Linux Networking Stack tutorial: Receiving Data #
TL;DR #
This post tries to help readers to conceptualize a high-level overview of how the Linux Network Stack receives data from the network.
Consider the following UDP code:
int main(){
int serverSocketFd = socket(AF_INET, SOCK_DGRAM, 0);
bind(serverSocketFd, ...);
char buff[BUFFSIZE];
int readCount = recvfrom(serverSocketFd, buff, BUFFSIZE, 0, ...);
buff[readCount] = '\0';
printf("Receive from client:%s\n", buff);
}
From the application developer’s perspective, as long as there is data comes from the client and the server is calling recv_from, the server should be able to receive it and print it out. however, we’d like to understand what happens under the hood after a packet arrives NIC until the application receives data from recv_from.
P.S., The following discussion is based on linux kernel v5.15.
Overview #
The TCP/IP model orchestrates the Internet Protocol Suite to Physical, Data link, Network, Transport and Application layers. Things like Network Interface Controler(NIC) card and Network cable are been considered as the Physical layer, Applications like Nginx, Envoy, and so on belong to the Application layer. What Linux implemented are the Data link, Network, and Transport layers. More specifically, the Network device driver implemented the Data link layer, and the kernel protocol stack implemented the Network and Transport layers.
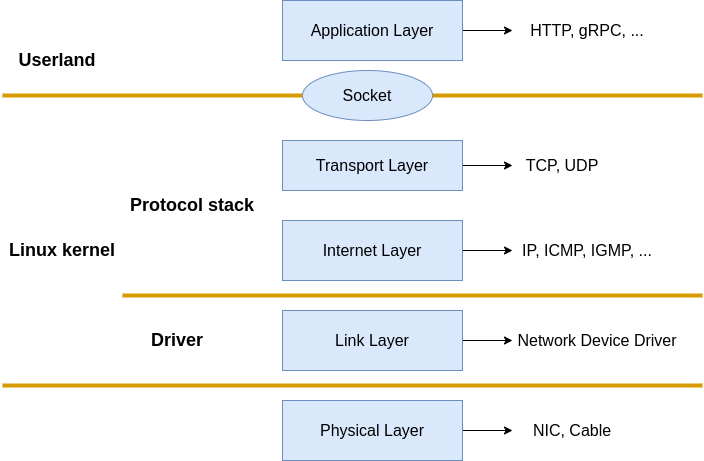 |
|---|
| Fig.1 Linux Network protocol stack |
The network device driver source code can be found at drivers/net/ethernet, source code for intel driver can be found at drivers/net/ethernet/intel. Source code for network stack are located at kernel and net.
The kernel and network device driver interact with each other via interrupt. when data arrives at the network device, it signals a CPU hardware interrupt request(IRQ) to trigger the handler execution. When an IRQ handler is executed by the Linux kernel, it runs at a very, very high priority and often blocks additional IRQs from being generated. As such, IRQ handlers in device drivers must execute as quickly as possible and defer all long-running work to execute outside of this context. This is why the Soft IRQ(implemented by Linux kernel threads ksoftirqd) system exists.
