Modern Multi-Core Processor Basics #
A learning note for CMU 15-418/618 Lecture 1 and Lecture 2.
Introduction #
Nowdays, single-thread-of-control(single-instruction-stream-control) performance is improving very slowly, to run programs significantly faster, programs must utilize multiple processing elements, which means we need to know how to write parallel code. Writing parallel programs can be challenging, it requires problem partitioning, communication, and synchronization. The knowledge of machine characteristics is essential.
There are Four key concepts about how modern computers work
- Two concern parallel execution(Part 1)
- Two concern challenges of accessing memory(Part 2)
Understanding these architectural basics will help us
- Understand and optimize the performance of the parallel programs
- Gain intuition about what workloads might benefit from fast parallel machines.
Part 1: Parallel execution #
Two concern parallel execution
- Multi-core parallel execution basics
- SIMD processing basics
Example program #
Using this example throughout this lecture.
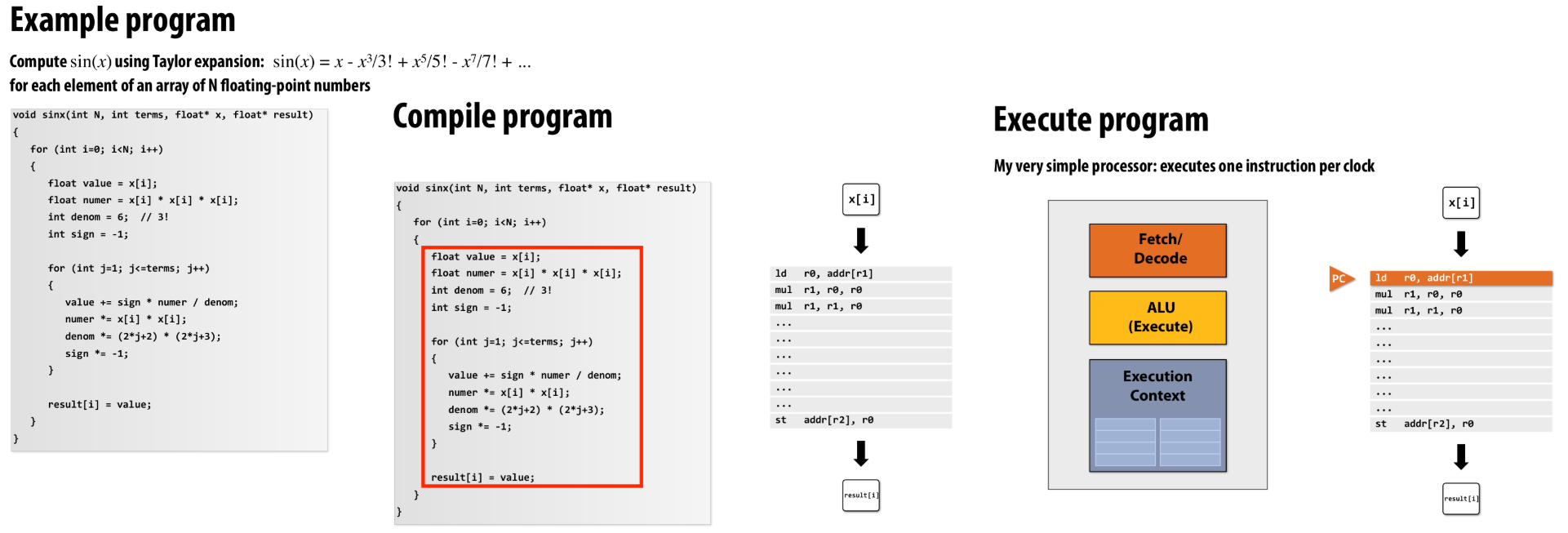 |
|---|
| Figure 0: Example program |
Superscalar processor #
Previously, we could increase the rate of running instructions, for example, by increasing clock frequency and running instructions in parallel(Instruction Level Parallelism, ILP).
All processors for a long period of time, if they were able to implement superscalar execution, actually they running instructions in parallel, A example of a superscalar processor is shown in Figure 1.
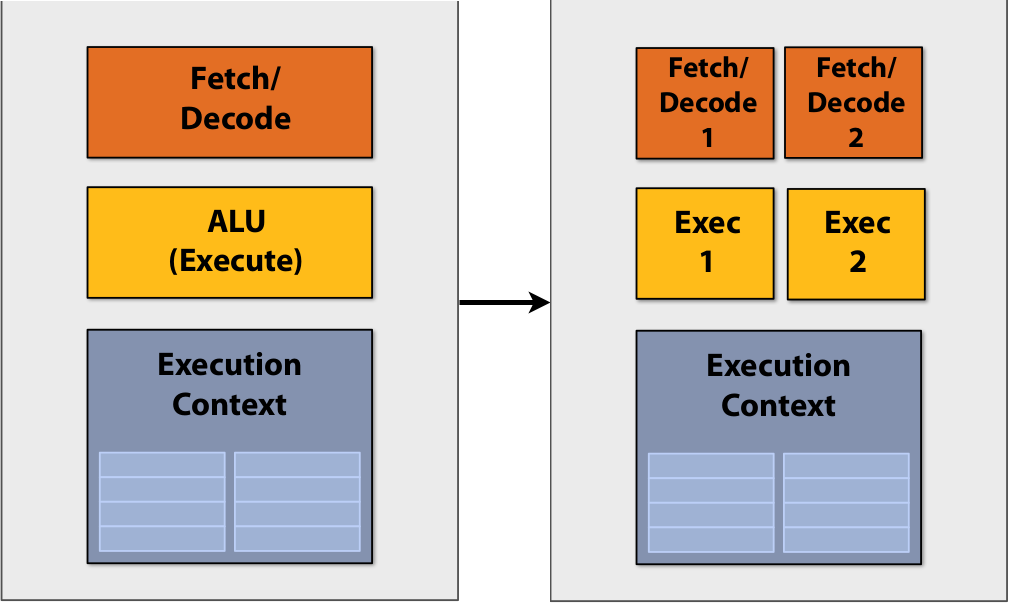 |
|---|
| Figure 1: Superscalar processor example |
Instead of having one Fetch/Decode unit and one ALU to execute one instruction per clock, the superscalar processor in this example can decode and execute two instructions per clock(if there are independent instructions that can be executed in parallel) within a single processor/core.
