Linux Networking Stack tutorial: Receiving Data #
A censorship circumvention tool may be required to open the links in this post from mainland of china.
TL;DR #
This post tries to help readers to conceptualize a high-level overview of how the Linux Network Stack receives data from the network.
Consider the following UDP code:
int main(){
int serverSocketFd = socket(AF_INET, SOCK_DGRAM, 0);
bind(serverSocketFd, ...);
char buff[BUFFSIZE];
int readCount = recvfrom(serverSocketFd, buff, BUFFSIZE, 0, ...);
buff[readCount] = '\0';
printf("Receive from client:%s\n", buff);
}
From the application developer’s perspective, as long as there is data comes from the client and the server is calling recv_from, the server should be able to receive it and print it out. however, we’d like to understand what happens under the hood after a packet arrives NIC until the application receives data from recv_from.
P.S., The following discussion is based on linux kernel v5.15.
Overview #
The TCP/IP model orchestrates the Internet Protocol Suite to Physical, Data link, Network, Transport and Application layers. Things like Network Interface Controler/Card(NIC) and Network cable are been considered as the Physical layer, Applications like Nginx, Envoy, and so on belong to the Application layer. What Linux implemented are the Data link, Network, and Transport layers. More specifically, the NIC driver implemented the Data link layer, and the kernel protocol stack implemented the Network and Transport layers.
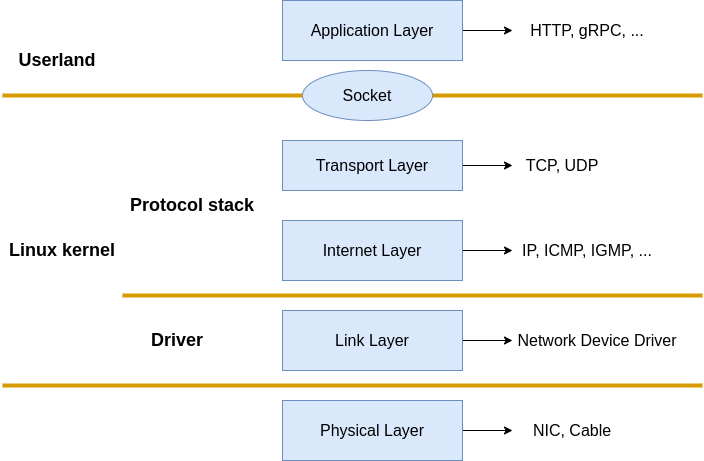 |
|---|
| Fig.1 Linux Network protocol stack |
The high level path a packet takes from arrival to socket receive buffer is as follows:
- Driver is loaded and initialized.
- Packet arrives at the NIC from the network.
- Packet is copied (via DMA) to a ring buffer in kernel memory.
- Hardware interrupt is generated to let the system know a packet is in memory.
- Driver calls into NAPI to start a
pollloop if one was not running already(vianapi_scheduleor other NAPI APIs from device). ksoftirqdprocesses run on each CPU on the system. They are registered at boot time. Theksoftirqdprocesses pull packets off thering bufferby calling theNAPIpollfunction that the device driver registered during initialization.- Memory regions in the
ring bufferthat have had network data written to them are unmapped. - Data that was DMA’d into memory is passed up the networking layer as an
skbfor more processing. - Incoming network data frames are distributed among multiple CPUs if Receive Packet Steering (RPS) is enabled or if the
NIChas multiple receive queues. - Network data frames are handed to the protocol layers from the queues.
- Protocol layers process data.
- Data is added to receive buffers attached to sockets by protocol layers.