Here is a simplified packet-receiving flow:
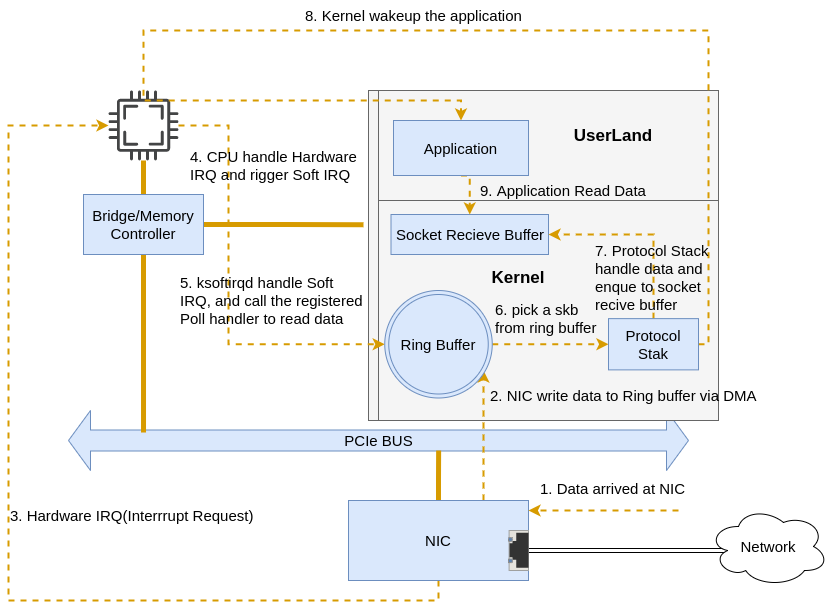 |
|---|
| Fig.2 Simplified Overall Flow |
After the packets arrive at NIC,
- the NIC driver writes frames to RAM via DMA
- the NIC generates a hardware interrupt request to the CPU to indicate data arrived
- CPU calls the interrupt handler registered by the NIC driver, the interrupt handler executes a few instructions and generates a soft IRQ then releases the CPU.
ksoftirqd(one per CPU) receives soft IRQ, and calls registeredpollto pull packets off the ring buffer and deliver them upward to protocol layers.
Initial setup #
Before modules such as the NIC driver and kernel protocol stack are able to receive packets, things like creating ksoftirqd kernel threads, registering protocol handlers, initializing network sub-system, and starting NIC should be done first.
ksoftirqd kernel threads
#
Linux soft interrupt is processed by a group of dedicated kernel threads(ksoftirqd). the number of the ksoftirqd threads should equal the number of CPUs.
During the kernel initialization, kernel/smpboot.c calls smpboot_register_percpu_thread, and smpboot_register_percpu_thread calls spawn_ksoftirqd
 |
|---|
| Fig.3 creat ksoftirqd kernel threads |
static struct smp_hotplug_thread softirq_threads = {
.store = &ksoftirqd,
.thread_should_run = ksoftirqd_should_run,
.thread_fn = run_ksoftirqd,
.thread_comm = "ksoftirqd/%u",
};
static __init int spawn_ksoftirqd(void)
{
register_cpu_notifier(&cpu_nfb);
BUG_ON(smpboot_register_percpu_thread(&softirq_threads));
return 0;
}
early_initcall(spawn_ksoftirqd);
After ksoftirqd kernel threads are created, it will run ksoftirqd_should_run and run_ksoftirqd in its processing loop constantly to check if any soft IRQ is pending for processing. P.S. ksoftirqd threads are designed for process all kinds of soft IRQ in include/linux/interrupt.h
//file: include/linux/interrupt.h
enum{
HI_SOFTIRQ=0,
TIMER_SOFTIRQ,
NET_TX_SOFTIRQ,
NET_RX_SOFTIRQ,
BLOCK_SOFTIRQ,
BLOCK_IOPOLL_SOFTIRQ,
TASKLET_SOFTIRQ,
SCHED_SOFTIRQ,
HRTIMER_SOFTIRQ,
RCU_SOFTIRQ,
};
network sub-system initialization #
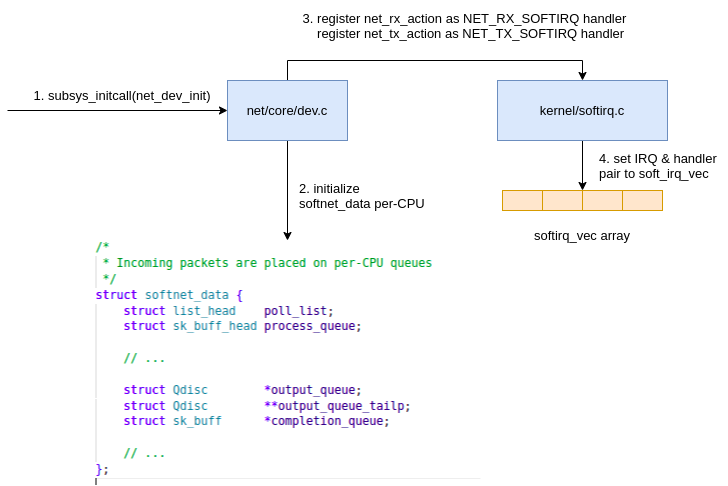 |
|---|
| Fig.4 network subsys init |
Linux kernel intialize supported sub system via subsys_initcall, the net_dev_init is one of them.