In Figure 2 shows a real word example of superscalar processor: Pentium 4
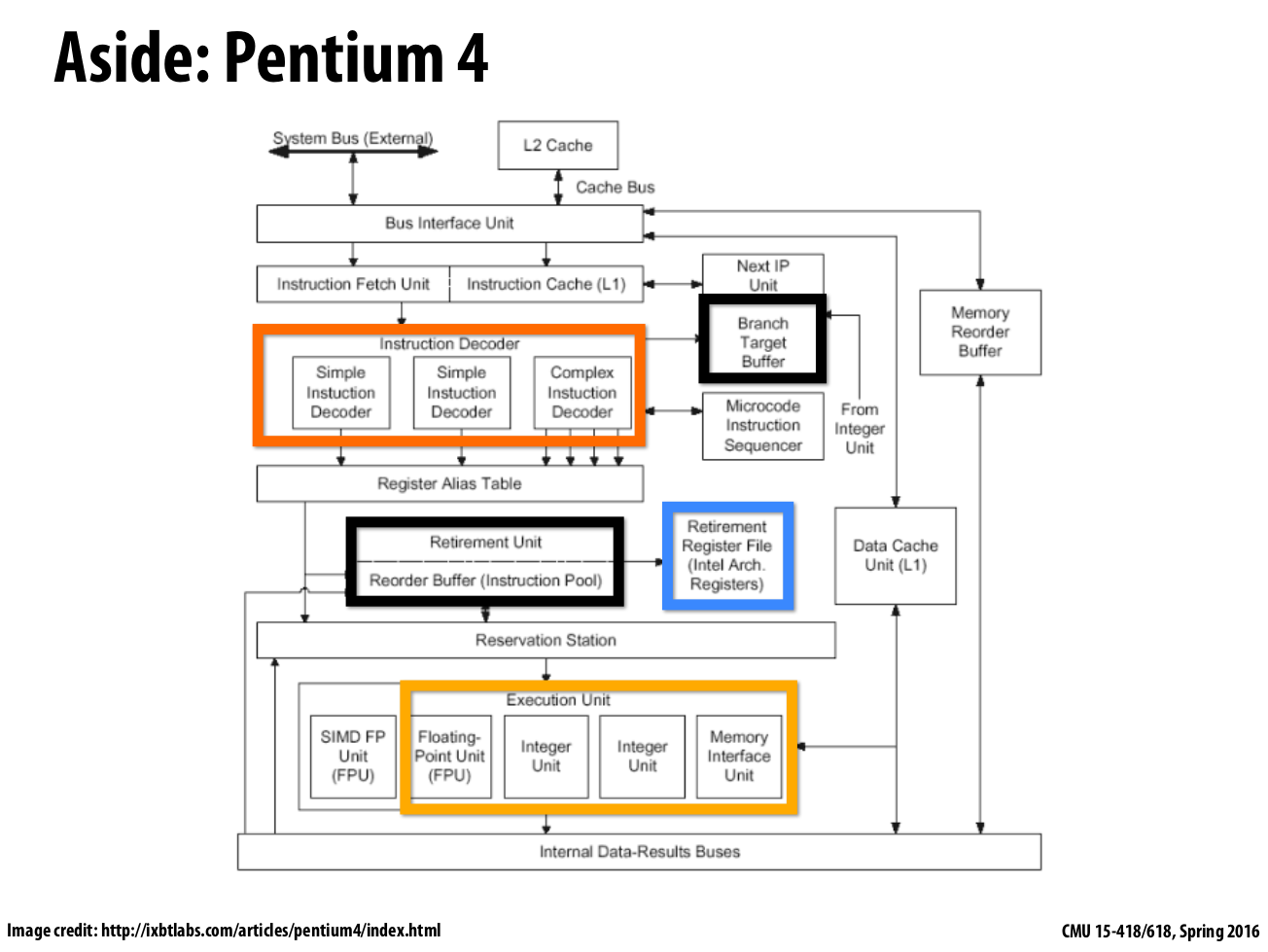 |
|---|
| Figure 2: pentium4 as a superscalar example |
In this old Pentium4 block diagram, they have three instruction decode units, a register file and then there are four different execution units(one for floating point, two for integers, and one for loads & stores), this Pentium4 can support up to three-way superscalar. reorder buffer and branch target buffer and a bunch of other stuff in this processor to manage the superscalar execution, the out-of-order execution, etc.
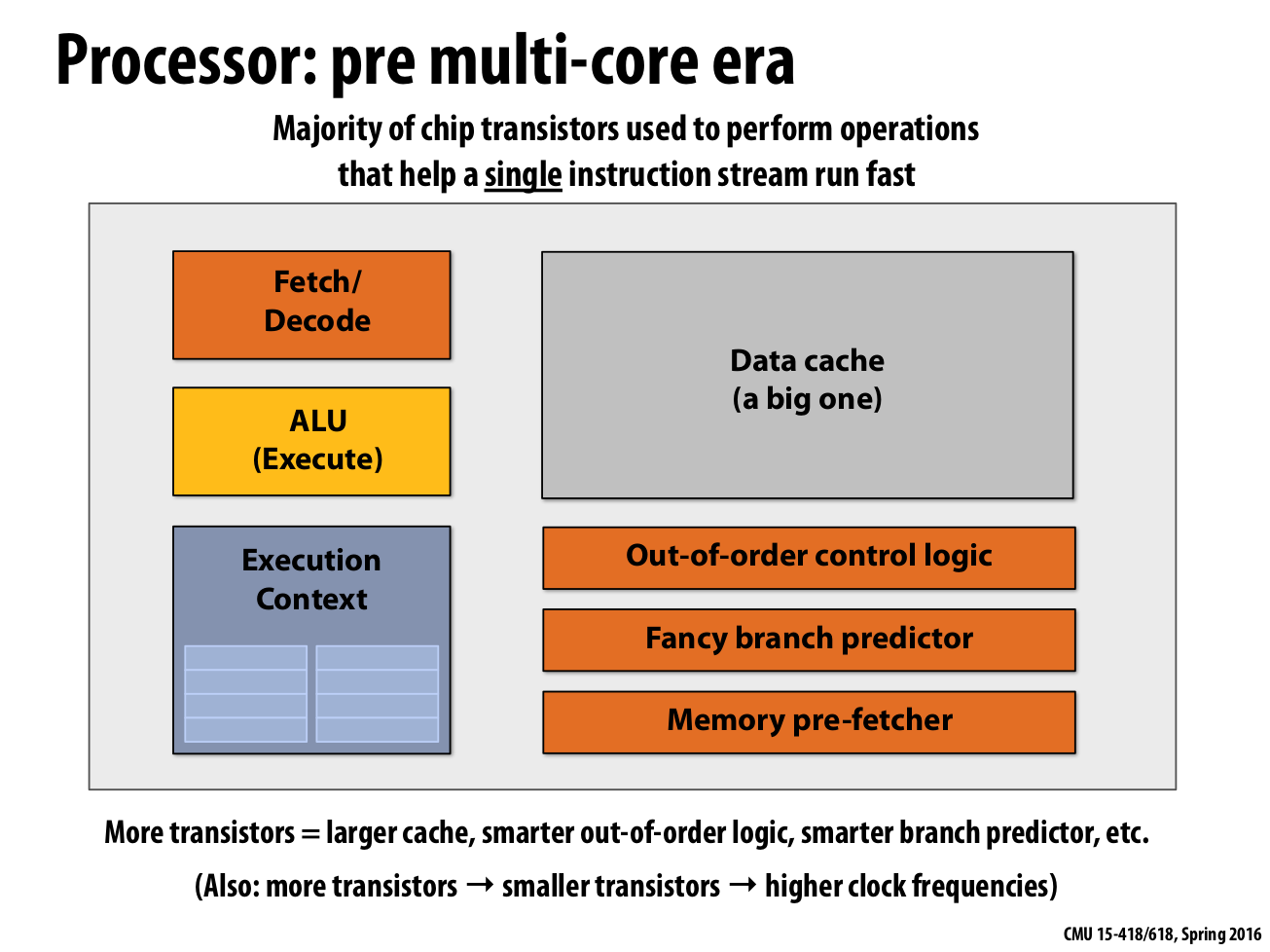 |
|---|
| Figure 3: superscalar processor with more components |
To build a fast superscalar processor, the majority of chip transistors are used to perform operations that help a single instruction stream run fast. Because the program is not written in parallel the processor is focused on automatically helping the developer by adding all the smarts to the processor if Moores’s Law gets more transistors, that means a better & fancier branch predictor.