Here is a simplified version of the overall flow(some of the steps above are left out) follows:
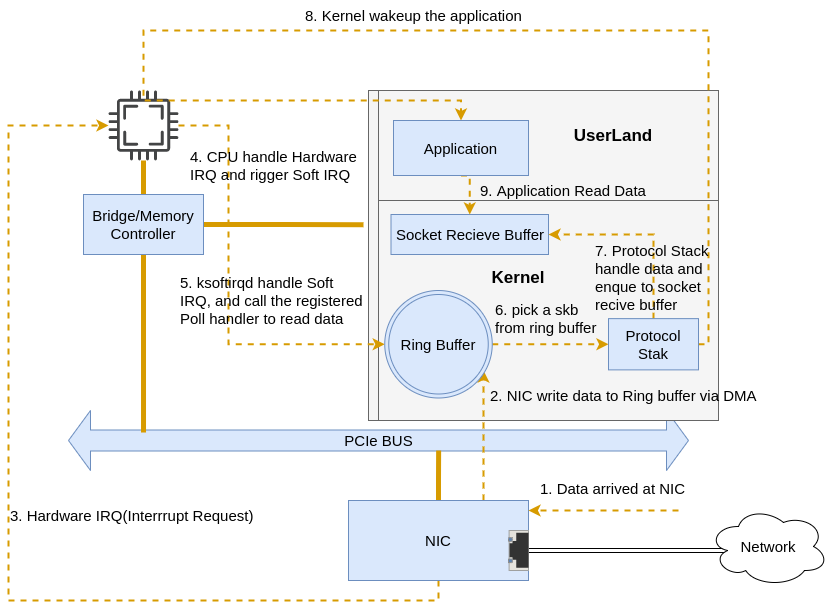 |
|---|
| Fig.2 Simplified Overall Flow |
This entire flow will be separated into different parts to walk through.
The protocol layers examined below are the IP and UDP protocol layers. Much of the information presented will serve as a reference for other protocol layers, as well.
Initial setup #
Devices have many ways of alerting the rest of the computer system that some work is ready for processing. In the case of network devices, it is common for the NIC to raise an IRQ to signal that a packet has arrived and is ready to be processed. When an IRQ handler is executed by the Linux kernel, it runs at a very, very high priority and often blocks additional IRQs from being generated. As such, IRQ handlers in device drivers must execute as quickly as possible and defer all long running work to execute outside of this context. This is why the softirq system exists.
softirq initialization
#
The softirq system in the Linux kernel is a system that kernel uses to process work outside of the device driver IRQ context. In the case of network devices, the softirq system is responsible for processing incoming packets. The softirq system is initialized early during the boot process of the kernel.
The initialization of the softirq system is as follows:
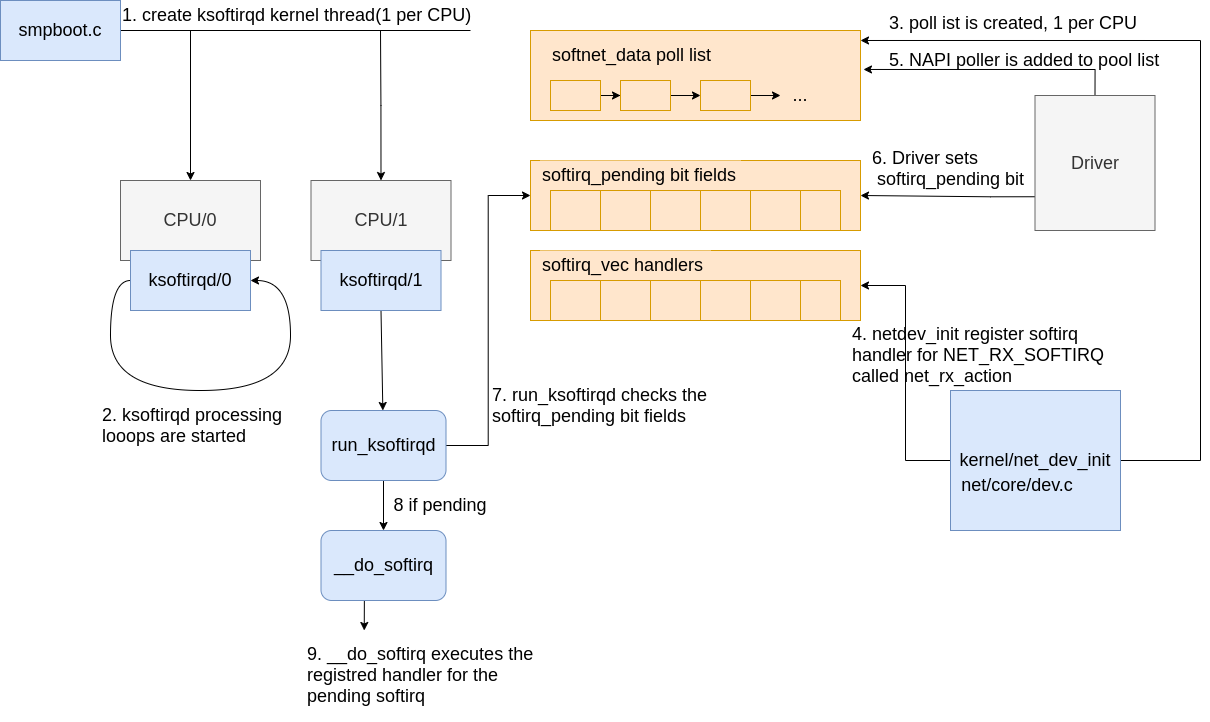 |
|---|
| Fig.3 softirq Intial setup |
softirqkernel threads are created (one per CPU) inspawn_ksoftirqdin kernel/softirq.c with a call tosmpboot_register_percpu_threadfrom kernel/smpboot.c. As seen in the code, the functionrun_ksoftirqdis listed asthread_fn, which is the function that will be executed in a loop.- The ksoftirqd threads begin executing their processing loops in the
run_ksoftirqdfunction. - Next, the
softnet_data structuresare created, one per CPU. These structures hold references to important data structures for processing network data. One we’ll see again is thepoll_list. Thepoll_listis whereNAPI pollworker structures will be added by calls tonapi_scheduleor other NAPI APIs from device drivers. net_dev_initthen registers theNET_RX_SOFTIRQsoftirq with the softirq system by callingopen_softirq, as shown here. The handler function that is registered is callednet_rx_action. This is the function thesoftirqkernel threads will execute to process packets.
