Linux Networking Stack tutorial: Sending Data #
A censorship circumvention tool may be required to open the links in this post from mainland of china.
TL;DR #
This post tries to help readers to conceptualize a high-level overview of how the Linux Network Stack send data to the network.
Consider the following code:
int main(){
fd = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
bind(fd, ...);
listen(fd, ...);
cfd = accept(fd, ...);
// read data
read(cfd, ...);
dosometing();
// send data
send(cfd, buf, sizeof(buf), 0);
}
P.S., The following discussion is based on linux kernel v5.15.
Overview #
The high-level path network data takes from a user program to a network device is as follows:
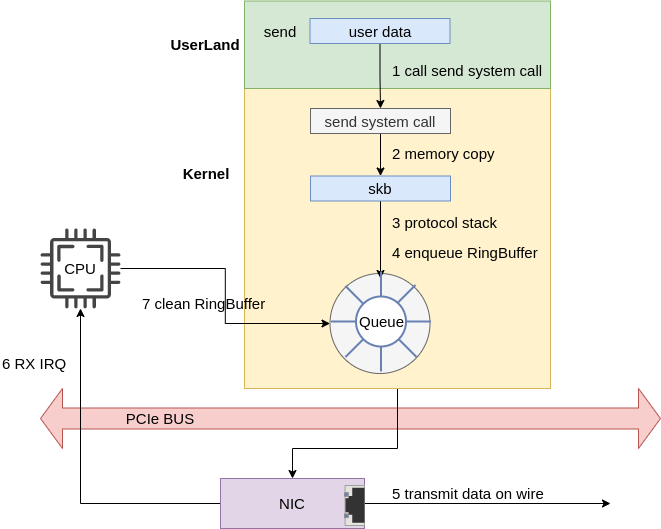 |
|---|
| Fig.1 Overview |
Note:
The NIC signals the transmission complete via the NET_RX IRQ.
Intial setup #
As for the initialization on softirq, NIC dirver, and NIC startup, please check Receiving Data tutorial
Protocol Family registration #
What happens when you run a piece of code like this in a user program to create a UDP socket?
sock = socket(AF_INET, SOCK_STREAM, 0)
In short, the Linux kernel looks up a set of functions exported by the TCP protocol stack that deal with many things including sending and receiving network data.
the Linux kernel executes the inet_init function early during kernel initialization. This function registers the AF_INET protocol family, the individual protocol stacks within that family (TCP, UDP, ICMP, and RAW), and calls initialization routines to get protocol stacks ready to process network data in net/ipv4/af_inet.c.
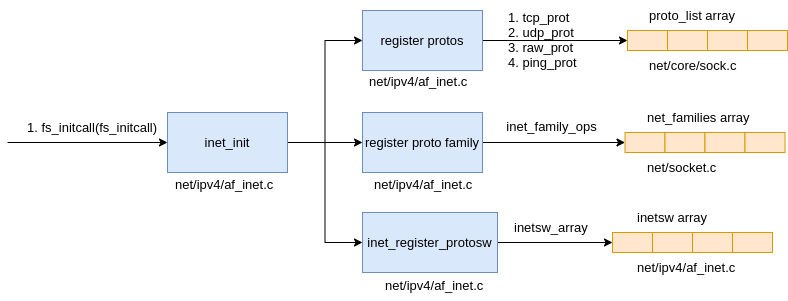 |
|---|
| Fig.2 PF registion |
The AF_INET protocol family exports a structure that has a create function. This function is called by the kernel when a socket is created from a user program:
static const struct net_proto_family inet_family_ops = {
.family = PF_INET,
.create = inet_create,
.owner = THIS_MODULE,
};
The inet_create function takes the arguments passed to the socket system call and searches the registered protocols to find a set of operations to link to the socket.
