Distributed OLAP Databases #
A censorship circumvention tool may be required to open the links in this post from mainland of china.
1. Introduction #
For a read-only OLAP database, it is common to have a bifurcated environment, where there are multiple instances of OLTP databases that ingest information from the outside world which is then fed into the backend OLAP database, sometimes called a data warehouse. There is an intermediate step called ETL(Extract Transform, and Load) or ELT in a modern system, which combines the OLTP databases into a universal schema for the data warehouse.
2. Decision Support System #
Decision support systems(DSS) are applications that serve the management, operations, and planning levels of an organization to help people make decisions about future issues and problems by analyzing historical data stored in a data warehouse.
The two approaches for modeling an analytical database are star schemas and snowflake schemas.
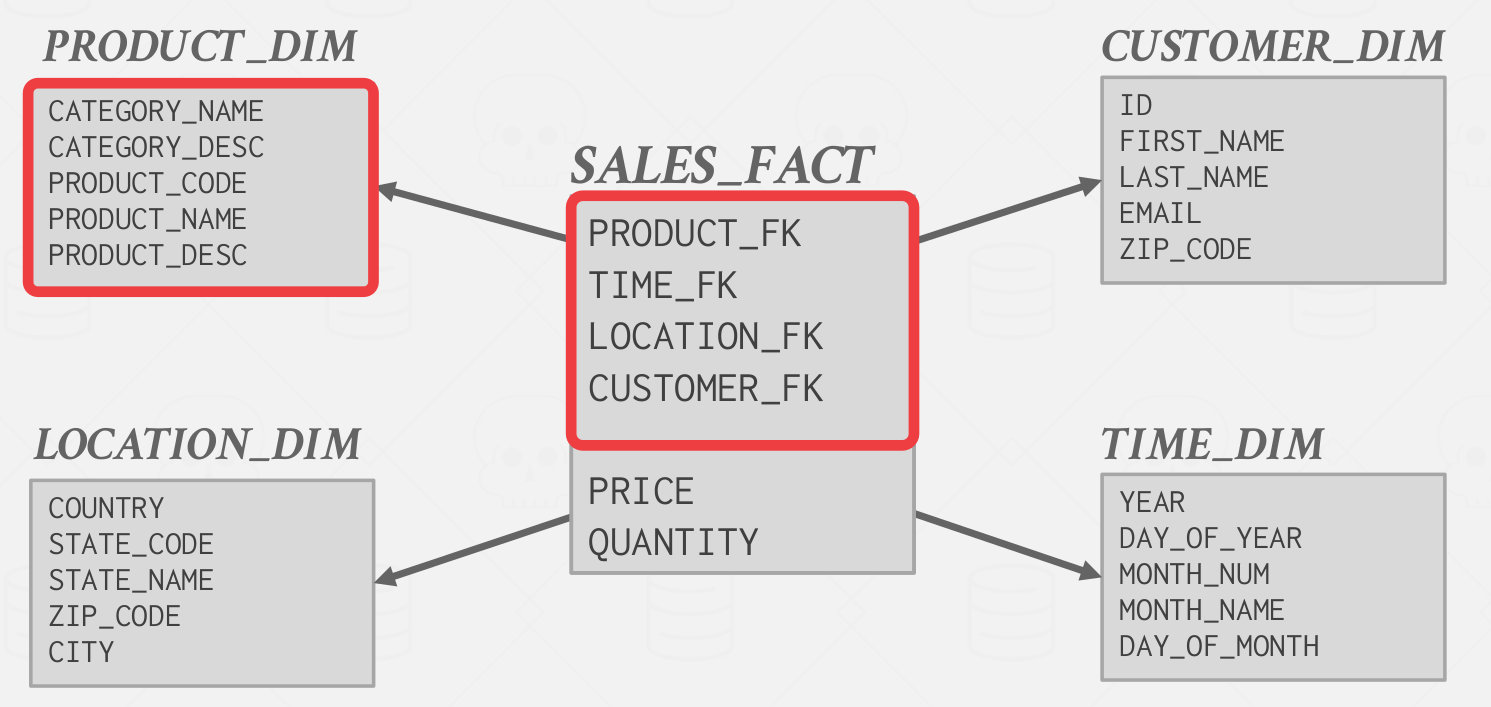
Star Schema #
Star schemas contain two types of tables: fact tables and dimension tables. The fact table contains multiple “events” that occur in the application. It will contain the minimal unique information per event, and then the rest of the attributes will be foreign key references to outer dimension tables. The dimension tables contain redundant information that is reused across multiple events.
In a star schema, there can only be one dimension-level out from the fact table. Since the data can only have one level of dimension tables, it can have redundant information.