Steps 5 - 8 on the diagram relate to the arrival of data for processing and will be mentioned in the next section. Read on for more!
NIC driver intiallization #
All the drivers are required to use module_init to register their init function to the kernel which will be called by the kernel when the driver is loaded. For igb NIC driver, we can find the init function at drivers/net/ethernet/intel/igb/igb_main.c
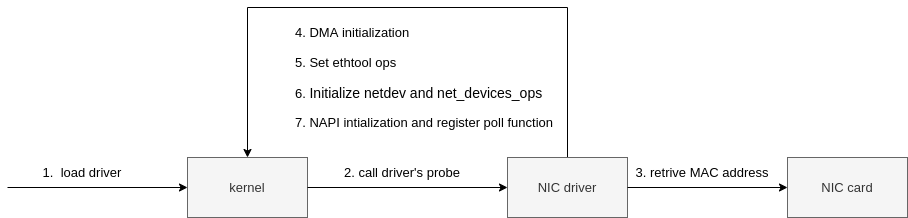 |
|---|
| Fig.4 NIC driver Intial setup |
- when driver is loaded into kernel, kernel calls
pci_register_driverinigb_init_module, the Linux kernel knows the driver details such asigb_driver_nameandigb_probeand so on. - the kernel detects the NIC card is a valid card, it will call the registered
probefunction, i.e.,igb_probein our case,igb_probethen performs the next steps - MAC Initialization
- Initialize ethernet
- Set ethtool ops
- Initialize netdev and
net_device_ops - Initialize NAPI and register
poolfunction
Bringing a NIC up #
Recall the net_device_ops structure we saw earlier which registered a set of functions for bringing the NIC up, transmitting packets, setting the MAC address, etc.
When a NIC is brought up (for example, with ifconfig eth0 up), the function attached to the ndo_open field of the net_device_ops structure is called. i.e., igb_open in our case.
The igb_open function will typically do things like:
 |
|---|
| Fig.5 NIC start |
- Allocate RX and TX queue memory
- Enable NAPI
- Register an interrupt handler
- Enable hardware interrupts
Data arrives #
When network data arrives at a NIC, the NIC will use DMA to write the packet data to RAM. In the case of the igb network driver, a ring buffer is setup in RAM that points to received packets. It is important to note that some NICs are multiqueue NICs, meaning that they can DMA incoming packets to one of many ring buffers in RAM. As we’ll see soon, such NICs are able to make use of multiple processors for processing incoming network data. Read more about multiqueue NICs. The diagram in Fig.6 below shows just a single ring buffer for simplicity, but depending on the NIC you are using and your hardware settings you may have multiple queues on your system.