/* Look for the requested type/protocol pair. */
lookup_protocol:
err = -ESOCKTNOSUPPORT;
rcu_read_lock();
list_for_each_entry_rcu(answer, &inetsw[sock->type], list) {
err = 0;
/* Check the non-wild match. */
if (protocol == answer->protocol) {
if (protocol != IPPROTO_IP)
break;
} else {
/* Check for the two wild cases. */
if (IPPROTO_IP == protocol) {
protocol = answer->protocol;
break;
}
if (IPPROTO_IP == answer->protocol)
break;
}
err = -EPROTONOSUPPORT;
}
Later, answer which holds a reference to a particular protocol stack has its ops fields copied into the socket structure:
sock->ops = answer->ops;
Here are the TCP and UDP protocol structures in inetsw_array
/* Upon startup we insert all the elements in inetsw_array[] into
* the linked list inetsw.
*/
static struct inet_protosw inetsw_array[] =
{
{
.type = SOCK_STREAM,
.protocol = IPPROTO_TCP,
.prot = &tcp_prot,
.ops = &inet_stream_ops,
.flags = INET_PROTOSW_PERMANENT |
INET_PROTOSW_ICSK,
},
{
.type = SOCK_DGRAM,
.protocol = IPPROTO_UDP,
.prot = &udp_prot,
.ops = &inet_dgram_ops,
.flags = INET_PROTOSW_PERMANENT,
},
// more ...
};
In the case of IPPROTO_UDP, an ops structure is linked into place which contains functions for various things, including sending and receiving data:
const struct proto_ops inet_stream_ops = {
.family = PF_INET,
// ...
.sendmsg = inet_sendmsg,
.recvmsg = inet_recvmsg,
// ...
};
EXPORT_SYMBOL(inet_stream_ops);
and a protocol-specific structure prot, which contains function pointers to all the internal UDP protocol stack function. For the TCP protocol, this structure is called tcp_prot and is exported by net/ipv4/tcp_ipv4.c:
struct proto tcp_prot = {
.name = "TCP",
// ...
.recvmsg = tcp_recvmsg,
.sendmsg = tcp_sendmsg,
// ...
};
EXPORT_SYMBOL(tcp_prot);
Accept a connection #
On Linux, the new socket returned by accept() does not inherit file status flags such as O_NONBLOCK and O_ASYNC from the listening socket. This behavior differs from the canonical BSD sockets implementation. Portable programs should not rely on inheritance or noninheritance of file status flags and always explicitly set all required flags on the socket returned from accept().
SYSCALL: send #
The send syscall is in net/socket.c, in which it uses sendto syscall.
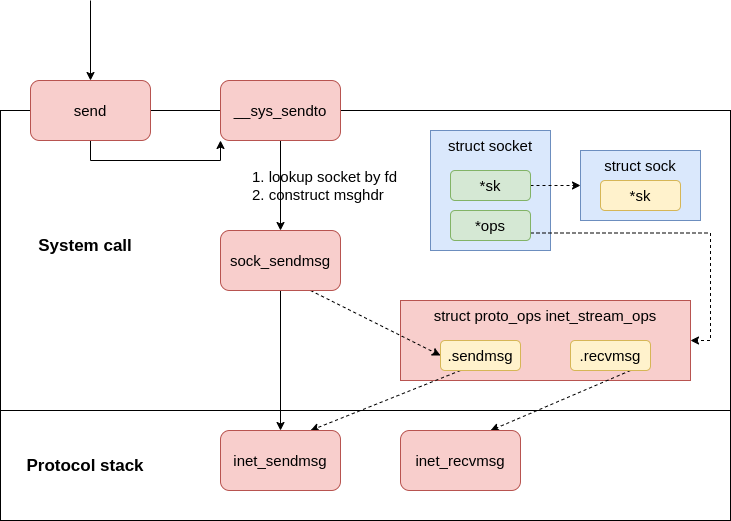 |
|---|
| Fig.3 syscall send |
The data will be handled to the networking stack, in our case TCP via AF_INET generic func inet_sendmsg.
