumvent encapsulated data. Even so, the languages that claim to provide OO have only weakened the once perfect encapsulation we enjoyed with C.
Inheritance? #
If OO languages did not give us better encapsulation, then they certainly gave us inheritance?
Well, soft of. Inheritance is simply the redeclaration of a group of variables and functions within an enclosing scope. This is something C programmers were able to do manually long before there was an OO language.
Consider this addition to our original point.h c program:
namedPoint.h
---------------
struct NamedPoint;
struct NamedPoint* makeNamedPoint(double x, double y, char* name);
void setName(struct NamedPoing* np, char* name);
char* getName(struct NamedPoing* np);
namedPoint.cc
----------------
#include "namedPoint.h"
#include <stdlib.h>
struct NamedPoint {
double x, y;
char* name;
};
struct NamedPoint* makeNamedPoint(double x, double y, char* name)
{
struct NamedPoint* p = malloc(sizeof(struct NamedPoint));
p->x = x;
p->y = y;
p->name = name;
return p;
}
void setName(struct NamedPoint* np, char* name) {
np->name = name;
}
char* getName(struct NamedPoint* np) {
return np->name;
}
main.c
-----------
#include "point.h"
#include "namedPoint.h"
#include <stdio.h>
int main(int ac, char** av) {
struct NamedPoint* origin = makeNamedPoint(0.0, 0.0, "origin");
struct NamedPoint* upperRight = makeNamedPoint (1.0, 1.0, "upperRight");
printf("distance=%f\n",distance((struct Point*) origin,(struct Point*) upperRight));
}
If you look carefully at main program, you’ll see that the NamedPoint data structure acts as though it is a derivative of the Point data structure. This is because the order of the first two fields in the NamedPoint is a pure superset of Point and maintains the ordering of the members that correspond to Point.
This kind of trickery was a common practice of programmers prior to the advent of OO. In fact, such trckery is how C++ implements single inheritance.
Thus we might say that we had a kind of inheritance long before OO languages were unvented. That statement wouldn’t quite be true, though. We had a trick, but it’s not nearly as convenient as true inheritance. Moreover, multiple inheritances is considerably more difficult to achieve by such trickery.
Note also that in main.c, I was forced to cast the NamedPoint arguments to Point. In a real OO language, such upcasting would be implict.
It’s fair to say that while OO languages did not give us something completely brand new, it did make the masquerading of data structures significantly more convenient.
To recap: We can award no point to OO for encapsulation, and perhaps a half-point for inheritance. So far, that’s not such a great score.
But there’s one more attribute to consider.
Polymorphism #
Did we have polymorphic behavior before OO languages? Of course we did.
Consider this simple C copy program.
#include <stdio.h>
void copy() {
int c;
while((c = getchar()) != EOF)
putchar(c);
}
The function getchar() reads from STDIN. But which device is STDIN? The putchar() function writes to STDOUT. But which device is that? These functions are polymorphic – their behavior depends on the type of STDIN and STDOUT.
It’s as though STDIN and STDOUT and java-style interfaces that have implementations for each device. Of course, there are no interfaces in the example C program – so how does the call to getchar() actually get delivered to the device driver that reads the character?
The answer to that question is pretty straightforward. The UNIX operating system requires that every IO device driver provide five standard functions: open, close, read, write, and seek defined by FILE. The signatures of those functions must be identical for every IO driver.
This simple trick is the basis for all polymorphism in OO. In C++, for example, every virtual function within a class has a pointer in a table called vtable, and all calls to virtual functions go through that table. Constructors of derivatives simply load their versions of those functions into the vtable of the object being created.
The bottom line is that polymorphism is an appliction of pointers to functions. Programmers have been using pointers to functions to achieve polymorphic hehavior since Von Neumann architectures were first implemented in the late 1940s. In other words, OO has provided nothing new.
But that’s not quite correct. OO languages may ot give us polymorphism, but they have made it much faster and much more convenient.
The problem with explicitly using pointers to functions to create polymorphic behavior is that pointers to functions are dangerous. Such use is driven by a set of manual conventions. You have to remember to follow the convention to initialize those pointers. You have to remember to follow the convention to call all your functions through those pointers. If any programmer fails to remember these conventions, the resulting bug can be devilishly hard to track down and eliminate.
OO languages eliminate these conventions and, therefore, these dangers. Using an OO language makes polymorphism trivial. That fact provides an enormous power that old C programmers could only dream of. On this basis, we can conclude that OO imposes discipline on indirect transfer of control.