//file: net/core/dev.c
static int __init net_dev_init(void){
......
for_each_possible_cpu(i) {
struct softnet_data *sd = &per_cpu(softnet_data, i);
memset(sd, 0, sizeof(*sd));
skb_queue_head_init(&sd->input_pkt_queue);
skb_queue_head_init(&sd->process_queue);
sd->completion_queue = NULL;
INIT_LIST_HEAD(&sd->poll_list);
......
}
......
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
}
subsys_initcall(net_dev_init);
In net_dev_int, it allocate softnet_data for every CPU in which pool_list is a array that keep the registered NIC driver poll function. the register process will be discussed later on.
open_softirq registered net_rx_action as the handler of NET_RX_SOFTIRQ and net_tx_action as the handler of NET_TX_SOFTIRQ, both the IRQs and handlers are been saved into softirq_vec array which will be used later on for handler lookup when a Soft IRQ is processed in run_ksoftirqd.
//file: kernel/softirq.c
void open_softirq(int nr, void (*action)(struct softirq_action *)){
softirq_vec[nr].action = action;
}
protocol stack registration #
The kernel implemented IP protocol at Internet layer, TCP and UDP protocol at Transport layer. The respective implementation handlers for each are ip_rcv, tcp_v4_rcv and udp_rcv. unlike the application code, kernel manage these implementations via registration. like subsys_initcall above, kernel fs_initcall(one of the entry point of the kernel intitialization) call inet_init to register the protocol staks in which the protocol handlers are been registered into inet_protos and ptype_base structures.
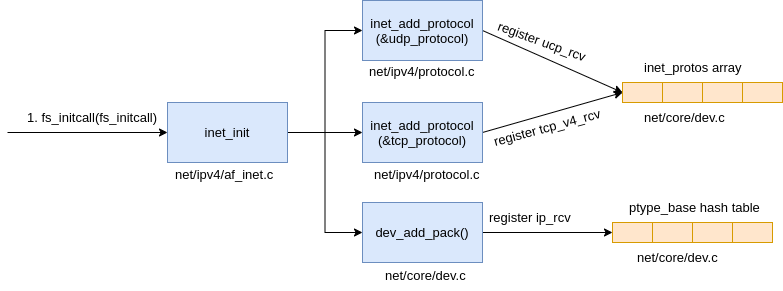 |
|---|
| Fig.5 AF_INET protocol stack registration |
The related code follows:
//file: net/ipv4/af_inet.c
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
};
static const struct net_protocol udp_protocol = {
.handler = udp_rcv,
.err_handler = udp_err,
.no_policy = 1,
.netns_ok = 1,
};
static const struct net_protocol tcp_protocol = {
.early_demux = tcp_v4_early_demux,
.handler = tcp_v4_rcv,
.err_handler = tcp_v4_err,
.no_policy = 1,
.netns_ok = 1,
};
static int __init inet_init(void){
......
if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0)
pr_crit("%s: Cannot add ICMP protocol\n", __func__);
if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0)
pr_crit("%s: Cannot add UDP protocol\n", __func__);
if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0)
pr_crit("%s: Cannot add TCP protocol\n", __func__);
......