Transmission Control Protocol(TCP) #
Construct skb #
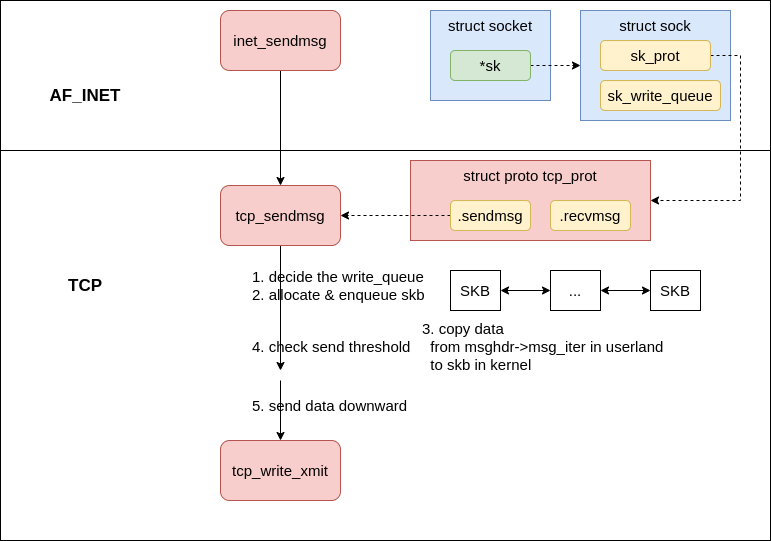 |
|---|
| Fig.4 construct skb |
In inet_sendmsg, kernel will call the protocol sendmsg function via sk_prot in socket which is registerd during the kernel initialization, in our case tcp_sendmsg.
In tcp_sendmsg
- first get the send queue
sk_write_queue - then contstruct a
skb, copy the data in userland to thisskb, and enqueue thisskbto the tail of thequeue - send the skb if
forced_push(tp)orskb == tcp_send_head(sk), otherwise, skip the send operation.
Push skb downward to IP #
Assuming, the transmit conditions are met, the kernel calls tcp_write_xmit(either from __tcp_push_pending_frames or tcp_push_one) to push skbs down to IP stack.
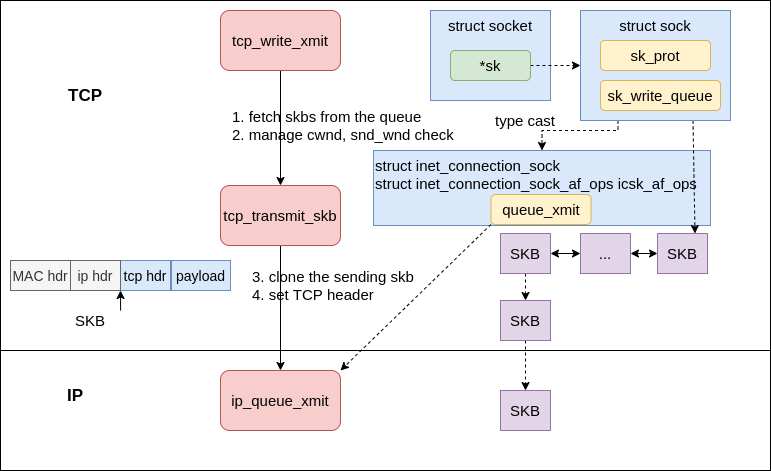 |
|---|
| Fig.5 xmit skb to IP |
Internet Protocol(IP) #
The data transmission in IP stack is implemented in net/ipv4/ip_output.c
The IP stack implemented features like routing, IP header manipulation, netfilter, and skb fragmentation and etc.