Read more detail about the process describe below in this section of the networking blog post.
Let’s walk through the process of receiving data:
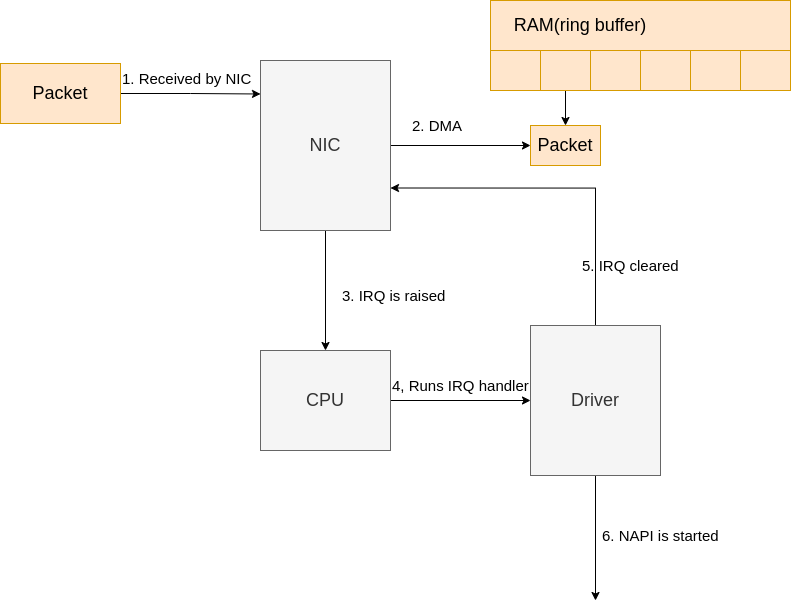 |
|---|
| Fig.6 Data arrives |
- Data is received by the NIC from the network.
- The NIC uses DMA to write the network data to RAM.
- The NIC raises an IRQ.
- The NIC driver’s registered IRQ handler is executed.
- The IRQ is cleared on the NIC, so that it can generate IRQs for new packet arrivals.
NAPI softirq poll loopis started with a call tonapi_schedule.
The call to napi_schedule triggers the start of steps 5 - 8 in Fig.3 above. As we’ll see, the NAPI softirq poll loop is started by simply flipping a bit in a bitfield and adding a structure to the poll_list for processing. No other work is done by napi_schedule and this is precisely how a driver defers processing to the softirq system.
Continuing on to the diagram in the Fig.3, using the numbers found there:
- The call to
napi_schedulein the driver adds the driver’s NAPI poll structure to thepoll_listfor the current CPU. - The softirq pending bit is set so that the
ksoftirqdprocess on this CPU knows that there are packets to process. run_ksoftirqdfunction (which is being run in a loop by theksoftirqkernel thread) executes.__do_softirqis called which checks the pending bitfield, sees that a softirq is pending, and calls the handler registered for the pending softirq:net_rx_actionwhich does all the heavy lifting for incoming network data processing.
It is important to note that the softirq kernel thread is executing net_rx_action, not the device driver IRQ handler.
Network data processing begins #
Now, data processing begins. The net_rx_action function (called from the ksoftirqd kernel thread) will start to process any NAPI poll structures that have been added to the poll_list for the current CPU. Poll structures are added in two general cases:
- From device drivers with calls to
napi_schedule. - With an Inter-processor Interrupt, a.k.a IPI in the case of Receive Packet Steering. Read more about how Receive Packet Steering uses IPIs to process packets.
We’re going to start by walking through what happens when a driver’s NAPI structure is retreived from the poll_list. (The next section how NAPI structures registered with IPIs for RPS work).