However, the single-core performance scaling has decreased(almost to zero), because
- Frequency scaling limited by power
- ILP scaling tapped out. Because the program that is not written in parallel itself limits the dependence., although we can build smarter and smarter single-core processor to figure out independent instructions and execute them in parallel,
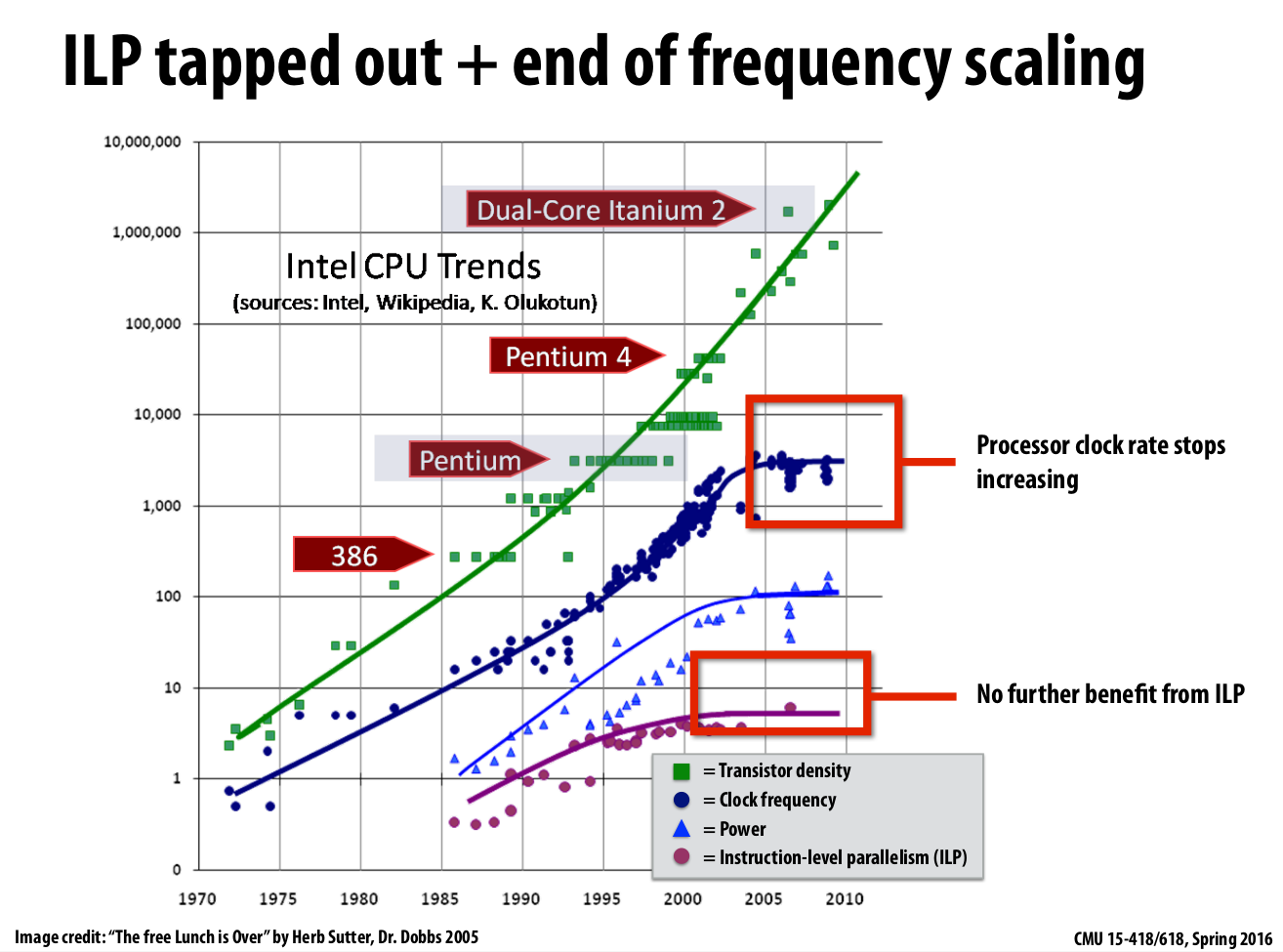 |
|---|
| Figure 4: Single-core performance scaling issue |
In order to keep the programmer from thinking about parallelism is a really hard way to make things run faster.
Architects are now building faster processors by adding more execution units that run in parallel.
Software must be written to be parallel to see performance gains. No more free lunch for software developers!
Processor: multi-core era #
The Idea #1 in parallel execution(Part 1) is: Use increasing transistor count to add more cores to the processor, rather than use transistors to increase the sophistication of processor logic that accelerates a single instruction stream(e.g., out-of-order and speculative operations)
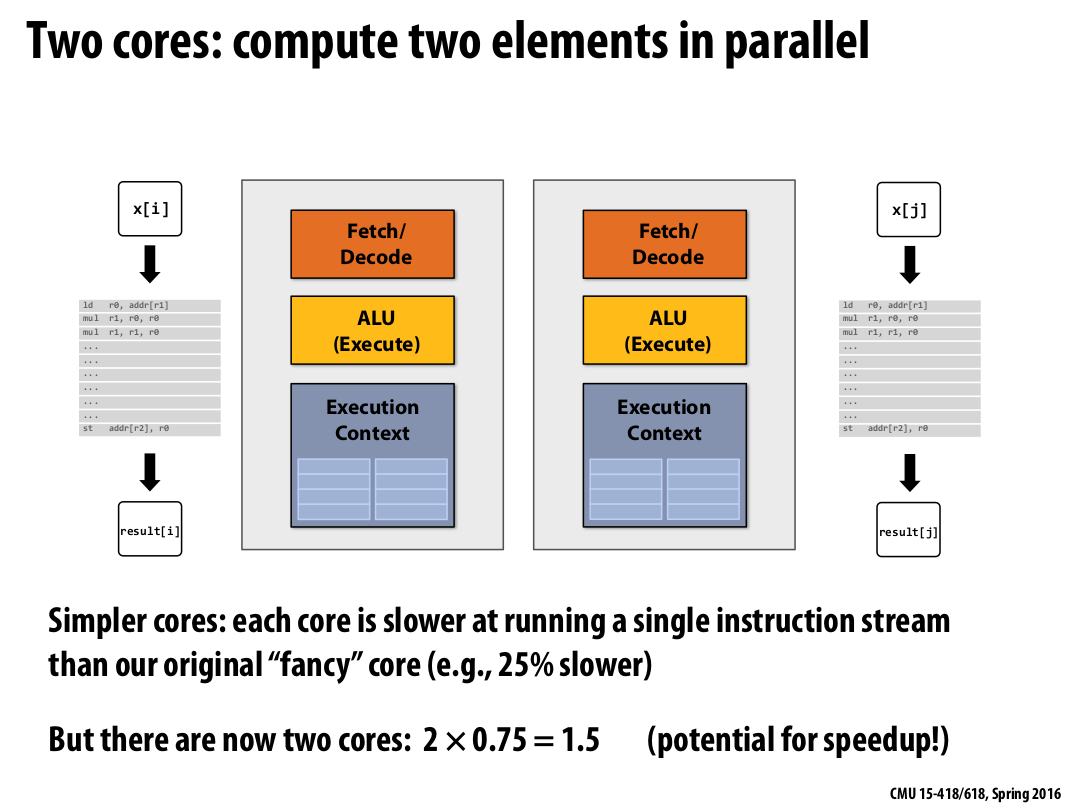 |
|---|
| Figure 5: Two cores: compute two elements in parallel |
But our example program expresses no parallelism. we can rewrite it with pthreads.
 |
|---|
| Figure 6: example program with pthreads |
In this example, we spawn two pthreads and each thread computes half of the array. As the number of cores changes, it will not scale. So we make a fictitious abstraction data-parallel language to abstract away the implementation details of this program but focus on the parallel execution bit.
 |
|---|
| Figure 7: example with fictitious abstraction |
With the fictitious example above, we can imagine the parallel execution scales as shown in Figure 8.