Denormalized data models may incur integrity and consistency violations, so replication must be handled accordingly.
Queries on star schemas will (usually) be faster than a snowflake schema because there are fewer joins. An example of a star schema is shown in Figure 1.
 |
|---|
| Figure 1: Star schema example |
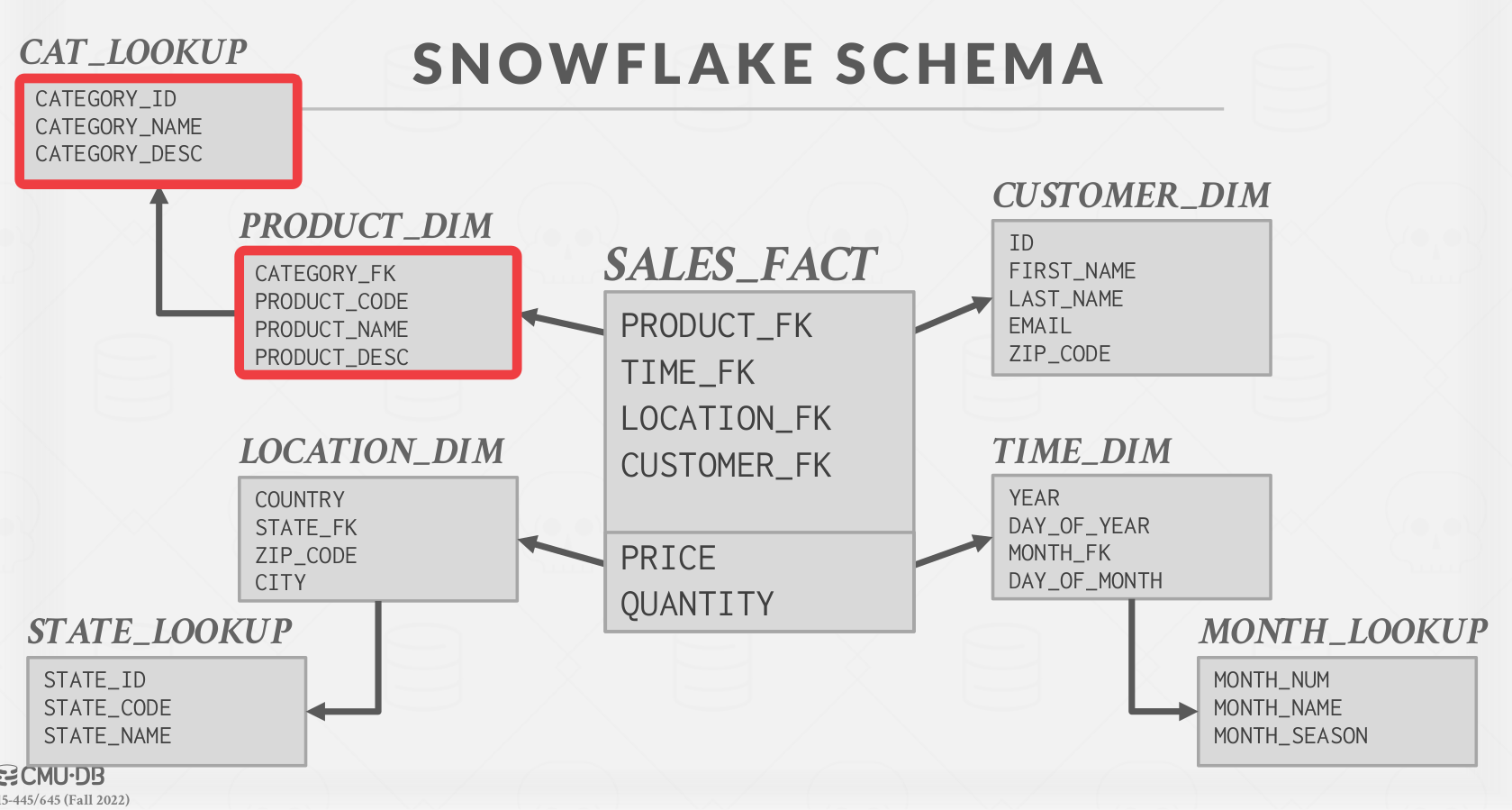
Snowflake Schema #
Snowflake schemas are similar to star schemas except that they allow for more than one dimension out from the fact table. They take up less storage space, but they require more joins to get the data needed for a query.
For this reason, queries on star schemas are usually faster. An example of a snowflake schema is shown in Figure 2
 |
|---|
| Figure 2: Snowflake schema example |
3. Execution modles #
A distributed DBMS’s execution model specifies how it will communicate between nodes during query execution. Two approaches to executing a query are pushing and pulling.