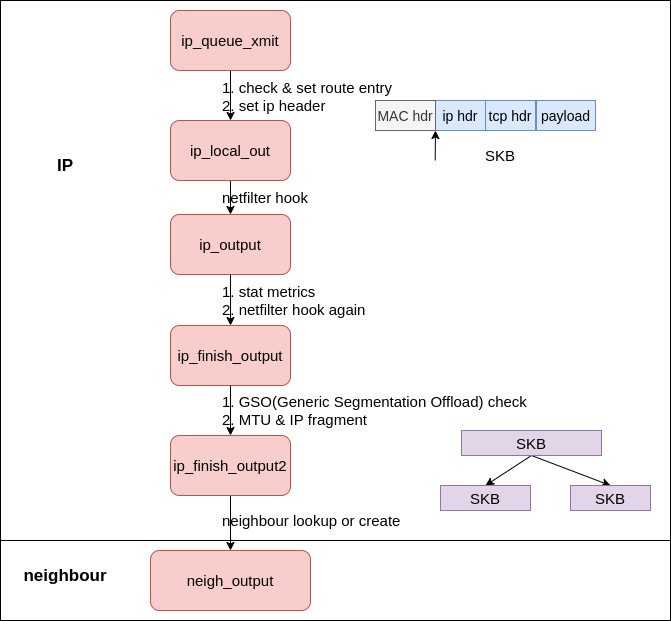 |
|---|
| Fig.6 output skb to neighour |
Neighbour subsystem #
As the name suggested, the neighor subsystem is used for neighor lookup, hardware header population & cache.
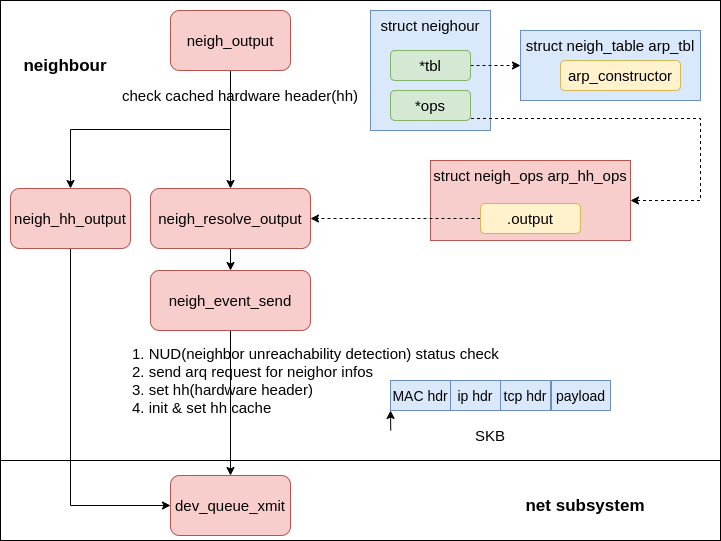 |
|---|
| Fig.7 hardware header |
The neigh_event_send is doing the heavy lifting to resolve the neighbour, but the high-level takeaway from the code is that there are three cases users will most interested in:
- Neighbours in state
NUD_NONE(the default state when allocated) will cause an immediateARPrequest to be sent assuming the values set in/proc/sys/net/ipv4/neigh/default/app_solicitand/proc/sys/net/ipv4/neigh/default/mcast_solicitallow probes to be sent (if not, the state is marked asNUD_FAILED). The neighbour state will be updated and set toNUD_INCOMPLETE. - Neighbours in state
NUD_STALEwill be updated toNUD_DELAYEDand a timer will be set to probe them later (later is the time now +/proc/sys/net/ipv4/neigh/default/delay_first_probe_timeseconds). - Any neighbours in
NUD_INCOMPLETE(including things from case 1 above) will be checked to ensure that the number of queued packets for an unresolved neighbour is less than or equal to/proc/sys/net/ipv4/neigh/default/unres_qlen. If there are more, packets are dequeued and dropped until the length is below or equal to the value in proc. A statistics counter in the neighbour cache stats is bumped for all occurrences of this.
netdevice subsystem #
Before we pick up on the packet transmit path with dev_queue_xmit, let’s take a moment to talk about some important concepts which will appear in the coming sections.
Linux traffic control #
Linux supports a feature called traffic control. This feature allows system administrators to control how packets are transmit from a machine. This blog post will not dive into the details of every aspect of Linux traffic control. This document provides a great in-depth examination of the system, its control, and its features. There a few concepts that are worth mentioning to make the content seen next easier to understand.