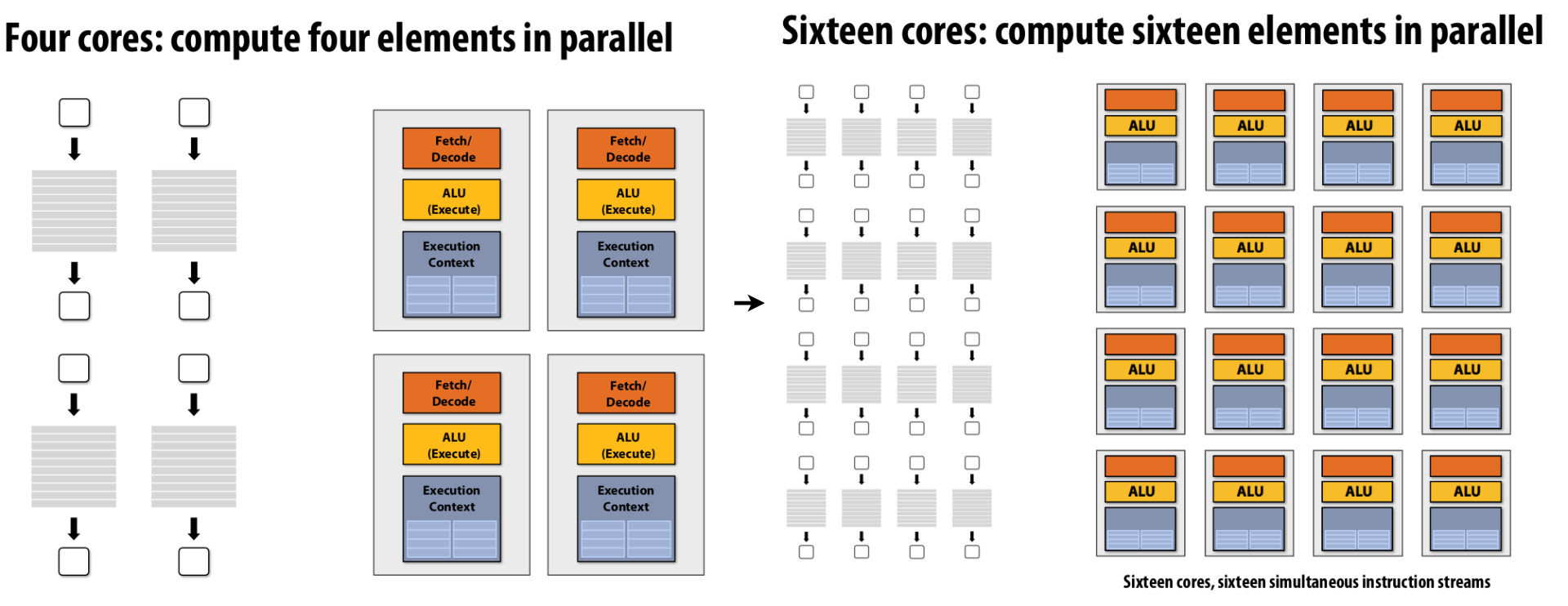 |
|---|
| Figure 8: parallel execution scale |
SIMD execution #
Another interesting property of the code in Figure 7 above is that the Parallelism is across iterations of the loop. All the iterations of the loop do the same thing: evaluate the sine of a single input number.
This introdued the Idea #2: Amortize cost/complexity of managing an instruction stream across many ALUs. The SIMD(Single Instruction, Multiple Data) processing.
Example of SIMD execution basics #
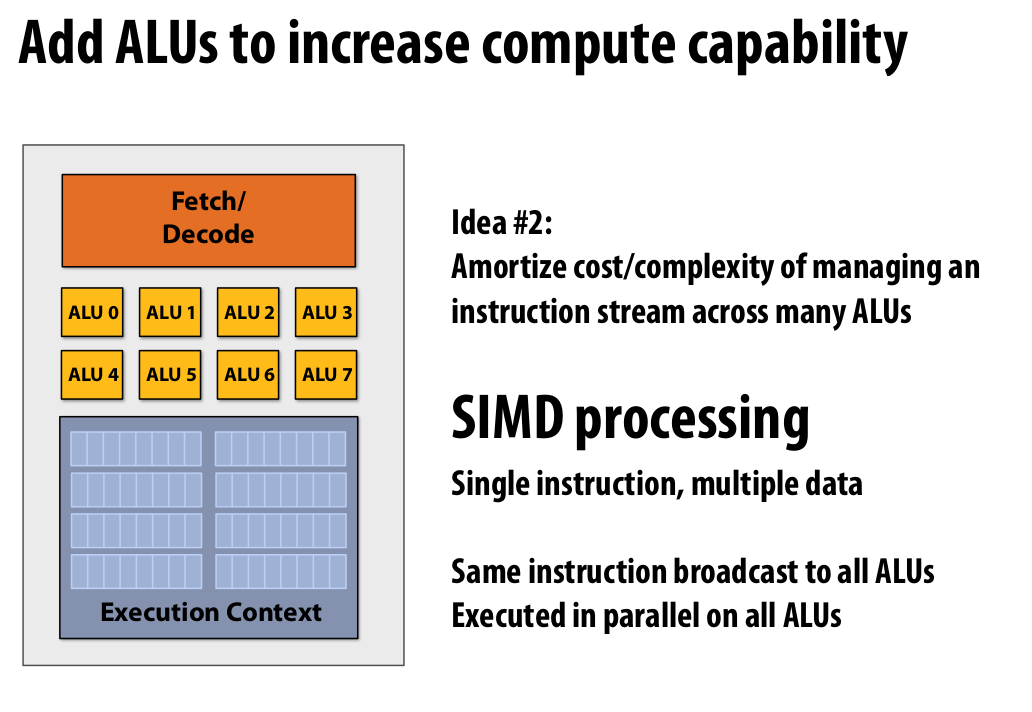 |
|---|
| Figure 9: Idea #2: Add ALUs to increase compute capability |
Here is a example with AVX instructions shown in Figure 10:
 |
|---|
| Figure 10: Vectorize program |
Here is a combined parallel computation shown in Figure 11:
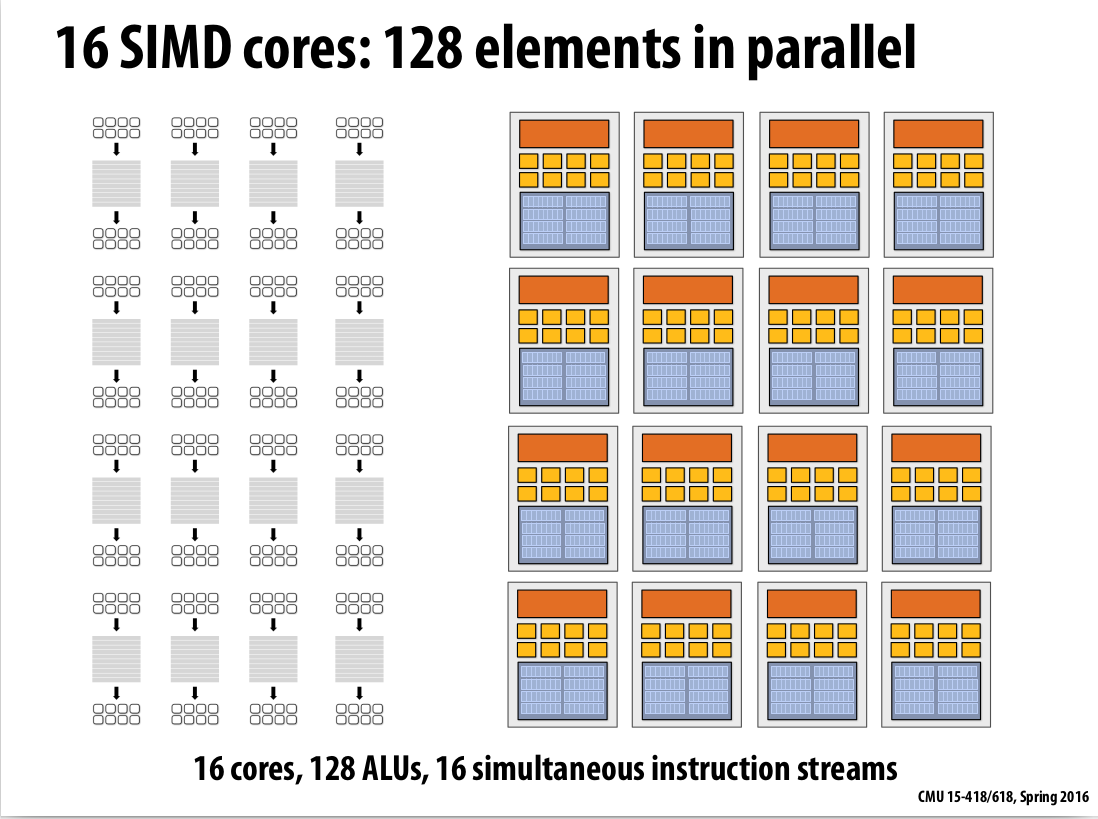 |
|---|
| Figure 11: Combined parallel computation |
Again, using code in Figure 7 above, Compiler understands loop iterations are independent, and that same loop body will be executed on a large number of data elements. The Abstraction could facilitates automatic generation of both multi-core parallel code, and vector instructions to make use of SIMD execution capabilities within a core.