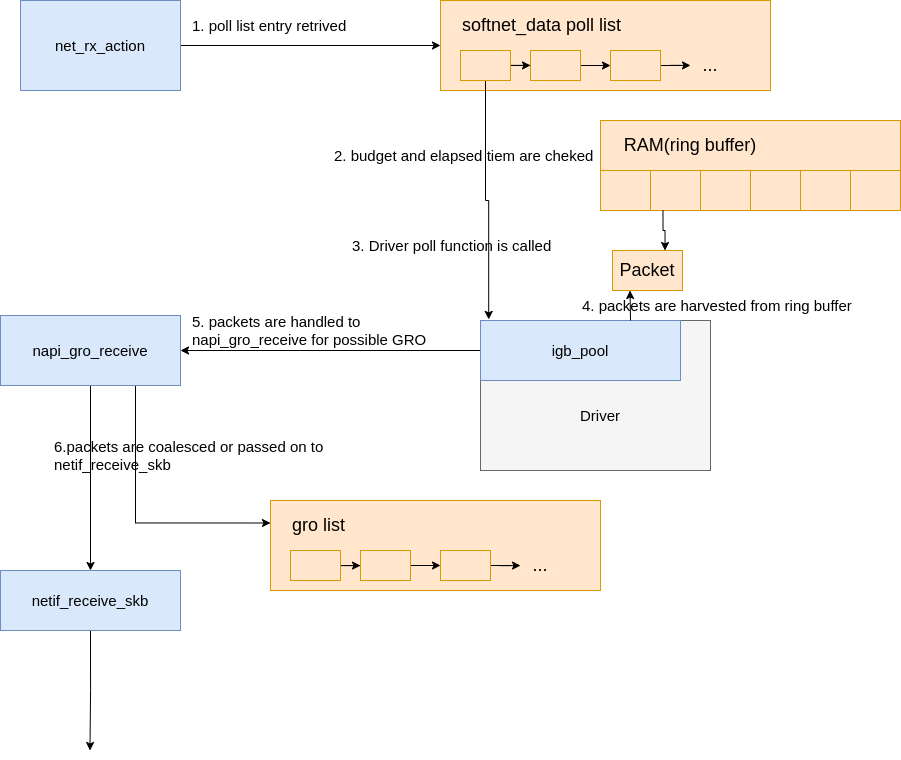 |
|---|
| Fig.7 Data processing begins |
The diagram above is explained in depth here, but can be summarized as follows:
net_rx_actionloop starts by checking the NAPI poll list for NAPI structures.- The
budgetand elapsed time are checked to ensure that the softirq will not monopolize CPU time. - The registered
pollfunction is called. In this case, the functionigb_pollwas registered by theigbdriver. - The driver’s
pollfunction harvests packets from the ring buffer in RAM. - Packets are handed over to
napi_gro_receive, which will deal with possible Generic Receive Offloading. - Packets are either held for GRO and the call chain ends or packets are passed on to
netif_receive_skbto proceed up toward the protocol stacks.
We’ll see next how netif_receive_skb deals with Receive Packet steering to distribute the packet processing load amongst multiple CPUs.
Network data processing continues #
Network data processing continues from netif_receive_skb, but the path of the data depends on whether or not Receive Packet Steering (RPS) is enabled or not. An out of the box Linux kernel will not have RPS enabled by default and it will need to be explicitly enabled and configured if you want to use it.