The Power of Polymorphism #
What’s so great about polymorphism? To better appreciate its charms, let’s reconsider the example copy grogram. What happens to that program if a new IO device is created? Suppose we want to use the copy program to copy data from a handwriting recognition device to a speech synthesizer device: How do we need to change the copy program to get it to work with those new devices?
We don’t need any change at all! Indeed, we don’t even need to recompile the copy program. Why? Because the source code of the copy program does depend on the source code of IO drivers. As long as those IO drivers implement the five standard functions defined by FILE, the copy program will be happy to use them.
In short, the IO devices have become plugins to the copy program, and the copy program become device independent.
The plugin architecture was invented to support this kind of IO device independence and has been implemented in almost every operating system since its introduction.
Even so, most programmers did not extend the idea to their own programs, because using pointers to functions was dangerous.
OO allows the plugin architecture to be used anywhere, for anything.
Dependency Inversion #
Imagine what software was like before a safe and convenient mechanism for polymophism was avaiable. In the tipical calling tree, man functions called high-level functions, which called mid-level functions, which called low-level functions. In that calling tree, however, source code dependencies inexorably followed the flow of control, shown in Figure 1.
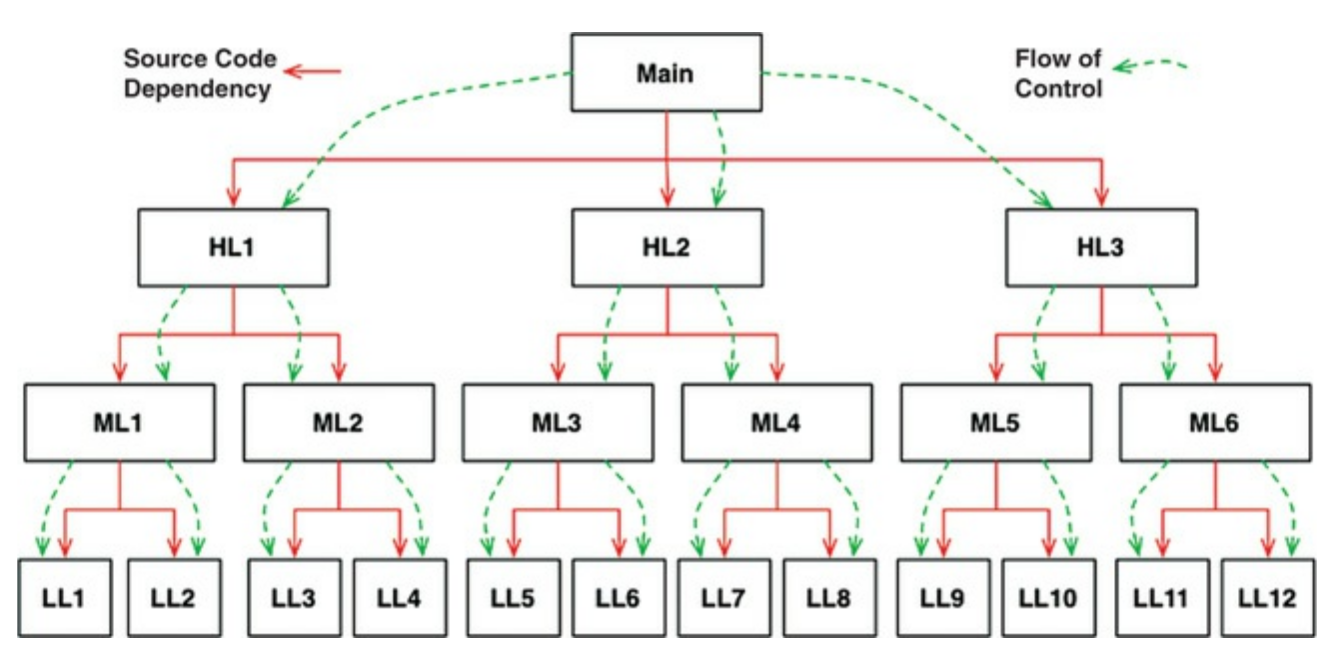 |
|---|
| Figure 1: Source code dependencies versus flow control |
For main to call one of the high-level functions, it had to mention the name of the module that contained that function. In C, this was a #include. In Java, it was an import statement. Indeed, every caller was forced to mention the name of the module that contained the callee.