What about conditional execution? #
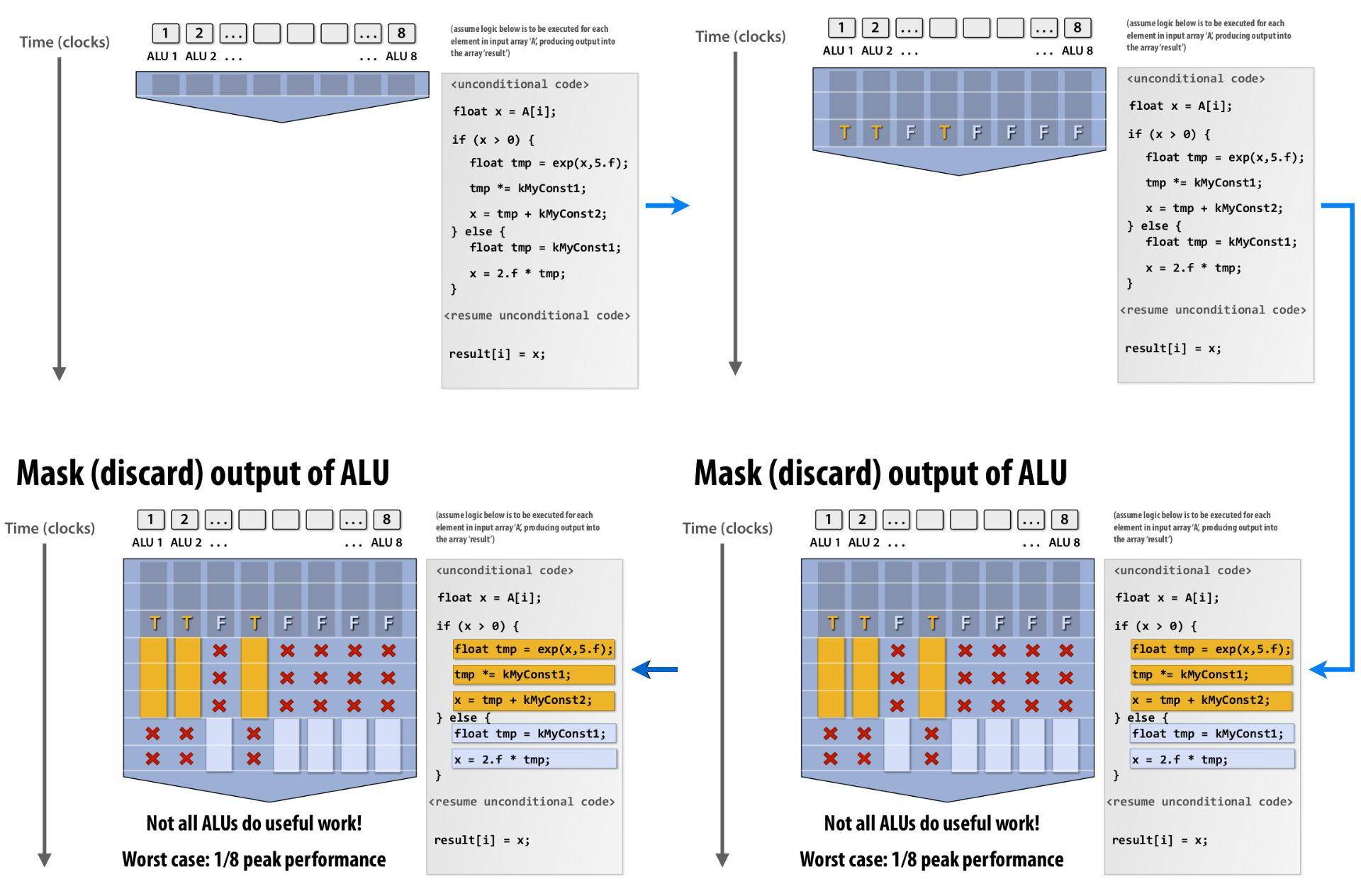 |
|---|
| Figure 12: SIMD conditional execution |
Terminology #
-
Instruction stream coherence (“coherent execution”)
- Same instruction sequence applies to all elements operated upon simultaneously
- Coherent execution is necessary for efficient use of SIMD processing resources
- Coherent execution IS NOT necessary for efficient parallelization across cores, since each core has the capability to fetch/decode a different instruction stream
-
“Divergent” execution
- A lack of instruction stream coherence
Note: don’t confuse instruction stream coherence with “cache coherence” (a major topic later in the course)
SIMD execution on modern CPUs #
- SSE instructions: 128-bit operations: 4x32 bits or 2x64 bits (4-wide float vectors)
- AVX instructions: 256 bit operations: 8x32 bits or 4x64 bits (8-wide float vectors)
- Instructions are generated by the compiler
- Parallelism explicitly requested by programmer using intrinsics
- Parallelism conveyed using parallel language semantics (e.g., forall example)
- Parallelism inferred by dependency analysis of loops (hard problem, even best compilers are not great on arbitrary C/C++ code)
- Terminology: “explicit SIMD”: SIMD parallelization is performed at compile time
- Can inspect program binary and see instructions ( vstoreps , vmulps , etc.)
 |
|---|
| Figure 13: Interl Core i7 |
SIMD execution on many modern GPUs #
- “Implicit SIMD”
- Compiler generates a scalar binary (scalar instructions)
- But N instances of the program are always run together on the processor, i.e., execute(my_function, N) // execute my_function N times
- In other words, the interface to the hardware itself is data-parallel
- Hardware (not compiler) is responsible for simultaneously executing the same instruction from multiple instances on different data on SIMD ALUs
- SIMD width of most modern GPUs ranges from 8 to 32
- Divergence can be a big issue(poorly written code might execute at 1/32 the peak capability of the machine!)
 |
|---|
| Figure 14: Nvidia GTX 480 |
Summary: parallel execution #
There are several forms of parallel execution in modern processors.