The traffic control system contains several different sets of queuing systems that provide different features for controlling traffic flow. Individual queuing systems are commonly called qdisc and also known as queuing disciplines. You can think of qdiscs as schedulers; qdiscs decide when and how packets are transmit.
On Linux every interface has a default qdisc associated with it. For network hardware that supports only a single transmit queue, the default qdisc pfifo_fast is used. Network hardware that supports multiple transmit queues uses the default qdisc of mq. You can check your system by running tc qdisc.
It is also important to note that some devices support traffic control in hardware which can allow an administrator to offload traffic control to the network hardware and conserve CPU resources on the system.
dev_queue_xmit flow #
Now that those ideas have been introduced, let’s proceed down dev_queue_xmit from net/core/dev.c.
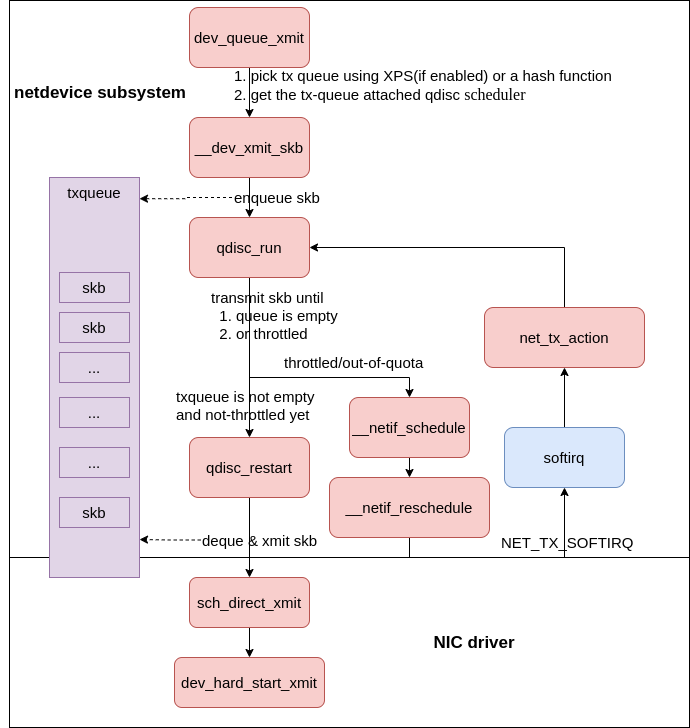 |
|---|
| Fig.8 qdisc-en-txqueue |
Driver TX Queue (aka ring buffer) #
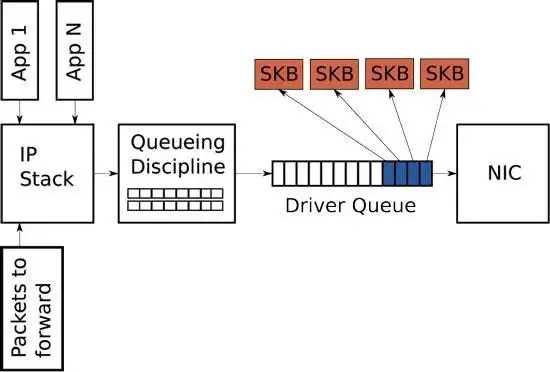 |
|---|
| Fig.9 ring buffer |
NIC driver #
We’re nearing the end of our journey. There’s an important concept to understand about packet transmit. Most devices and drivers deal with packet transmit as a two-step process:
- transmit phase: Data is arranged properly and the device is triggered to DMA the data from RAM and write it to the network
- transmit completion: After the transmit completes, the device will raise an interrupt so the driver can unmap buffers, free memory, or otherwise clean its state.