Problem setup #
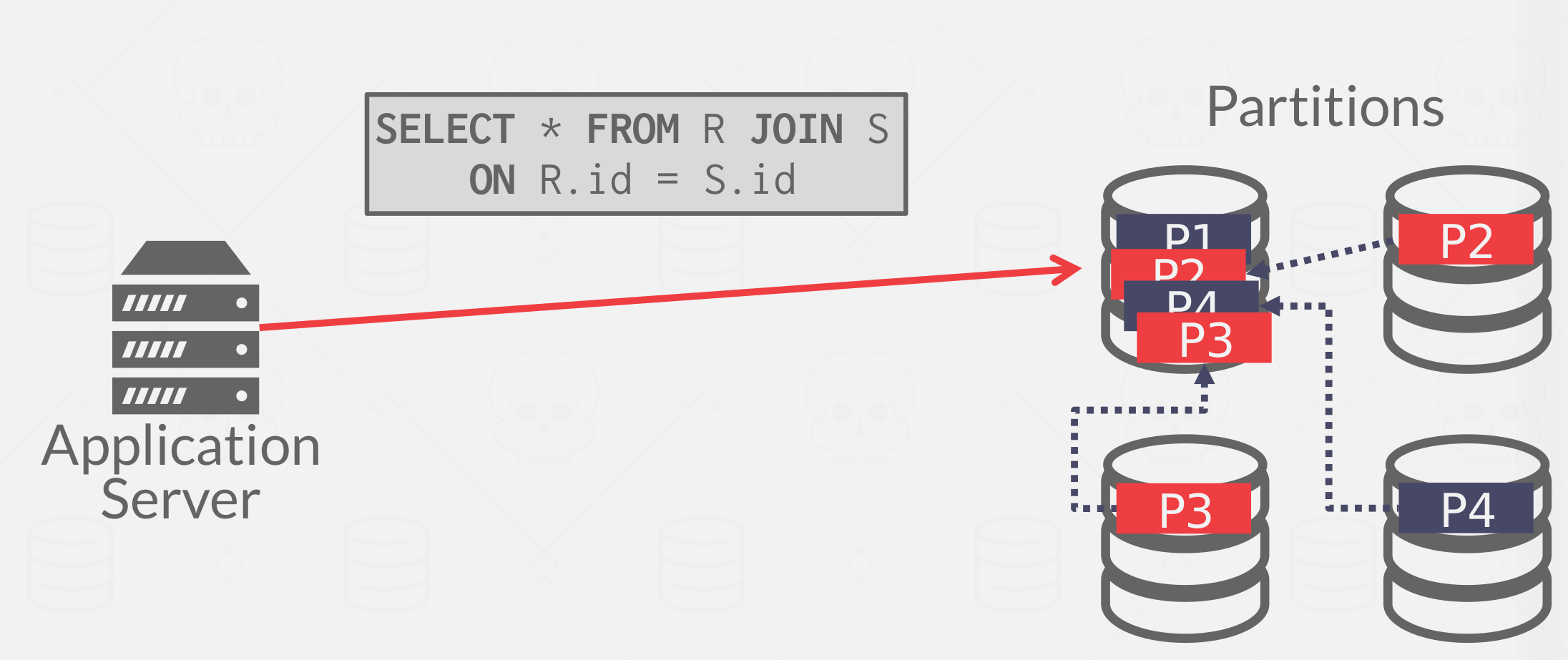
A major feature of the OLAP system is the capability to do the complex join, here is a problem setup shown in diagram Figure 3
 |
|---|
| Figure 3: Problem setup |
In this problem setup, we have an application server and a bunch of data, we want to run a join query that joins tables R and S, let’s say both of these two tables are partitioned on some column and we need a way to produce the joint result as if it was sitting on a single logical node although the data is partitioned on different nodes.
So the easiest thing we could do is just to take them from different partitions that are stored in different nodes and copy them or transfer them over the network to a central node then do the join on R & S and produce the result. it works and would be correct, but it obviously loses the point of having a distributed database because it is not taking advantage of these additional resources and it is also assuming the central node have enough memory or even a disk to store all these different partitions of data. So we need a way to execute the join query in a proper way.