This requirement presented the software architect with few, if any, options. The flow of control was dictated by the behavior of the system, and the source code dependencies were dictated by that flow of control.
When polymorphism is brought into play, however, something very different can happen, shown in Figure 2
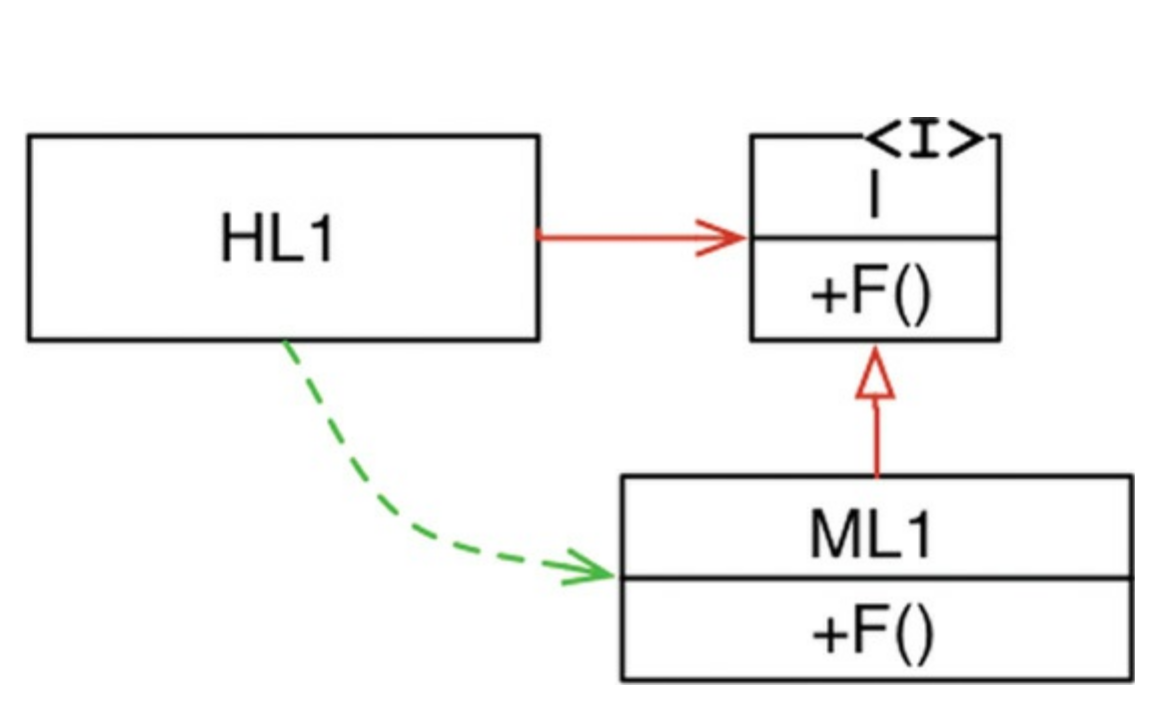 |
|---|
| Figure 2: Dependency Inversion |
In Figure 5.2, module HL1 calls the F() function in ML1. The fact that it calls this function through an interface is a source code contrivance. At runtime, the interface doesn’t exist. HL1 simply calls F() within ML1.
Note, however, that the source code dependency(the inheritance relationship) between ML1 and the interface I points in the oppsite direction compared to the flow of control. This is called dependency inversion, and its implications for the software architect are profound.
The fact that OO languages provide safe and convenient polymorphism means that any source code dependency, no matter where it is, can be inverted.
Now look back at that calling tree in Figure 1, and its many source code dependencies. Any of those source code dependencies can be turned around by inserting an interface between them.
With this approach, software architects working in systems written OO languages have absolute control over the direction of all source code dependencies in the system. They are not contrained to align those dependencies with the flow of control. No matter which moudle does the calling and which modules is called, the software architect can point the source code dependency in either direction.
This is power! That is the power that OO provides. That’s what OO is really all about.
Dependency inversion makes the components in the system can be evolved at different paces with proper dependency management by employing dependency inversion. This is called independent deployability.
Conclusion #
What is OO? There are many opinions and many answers to this question. To the software architect, however, the answer is clear: OO is the ability, through the use of polymorphism, to gain absolute control over every source code dependency in the system. It allows the architect to create a plugin architecture, in which modules that contain high-level policies are independent of modules that contain low-level details. The low-level details are relegated to plugin modules that can be deployed and developed independently from the modules that contain high-level policies.