Multi-core: use multiple processing cores #
- Provides thread-level parallelism: simultaneously execute a completely different instruction stream on each core
- Software decides when to create threads (e.g., via pthreads API)
SIMD: use multiple ALUs controlled by same instruction stream (within a core) #
- Efficient design for data-parallel workloads: control amortized over many ALUs
- Vectorization can be done by compiler (explicit SIMD) or at runtime by hardware
- [Lack of] dependencies is known prior to execution (usually declared by programmer, but can be inferred by loop analysis by advanced compiler)
Superscalar: exploit ILP within an instruction stream. #
- Process different instructions from the same instruction stream in parallel (within a core)
- Parallelism automatically and dynamically discovered by the hardware during execution (not programmer visible)
Part 2: Acessing memory #
Terminology #
Memory latency #
- The amount of time for a memory request(e.g., load, store) from a processor to be served by the memory system. In other words, the total time duration after a processor sends a load/store request until the processor gets the data/ack from memory.
- Example: 100 cyles, 100 nsec
Memory bandwidth #
- The rate at which the memory system can provide data to a processor.
- Example 20 GB/s
Imagine that the latency of me getting some milk from the store is the amount of time it takes me to go to the store and get back home. bandwidth is a rate, it’s the number of things that happen per second, so that could be bytes per second like 20GB/s, or it could be cars per second on a road.
Bandwidth, a measure of how much is happening per unit time, latency, a measure of how long something takes. If you want to increase the bandwidth of driving somewhere, you add more roads to a highway.If you want to decrease the latency of getting somewhere, You buy a sports car or you raise the speed limit.
Stalls #
A processor stalls when it cannot run the next instruction in an instruction stream because of a dependency on a previous instruction. Because memory access time is about 100’s of cycles, acessing memory is a major source of stalls. An example shown in Figure 15:
 |
|---|
| Figure 15: Memory stall example |
Cache to reduce latency #
To reduce the length of stalls(reduce latency), the cache was introduced. caches primarily exist in CPUs, primarily to reduce memory latency.
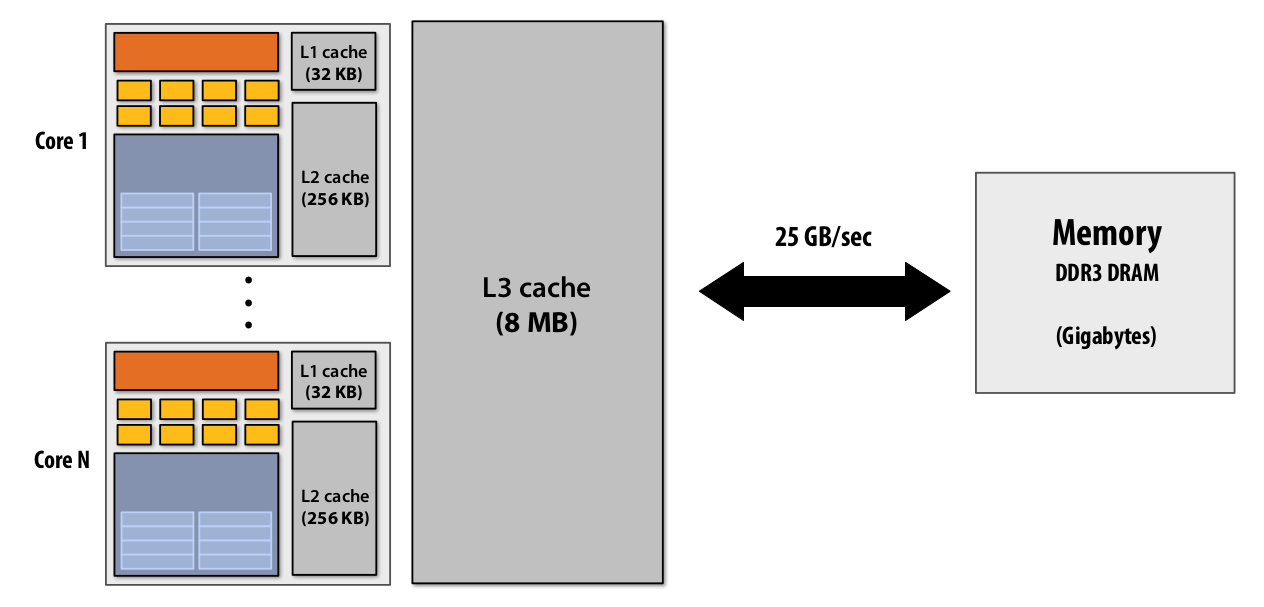 |
|---|
| Figure 16: cache example |
Additionally, because there might be a 25 gigabyte per second bus between main memory and the processor. But the rate at which and the line widths between the L1 and the processor are going to be much wider. caches also provide higher bandwidth to the CPU than main memory. In fact, increasing bandwidth can reduce latency as well, if we are not thinking about the latency of one operation, but thinking of the latency of many operations. So, Latency & bandwidth are correlated. But latency is a measure of how long it waits. Bandwidth is a measure of things that can get done per second. And how much they’re correlated kind of depends on whether or not we can overlap the requests.
Prefetching to hide latency #
All modern CPUs have logic for prefetching data into caches by dynamically analyze program’s access patterns and predict what it will access soon.
Pre-fetching hides latency. Because it still takes just as long to get the data from memory. But now CPU done it in advance, so that when you actually want it, it’s there.
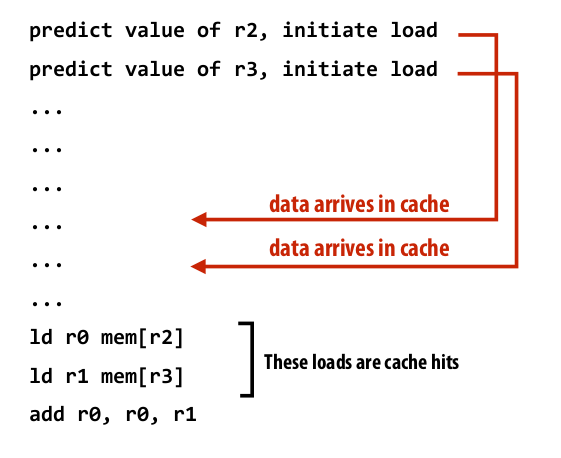 |
|---|
| Figure 17: prefetching example |
Note: Prefetching can also reduce performance if the guess is wrong (hogs bandwidth, pollutes caches)
Multi-threading reduces stalls #
By interleave processing of multiple threads on the same core, we can hide stalls further more, Just like prefetching, multi-threading is a latency hiding, not a latency reducing technique.