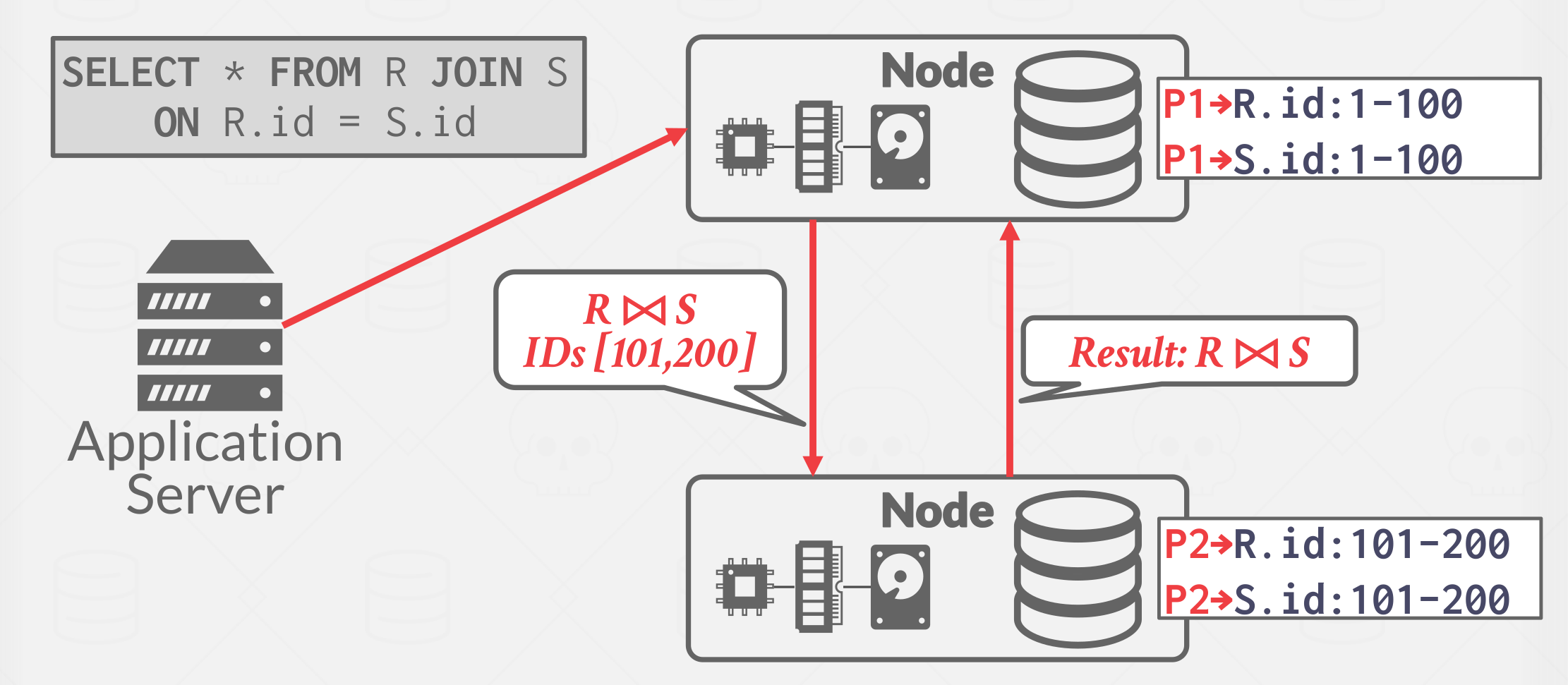
Pushing a Query to Data #
For the first approach, the DBMS sends the query (or a portion of it) to the node that contains the data. It then performs as much filtering and processing as possible where data resides before transmitting over network. The result is then sent back to where the query is being executed, which uses local data and the data sent to it, to complete the query. This is more common in a shared nothing system.
 |
|---|
| Figure 4: Push query to data |
Pulling Data to Query #
For the second approach, the DBMS brings the data to the node that is executing a query that needs it for processing. In other words, nodes detect which partitions of the data they can do computation on and pull from storage accordingly. Then, the local operations are propagated to one node, which does the operation on all the intermediary results. This is normally what a shared disk system would do. The problem with this is that the size of the data relative to the size of the query could be very different. A filter can also be sent to only retrieve the data needed from disk.