To create concrete instances of the low-level modules that implement the interfaces defined by the high-level policies. This is typically done using a factory pattern or dependency injection framework, which allows the creation and wiring of objects to be centralized and managed in a controlled way. The high-level policies can then use these concrete instances without knowing their specific implementation details, allowing for greater flexibility and maintainability in the overall system.
Functional programming #
In many ways, the concepts of functional programming predate programming itself. This paradigm is strongly based on the lambda calculus invented by Alonzo Church in the 1930s.
Concepts #
A number of concepts and paradigms are specific to functional programming, and generalyy foreign to imperative programming(e.g., structured programming, object-oriented programming). However, programming languages offer cater to serval programming paradigms, so programmers using “mostly imperative” languages may have utilized some of these concepts.
First-class and Higher-order functions #
First-class functions are the functions that are treated as values that can be assigned to variables, passed as arguments to other functions, and returned as results from functions. This means that functions are considered to be first-class citizens in the language, just like other basic types such as integers, strings, and booleans.
Higher-order functions are functions that take other functions as arguments and/or return functions as their result. In other words, they are functions that operate on other functions.
While a language can have first-class functions without having higher-order functions (if it only allows functions to be assigned to variables but not passed as arguments or returned as results), it cannot have higher-order functions without having first-class functions (since it needs to treat functions as values in order to pass them around as arguments or return them as results).
Side effect #
An operation, function or expression is said to have a side effect if it modifies some state variable value(s) outside its local environment, which is to say if it has any observable effect other than its primary effect of returning a value to the invoker of the operation.
Example side effects include:
- Modifying a non-local variable,
- Modifying a static local variable,
- Modifying a mutable argument passed by reference,
- Performing I/O or calling other functions with side-effects.
Pure functions #
A pure function is a function that has the following properties:
- The function return values are identical for identical arguments (no variation with local static variables, non-local variables, mutable reference arguments or input streams), and
- The function has no side effects (no mutation of local static variables, non-local variables, mutable reference arguments or input/output streams).
Pure functions have no side effect(memory or I/O), This makes them useful for optimizing code. for example:
- A pure function called with arguments that have no side effects will always return the same result for that argument list, allowing for caching optimizations like memoization.
- Two pure expressions with no data dependency can be performed in parallel or in any order, as their evaluation is thread-safe.
- If a language disallows side-effects, compilers are free to reorder or combine expression evaluation using deforestation. To optimize pre-compiled libraries, some compilers provide keywords for programmers to mark external functions as pure.
Recursion #
In functional programming, looping is usually achieved through recursion, which invokes an operation until it reaches a base case. This may require maintaining a stack, making it less efficient than imperative loops. However, a form of recursion called tail recursion can be optimized by a compiler to the same code used to implement iteration in imperative languages.
Imperative vs. functional programming #
Functional programming is very different from imperative programming. The most significant differences stem from the fact that functional programming avoids side effects, which are used in imperative programming to implement state and I/O. Pure functional programming completely prevents side-effects and provides referential transparency.
Higher-order functions are rarely used in older imperative programming. A traditional imperative program might use a loop to traverse and modify a list. A functional program, on the other hand, would probably use a higher-order “map” function that takes a function and a list, generating and returning a new list by applying the function to each list item.
The following two examples (written in JavaScript) achieve the same effect: they multiply all even numbers in an array by 10 and add them all, storing the final sum in the variable “result”.
Traditional Imperative Loop
const numList = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
let result = 0;
for (let i = 0; i < numList.length; i++) {
if (numList[i] % 2 === 0) {
result += numList[i] * 10;
}
}
Functional Programming with higher-order functions:
const result = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
.filter(n => n % 2 === 0)
.map(a => a * 10)
.reduce((a, b) => a + b);
Overall conclusions #
To summarize:
- Structured programming is discipline imposed upon direct transfer of control.
- Object-oriented programming is discipline imposed upon indirect transfer of control.
- Functional programming is discipline imposed upon side effects.
Each of these three paradigms has taken something away from us. Each restricts some aspect of the way we write code. None of them has added to our power or our capabilities.
With that realization, we can conclude: Software is not a rapidly advancing technology. the rules of software are the same today as they were in 1946 when Alan Turing wrote the very first code that would execute in an electronic computer. The tools have changed, and the hardware has changed, but the essence of software remains the same.
Software, the stuff of computer programs, is composed of sequence, selection, iteration, and indirection. Nothing more. Nothing less.