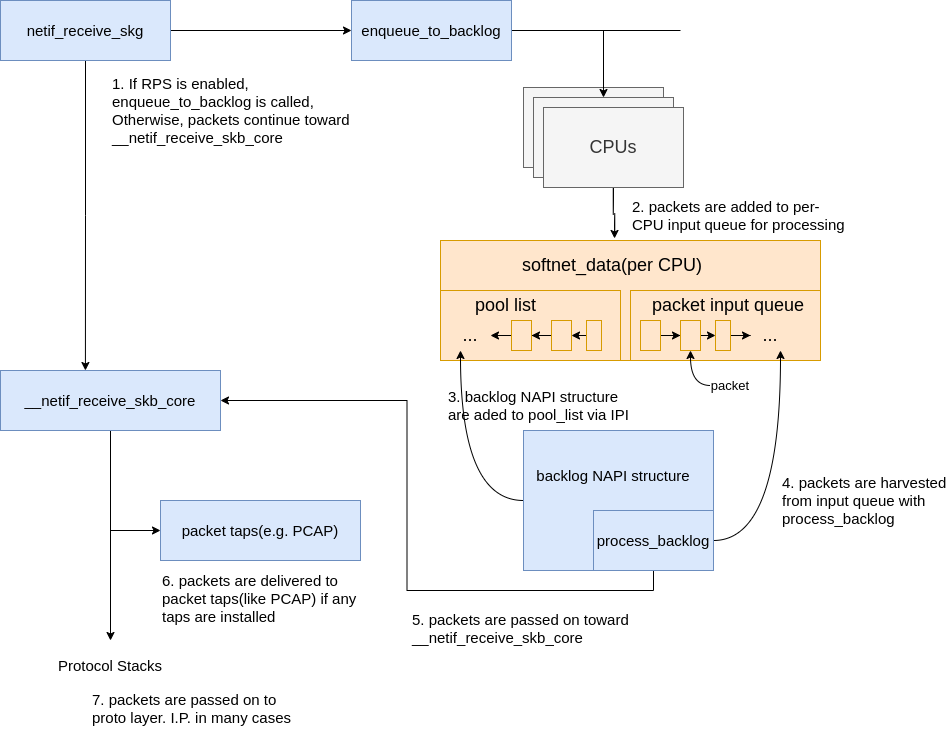 |
|---|
| Fig.8 Data processing continues |
In the case where RPS is disabled, using the numbers in the above Fig.8:
netif_receive_skbpasses the data on to__netif_receive_core.__netif_receive_coredelivers data to any taps (like PCAP). 7,__netif_receive_coredelivers data to registered protocol layer handlers. In many cases, this would be theip_rcvfunction that the IPv4 protocol stack has registered.
In the case where RPS is enabled:
netif_receive_skbpasses the data on toenqueue_to_backlog.- Packets are placed on a per-CPU input queue for processing.
- The remote CPU’s NAPI structure is added to that CPU’s
poll_listand an IPI is queued which will trigger theksoftirqdkernel thread on the remote CPU to wake-up if it is not running already. - When the
ksoftirqdkernel thread on the remote CPU runs, it follows the same pattern describe in the previous section, but this time, the registeredpollfunction isprocess_backlogwhich harvests packets from the current CPU’s input queue. - Packets are passed on toward
__net_receive_skb_core. __netif_receive_coredelivers data to any taps (like PCAP).__netif_receive_coredelivers data to registered protocol layer handlers. In many cases, this would be theip_rcvfunction that the IPv4 protocol stack has registered.
Protocol stacks and userland sockets #
Next up are the protocol stacks, netfilter, berkley packet filters, and finally the userland socket. This code path is long, but linear and relatively straightforward.
You can continue following the detailed path for network data. A very brief, high level summary of the path is:
- Packets are received by the IPv4 protocol layer with
ip_rcv. netfilter,iptablesand a routing optimization are performed.- Data destined for the current system is delivered to higher-level protocol layers, like UDP.
- Packets are received by the UDP protocol layer with
udp_rcvand are queued to the receive buffer of a userland socket byudp_queue_rcv_skbandsock_queue_rcv. Prior to queuing to the receive buffer,netfilterare processed. - Finally, any processes in userland waiting on data to arrive in the socket are notified with a call to the
sk_data_readynotification handler function insock_queue_rcv.
Note that netfilter & iptables is consulted multiple times throughout this process. The exact locations can be [ound in this detailed walk-through.
Keep in mind: if you have numerous or very complex netfilter or iptables rules, those rules will be executed in the softirq context and can lead to latency in your network stack. This may be unavoidable, though, if you need to have a particular set of rules installed.
Monitoring & Tuning #
It is impossible to tune or monitor the Linux networking stack without reading the source code of the kernel and having a deep understanding of what exactly is happening.