dev_add_pack(&ip_packet_type);
}
The above code shows that udp_rev is registered as udp_protocol handler and tcp_v4_rcv is registered as tcp_protocol handler via inet_add_protocol
int inet_add_protocol(const struct net_protocol *prot, unsigned char protocol){
if (!prot->netns_ok) {
pr_err("Protocol %u is not namespace aware, cannot register.\n",
protocol);
return -EINVAL;
}
return !cmpxchg((const struct net_protocol **)&inet_protos[protocol],
NULL, prot) ? 0 : -1;
}
inet_add_protocol registered tcp & udp handlers to inet_protos array. furthermore, ip_packet_type(ip_rcv as the func) is registered to ptype_base hash table
//file: net/core/dev.c
void dev_add_pack(struct packet_type *pt){
struct list_head *head = ptype_head(pt);
......
}
static inline struct list_head *ptype_head(const struct packet_type *pt){
if (pt->type == htons(ETH_P_ALL))
return &ptype_all;
else
return &ptype_base[ntohs(pt->type) & PTYPE_HASH_MASK];
}
The TCP & UDP handlers are kept in inet_protos, and IP handler ip_rcvis kept in ptype_base. run_ksoftirqd can deliver packets upward to IP protocol handler ip_rcv via ptype_base, then continue delivering packets upward to upd_rcv or tcp_v4_rcv in ip_rcv by asking inet_protos for handler lookup.
P.S. protocol handles like ip_rcv and udp_rcv or so on are doing the heavy lifting for data processing, for example, the ip_rcv handler is one of the netfilter and iptables consulting points and ucp_rcv will check if the socket receive buffer queue full or not to decide whether drop the packet(net.core.rmem_max and net.core.rmem_default can be used to adjust the buffer size).
NIC driver registration #
All the drivers are required to use module_init to register their init function to the kernel which will be called by the kernel when the driver is loaded. For igb NIC driver, we can find the init function at drivers/net/ethernet/intel/igb/igb_main.c
//file: drivers/net/ethernet/intel/igb/igb_main.c
static struct pci_driver igb_driver = {
.name = igb_driver_name,
.id_table = igb_pci_tbl,
.probe = igb_probe,
.remove = igb_remove,
......
};
static int __init igb_init_module(void){
......
ret = pci_register_driver(&igb_driver);
return ret;
}
After pci_register-driver(&igb_driver) is called, the Linux kernel knows the driver details such as igb_driver_name and igb_probe and so on. when the kernel detects the NIC card is a valid card, it will call the registered probe function to make the NIC card ready for processing data. in the case of igb driver, it’s igb_probe, the major initialization steps show as Fig.6 flows:
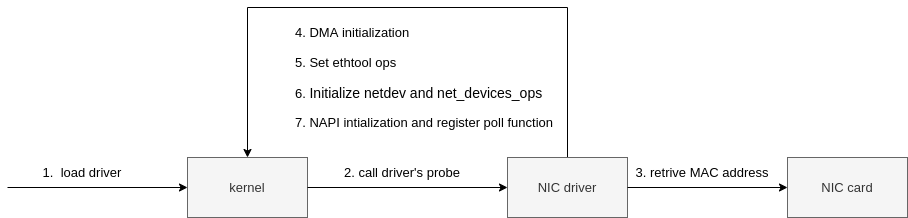 |
|---|
| Fig.6 NIC initialization |
The igb_netdev_ops at step #6 contains a func called igb_open which will be called during the NIC start phase.
//file: drivers/net/ethernet/intel/igb/igb_main.c
static const struct net_device_ops igb_netdev_ops = {
.ndo_open = igb_open,
.ndo_stop = igb_close,
.ndo_start_xmit = igb_xmit_frame,
.ndo_get_stats64 = igb_get_stats64,
.ndo_set_rx_mode = igb_set_rx_mode,
.ndo_set_mac_address = igb_set_mac,
.ndo_change_mtu = igb_change_mtu,
.ndo_do_ioctl = igb_ioctl,
......