Transmit phase #
In the igb device driver, the function registered to ndo_start_xmit is called igb_xmit_frame in drivers/net/ethernet/intel/igb/igb_main.c
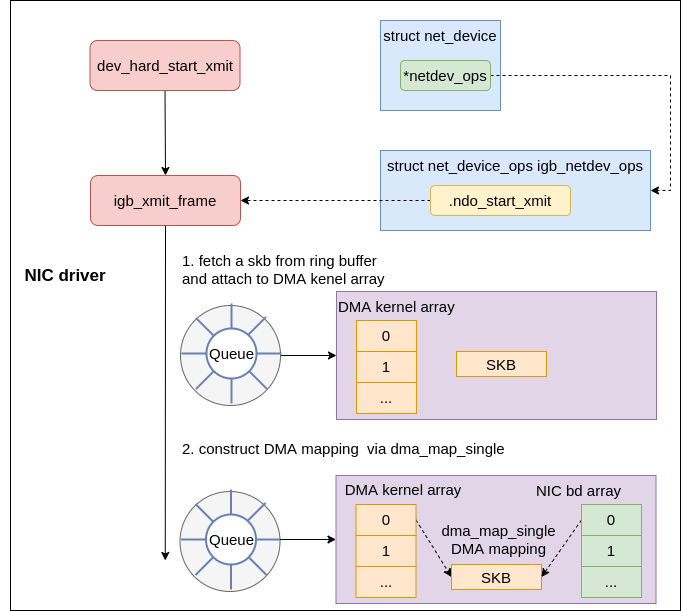 |
|---|
| Fig.10 nic driver xmit |
Transmit completion phase #
Once the device has transmit the data, it will generate an interrupt to signal that transmission is complete. The device driver can then schedule some long running work to be completed, like unmapping memory regions and freeing data. How exactly this works is device specific. In the case of the igb driver (and its associated devices), the same IRQ is fired for transmit completion and packet receive. This means that for the igb driver the NET_RX is used to process both transmit completions and incoming packet receives.
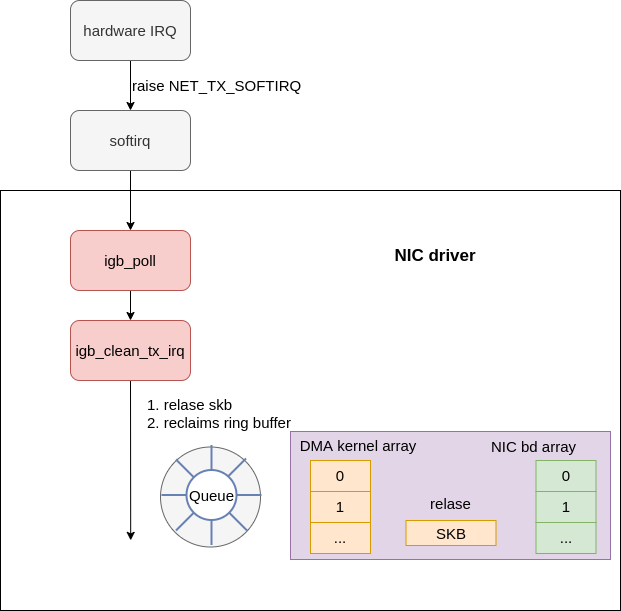 |
|---|
| Fig.11 xmit complete |
Conclusion #
The Linux networking stack is complicated.
As we see above,
- In most cases
sy(time spent in kernel space) is consumed other thansi(time spent handling software interrupt routines) in terms of CPU monitoring, because, only if there is data left after the kernel ran out of the quota, the kernel uses softirq to transmit the remaining data which consumessitime. NET_RXis far greater thanNET_TXin/proc/softirqs, because, transmit completion usesNET_RXas the IRQ.- In the case of TCP, two or three times memory copies would require, the first one is to copy the userland data to skb, then copy the skb from the TCP send queue(required by TCP retransmit feature), and the third one depends on whether IP fragmentation occurs.
These highlights what I believe to be the core of the issue: optimizing and monitoring the network stack is impossible unless you carefully read and understand how it works. You cannot monitor code you don’t understand at a deep level.
This tutorial is trying to serve as a starter for opening the Linux networking stack.