As a starter for monitoring & tuning, Here are some hints gathered from this awesome post for monitoring & tuning the Linux networking stack
Hints for diving in #
- Monitoring network devices
- Tuning network devices
- Monitoring softirqs
- Monitoring network data arrival
- Tuning network data arrival
- Monitoring network data processing
- Tuning network data processing
- Tuning: Adjusting GRO settings with ethtool
- Monitoring: Monitor drops due to full input_pkt_queue or flow limit
- Tuning: Flow limits
- Monitoring: IP protocol layer statistics
- Monitoring: UDP protocol layer statistics
Note: Since some of the sections are not addressable in this orign post, you may need to use the browser search to locate them manually.
Hints for tools #
- ethtool: a powerfull moitoring & tunning for network device, e.g.,
# Increase size of each RX queue(ring buffer) to 4096 with ethtool -G $ sudo ethtool -G eth0 rx 4096 sysfs: a slightly higher level(compared toethtool) statistics for NIC, e.g.,$ cat /sys/class/net/eth0/statistics/rx_dropped 2/proc/net/dev: a even higher level summary-esque information for each network adapter, e.g.,$ cat /proc/net/dev Inter-| Receive | Transmit face | bytes packets errs drop fifo frame compressed multicast | bytes packets errs drop fifo colls carrier compressed eth0: 110346752214 597737500 0 2 0 0 0 20963860 990024805984 6066582604 0 0 0 0 0 0 lo: 428349463836 1579868535 0 0 0 0 0 0 428349463836 1579868535 0 0 0 0 0 0/proc/softirqs: softirq system statistic counters, e.g.,$ cat /proc/softirqs CPU0 CPU1 CPU2 CPU3 HI: 0 0 0 0 TIMER: 2831512516 1337085411 1103326083 1423923272 NET_TX: 15774435 779806 733217 749512 NET_RX: 1671622615 1257853535 2088429526 2674732223 BLOCK: 1800253852 1466177 1791366 634534 BLOCK_IOPOLL: 0 0 0 0 TASKLET: 25 0 0 0 SCHED: 2642378225 1711756029 629040543 682215771 HRTIMER: 2547911 2046898 1558136 1521176 RCU: 2056528783 4231862865 3545088730 844379888/proc/interrupts: Hardware interrupt requests, e.g.,$ cat /proc/interrupts CPU0 CPU1 CPU2 CPU3 0: 46 0 0 0 IR-IO-APIC-edge timer 1: 3 0 0 0 IR-IO-APIC-edge i8042 30: 3361234770 0 0 0 IR-IO-APIC-fasteoi aacraid 64: 0 0 0 0 DMAR_MSI-edge dmar0 65: 1 0 0 0 IR-PCI-MSI-edge eth0 66: 863649703 0 0 0 IR-PCI-MSI-edge eth0-TxRx-0 67: 986285573 0 0 0 IR-PCI-MSI-edge eth0-TxRx-1 68: 45 0 0 0 IR-PCI-MSI-edge eth0-TxRx-2 69: 394 0 0 0 IR-PCI-MSI-edge eth0-TxRx-3 NMI: 9729927 4008190 3068645 3375402 Non-maskable interrupts LOC: 2913290785 1585321306 1495872829 1803524526 Local timer interrupts/proc/irq/IRQ_NUMBER/smp_affinity: IRQ affinities, e.g.,# Check irqbalance configuration, before perform this command, # Set the IRQ affinity for IRQ 8 to CPU 0 $ sudo bash -c 'echo 1 > /proc/irq/8/smp_affinity'/proc/net/softnet_stat: This statistic is tracked as part of the struct softnet_data associated with the CPU, e.g.,$ cat /proc/net/softnet_stat 6dcad223 00000000 00000001 00000000 00000000 00000000 00000000 00000000 00000000 00000000 6f0e1565 00000000 00000002 00000000 00000000 00000000 00000000 00000000 00000000 00000000 660774ec 00000000 00000003 00000000 00000000 00000000 00000000 00000000 00000000 00000000 61c99331 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 6794b1b3 00000000 00000005 00000000 00000000 00000000 00000000 00000000 00000000 00000000 6488cb92 00000000 00000001 00000000 00000000 00000000 00000000 00000000 00000000 00000000/proc/net/snmp: detailed IP protocol statistics$ cat /proc/net/snmp Ip: Forwarding DefaultTTL InReceives InHdrErrors InAddrErrors ForwDatagrams InUnknownProtos InDiscards InDelivers OutRequests OutDiscards OutNoRoutes ReasmTimeout ReasmReqds ReasmOKs ReasmFails