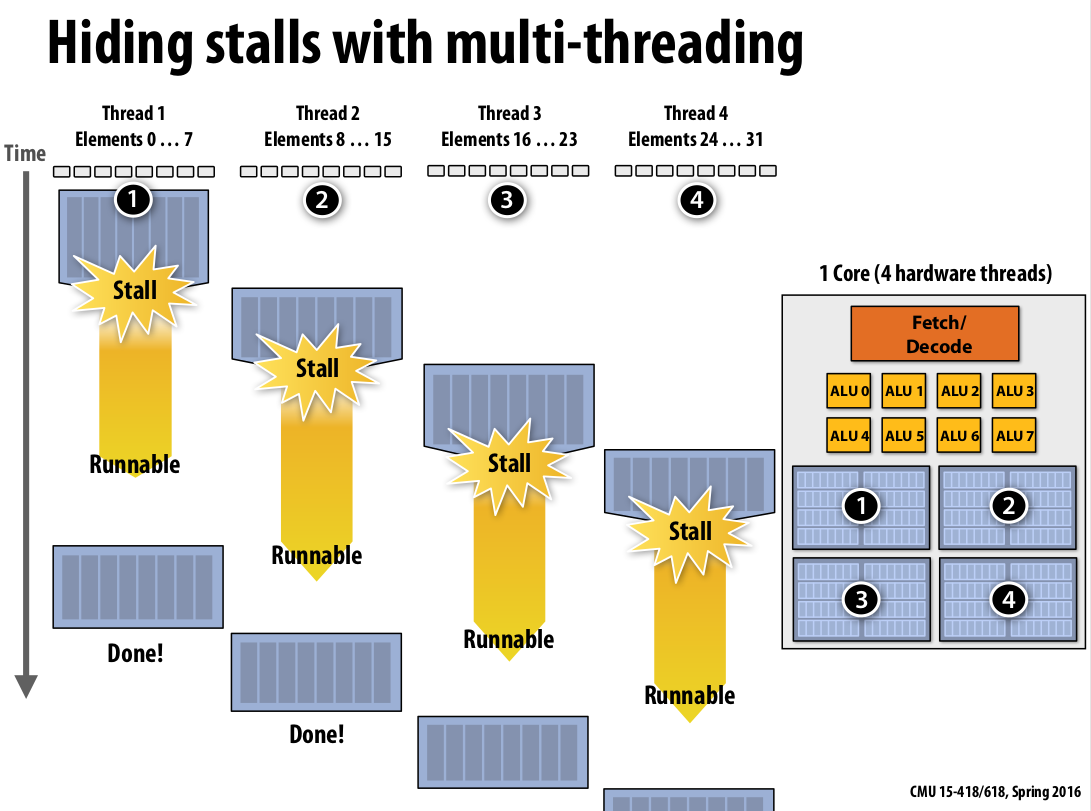 |
|---|
| Figure 18: multi-threading example |
By leverage multi-threading to reduce latency, it’s actually a throughput computing trade-off.
Because the latency of finishing the thread has increased, but the throughput of the machine has increased as well, because the processor has never wasted any time(It’s like every thread only has a quarter of the processor. But, the processor’s doing something useful at all times). So, if the goal here is to get done with four threads, this is a good design.
If the goal here is to get done with one thread quickly, we’ve lost performance. So, this is a key idea throughput-oriented systems.
 |
|---|
| Figure 19: throughput computing trade-off |
Note: The multi-threading here is managed by the hardware/chip itself. i.e., the threads here are hardware threads, during each clock cycle, the core is making decisions on which thread to run. Because the OS will give enough threads(4 threads in our example) to the core then the core itself should figure out when to run them.
Multi-threading in an operating system standpoint is to increase interactive performance, for example, in the case of disk IO where the multi-threading can hide hundreds of thousands of cycles and the OS can manage the switch.
Same idea in this hardware multi-threading technique, but it only hiding like 50 to 100 or a couple of hundreds of cycles. however if the operating system kicked in to handle the switch, it would be more expensive than just waiting for the memory system to come back.
Storing execution contexts #
Since there is only a fixed amount of storage for a context(or L1 cache and registers) on a chip, basically, there are two ways to divide those storage resources among the threads.
- Partition it into fewer big threads that have a lot of L1 and registers. Little latency-hiding ability but latency-reducing ability is better.
- Partition it into more threads that have very little L1 and registers. A lot of latency-hiding abilities but the latency-reducing ability is weak.
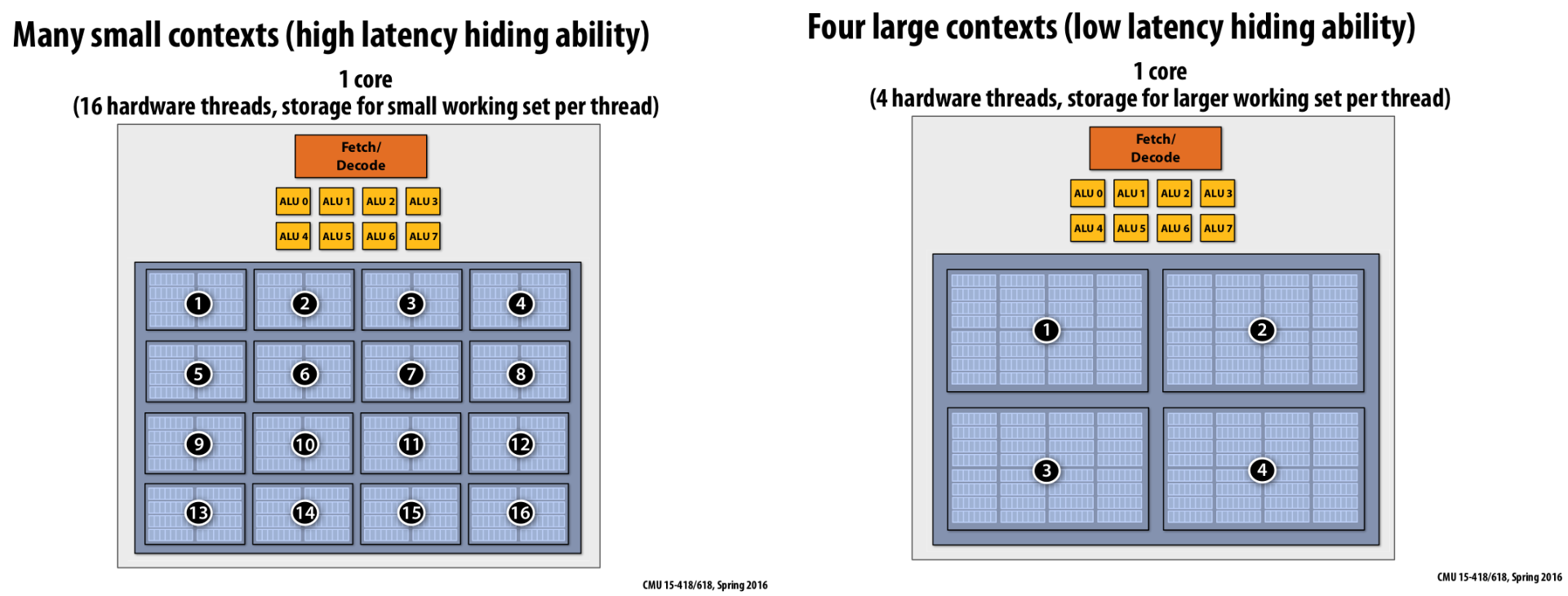 |
|---|
| Figure 20: Storing execution contextx example |
Hardware-supported multi-threading #
Core manages execution contexts for multiple threads
- Runs instructions from runnable threads (processor makes decision about which thread to run each clock, not the operating system)
- Core still has the same number of ALU resources: multi-threading only helps use them more efficiently in the face of high-latency operations like memory access
Interleaved multi-threading (a.k.a. temporal multi-threading): Each clock, the core chooses a thread, and runs an instruction from the thread on the ALUs
Simultaneous multi-threading (SMT)
- Each clock, core chooses instructions from multiple threads to run on ALUs
- Extension of superscalar CPU design
- Example: Intel Hyper-threading (2 threads per core)
Multi-threading summary #
Benefit: use a core’s ALU resources more efficiently
- Hide memory latency
- Fill multiple functional units of superscalar architecture(when one thread has insufficient ILP)
Costs:
- Requires additional storage for thread contexts
- Increases run time of any single thread(often not a problem, we usually care about throughput in parallel apps)
- Requires additional independent work in a program (more independent work than ALUs!)