At Step #7, during igb_probe initialization, the NAPI poller, i.e. igb_poll, is registered to poll_list of softnet_data(per CPU) via igb_lloc_q_vector.
static int igb_alloc_q_vector(struct igb_adapter *adapter,
int v_count, int v_idx,
int txr_count, int txr_idx,
int rxr_count, int rxr_idx){
......
/* initialize NAPI */
netif_napi_add(adapter->netdev, &q_vector->napi,
igb_poll, 64);
}
Start NIC #
After the intial setup, the NIC is okay to start. as structure net_device_ops was registered to the kernel during the NIC initialization phase. when a NIC was started igb_open in net_device_ops will be called. here are the steps to start a NIC card show as Fig.7 follows:
|
|---|
| Fig.7 NIC start |
//file: drivers/net/ethernet/intel/igb/igb_main.c
static int __igb_open(struct net_device *netdev, bool resuming){
/* allocate transmit descriptors */
err = igb_setup_all_tx_resources(adapter);
/* allocate receive descriptors */
err = igb_setup_all_rx_resources(adapter);
err = igb_request_irq(adapter);
if (err)
goto err_req_irq;
for (i = 0; i < adapter->num_q_vectors; i++)
napi_enable(&(adapter->q_vector[i]->napi));
......
}
__igb_open calls igb_setup_all_tx_resources and igb_setup_all_rx_resources which allocates Rx ring buffer for each queue(number of queues can be configure by ethtool if the NIC supports multip queues).
In the igb_request_irq of igb driver, the functions igb_msix_ring, igb_intr_msi, igb_intr are the interrupt handler methods for the MSI-X, MSI, and legacy interrupt modes, respectively.
/**
* igb_request_irq - initialize interrupts
* @adapter: board private structure to initialize
*
* Attempts to configure interrupts using the best available
* capabilities of the hardware and kernel.
**/
static int igb_request_irq(struct igb_adapter *adapter)
{
struct net_device *netdev = adapter->netdev;
struct pci_dev *pdev = adapter->pdev;
int err = 0;
if (adapter->flags & IGB_FLAG_HAS_MSIX) {
err = igb_request_msix(adapter);
if (!err)
goto request_done;
/* fall back to MSI */
igb_free_all_tx_resources(adapter);
igb_free_all_rx_resources(adapter);
.....
}
.....
if (adapter->flags & IGB_FLAG_HAS_MSI) {
err = request_irq(pdev->irq, igb_intr_msi, 0,
netdev->name, adapter);
if (!err)
goto request_done;
/* fall back to legacy interrupts */
......
}
err = request_irq(pdev->irq, igb_intr, IRQF_SHARED,
netdev->name, adapter);
if (err)
dev_err(&pdev->dev, "Error %d getting interrupt\n",
err);
request_done:
return err;
}
In the case of msix, every RX queue has its own interrupt which allows NIC to notify different CPUs to process the incoming packets(IRQ for multiple RX queues can be managed byirqbalance or by changing /proc/irq/IRQ_NUMBER/smp_affnity to set the CPU affinity).
After all these, the NIC & kernel is ready to process arrival data.
Data processing #
Reference #
- https://blog.packagecloud.io/monitoring-tuning-linux-networking-stack-receiving-data
- https://blog.packagecloud.io/illustrated-guide-monitoring-tuning-linux-networking-stack-receiving-data/
- https://mp.weixin.qq.com/s?__biz=MjM5Njg5NDgwNA==&mid=2247484058&idx=1&sn=a2621bc27c74b313528eefbc81ee8c0f&chksm=a6e303a191948ab7d06e574661a905ddb1fae4a5d9eb1d2be9f1c44491c19a82d95957a0ffb6&scene=178&cur_album_id=1532487451997454337
- https://medium.com/coccoc-engineering-blog/linux-network-ring-buffers-cea7ead0b8e8