FragOKs FragFails FragCreates Ip: 1 64 25922988125 0 0 15771700 0 0 25898327616 22789396404 12987882 51 1 10129840 2196520 1 0 0 0 .../proc/net/netstat: extended IP protocol statistics$ cat /proc/net/netstat | grep IpExt IpExt: InNoRoutes InTruncatedPkts InMcastPkts OutMcastPkts InBcastPkts OutBcastPkts InOctets OutOctets InMcastOctets OutMcastOctets InBcastOctets OutBcastOctets InCsumErrors InNoECTPkts InECT0Pktsu InCEPkts IpExt: 0 0 0 0 277959 0 14568040307695 32991309088496 0 0 58649349 0 0 0 0 0/proc/net/udp: UDP socket statistics$ cat /proc/net/udp sl local_address rem_address st tx_queue rx_queue tr tm->when retrnsmt uid timeout inode ref pointer drops 515: 00000000:B346 00000000:0000 07 00000000:00000000 00:00000000 00000000 104 0 7518 2 0000000000000000 0 558: 00000000:0371 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 7408 2 0000000000000000 0 588: 0100007F:038F 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 7511 2 0000000000000000 0 769: 00000000:0044 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 7673 2 0000000000000000 0 812: 00000000:006F 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 7407 2 0000000000000000 0cat /proc/net/tcp: TCP socket statistics$ cat /proc/net/tcp sl local_address rem_address st tx_queue rx_queue tr tm->when retrnsmt uid timeout inode 0: 0100007F:F199 00000000:0000 0A 00000000:00000000 00:00000000 00000000 1000 0 127900 1 0000000000000000 100 0 0 10 0 1: 00000000:0386 00000000:0000 0A 00000000:00000000 00:00000000 00000000 0 0 45649 1 0000000000000000 100 0 0 10 0 2: 00000000:0016 00000000:0000 0A 00000000:00000000 00:00000000 00000000 0 0 36314 1 0000000000000000 100 0 0 10 0 3: 00000000:18EB 00000000:0000 0A 00000000:00000000 00:00000000 00000000 0 0 323024 1 0000000000000000 100 0 0 10 0 4: 0100007F:6F93 00000000:0000 0A 00000000:00000000 00:00000000 00000000 1000 0 502101 1 0000000000000000 100 0 0 10 0 5: 0100007F:EF19 00000000:0000 0A 00000000:00000000 00:00000000 00000000 0 0 43064 1 0000000000000000 100 0 0 10 0
kernel parameters #
net.core.netdev_budget: how much packet processing can be spent among all NAPI structures registered to a CPU, default is300net.core.netdev_max_backlog: help prevent drops in enqueue_to_backlog by increasing the netdev_max_backlog if you are using RPS or if your driver calls netif_rx, default is1000net.core.dev_weight: how much of the overall budget the backlog poll loop can consume, default 64net.core.flow_limit_table_len: the size of the flow limit table, default 4906net.core.rps_sock_flow_entries: the size of the RFS socket flow hashnet.core.netdev_tstamp_prequeue: when packets will be timestamped after they are receivednet.core.rmem_max: the maximum receive buffer sizenet.core.rmem_default: the default initial receive buffer size
Conclusion #
The Linux network stack is incredibly complex and has many different systems interacting together. Any effort to tune or monitor these complex systems must strive to understand the interation between all of them and how changing settings in one system will affect others.
This (poorly) illustrated post attempts to help readers form basic picture of how the Linux network stack works.
Reference #
- https://blog.packagecloud.io/monitoring-tuning-linux-networking-stack-receiving-data
- https://blog.packagecloud.io/illustrated-guide-monitoring-tuning-linux-networking-stack-receiving-data/
- https://medium.com/coccoc-engineering-blog/linux-network-ring-buffers-cea7ead0b8e8
- https://wiki.linuxfoundation.org/networking/kernel_flow
- https://stackoverflow.com/questions/47450231/what-is-the-relationship-of-dma-ring-buffer-and-tx-rx-ring-for-a-network-card