- Relies heavily on memory bandwidth
- More threads -> larger working set -> less cache space per thread
- May go to memory more often, but can hide the latency
Fictitious multi-core chip #
 |
|---|
| Figure 21: Fictitious multi-core chip |
To utilize this processor at full tilt, 16 * 8 * 4 = 512 independent pices of work are needed to run.
GPUs: Extreme throughput-oriented processors #
GPUs use a lot of these same concepts, just things are pushed to a little bit of an insane degree.
 |
|---|
| Figure 22: NVIDIA GTX 480 @ 1.2 GHz |
CPU vs. GPU memory hierarchies #
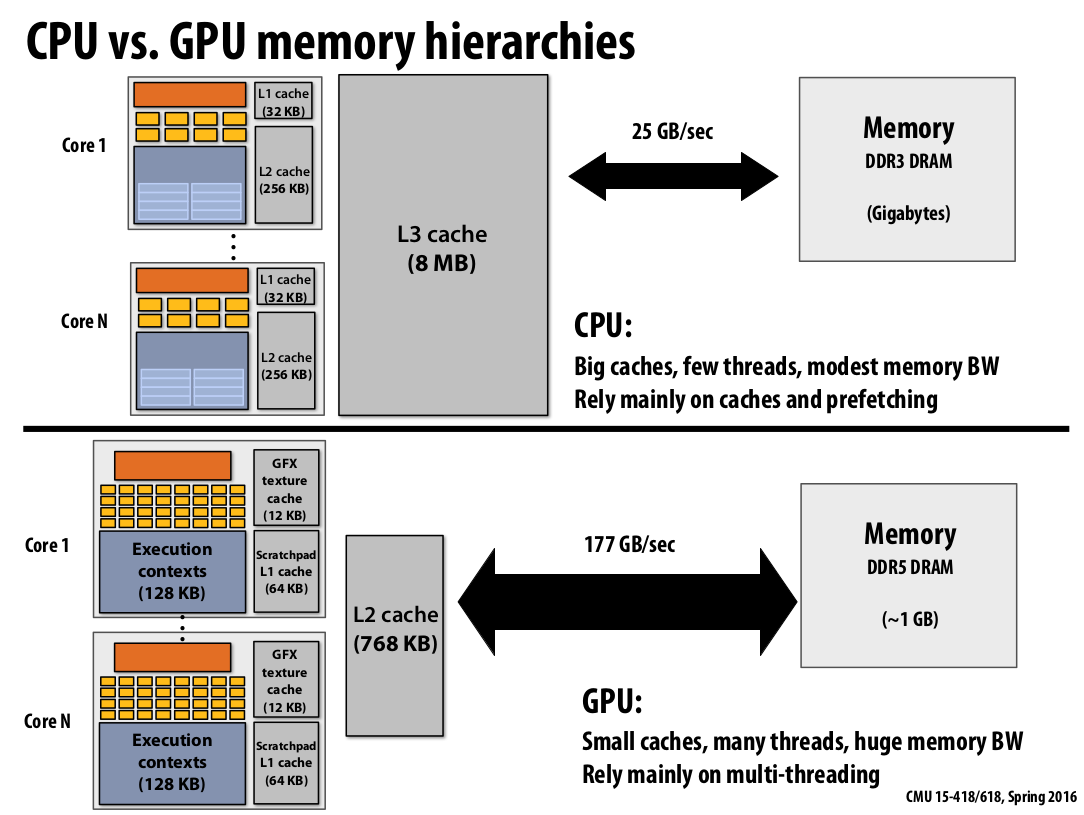 |
|---|
| Figure 23: CPU vs. GPU memory hierarchies |
CPUs are built to hide, to minimize latency.
GPUs, on the other hand, have more cores, tiny little L2, and larger bandwidth compared to CPUs. they are built to have the smallest overhead as much as possible and the fancy stuff and the size of the cache, so they can pack full of ALUs for numerical computing and graphics and other things. But it means they rely heavily on multi-threading to keep all cores busy.
Thought experiment #
Task: element-wise multiplication of two vectors A and B.
Assume vectors contain millions of elements:
- Load input A[i]
- Load input B[i]
- Compute A[i] x B[i]
- Store result into C[i]
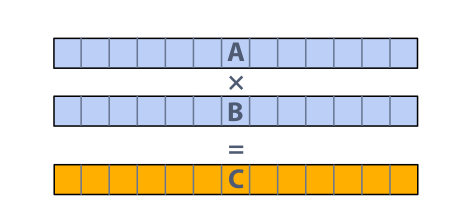 |
|---|
| Figure 24: Thought experiment |
Question: Is this a good parallel application for the GPU above in Figure 22?
The throught process:
- GTX480 has 15 cores and 32 ALUs each core, so totally (15*32=) 480 ALUs.
- When we make full use of ALUs, we can have 480 instructions run per cycle.
- As Frequency is 1.2 GHz, we can have (480 * 1.2 * 10^9 =) 5.76e11 multiplications per second.
- Each multiplication involves (3 int’s =) 12 bytes,
- so total memory bandwidth needs to be (5.76e11 * 12 * 1024^-3=) 6.4 TB/s in order to support that many multiplications.
- Here we only have 177GB/s in Figure 23, so efficiency is only about (177 / 6400 =) 2.7%.
Bandwidth limited!
If processors request data at too high a rate, the memory system cannot keep up. No amount of latency hiding helps this. Overcoming bandwidth limits are a common challenge for application developers on throughput-optimized systems.
Bandwidth is a critical resource, Performant parallel programs should:
Organize computation to fetch data from memory less often
- Reuse data previously loaded by the same thread(traditional intra-thread temporal locality optimizations)
- Share data across threads (inter-thread cooperation)
Request data less often (instead, do more arithmetic: it’s “free”)
- Useful term: “arithmetic intensity” — ratio of math operations to data access operations in an instruction stream
- Main point: programs must have high arithmetic intensity to utilize modern processors efficiently
Summary #
Three major ideas that all modern processors employ to varying degrees
- Employ multiple processing cores, Simpler cores (embrace thread-level parallelism over instruction-level parallelism)
- Amortize instruction stream processing over many ALUs (SIMD)
- Use multi-threading to make more efficient use of processing resources (hide latencies, fill all available resources)
Due to high arithmetic capability on modern chips, many parallel applications (on both CPUs and GPUs) are bandwidth bound.
GPU architectures use the same throughput computing ideas as CPUs: but GPUs push these concepts to extreme scales.
Terms need to know:
- Multi-core processor
- SIMD execution
- Coherent control flow
- Hardware multi-threading
- Interleaved multi-threading
- Simultaneous multi-threading
- Memory latency
- Memory bandwidth
- Bandwidth bound application
- Arithmetic intensity
References #
- http://15418.courses.cs.cmu.edu/spring2016/lecture/whyparallelism
- http://15418.courses.cs.cmu.edu/spring2016/lecture/basicarch
- https://scs.hosted.panopto.com/Panopto/Pages/Viewer.aspx?id=d0795ff8-76aa-4e24-a7cc-e8126025720c
- https://scs.hosted.panopto.com/Panopto/Pages/Viewer.aspx?id=66c4b4cc-5dbd-425c-87ed-5d0d217c20b3