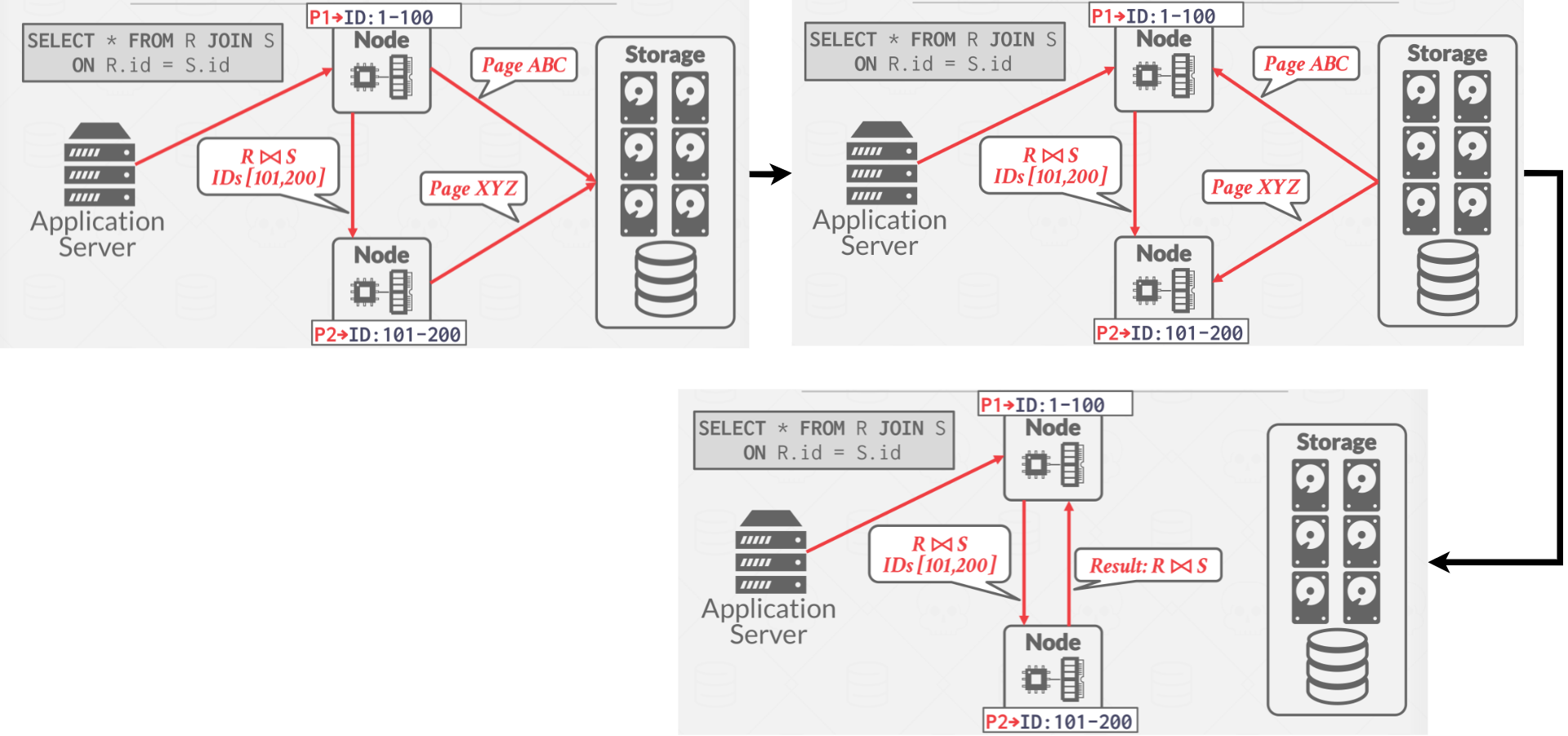 |
|---|
| Figure 5: Pulling query to data |
In the example in Figure 5 above, it is doing both pushing query to data from the top node to the bottom node and then each node then pulls the data from the shared disk storage does the process locally, and send the result up.
Query Fault Tolerance #
The data that a node receives from remote sources are cached in the buffer pool. This allows the DBMS to support intermediate results that are larger than the amount of memory available. Ephemeral pages, however, are not persisted after a restart. Therefore, a distributed DBMS must consider what happens to a long-running OLAP query if a node crashes during execution.
Most shared-nothing distributed OLAP DBMSs are designed to assume that nodes do not fail during query execution. If one node fails during query execution, then the whole query fails, which entails the entire query executing from the start. This can be expensive, as some OLAP queries can take days to execute.
The DBMS could take a snapshot of the intermediate results for a query during execution to allow it to recover if nodes fail. This operation is expensive, however, because writing data to disk is slow.
4. Query Planning #
All the optimizations that we talked about before are still applicable in a distributed environment, including
- Predicate pushdown,
- Early projections,
- And optimal join orderings.
Distributed query optimization is even harder because it must consider the physical location of data in the cluster and data movement costs.
One approach is to generate a single global query plan and then distribute physical operators to nodes, breaking it up into partition-specific fragments. Most systems implement this approach.
Another approach is to take the SQL query and rewrite the original query into partition-specific queries. This allows for local optimization at each node. SingleStore and Vitess are examples of systems that use this approach.
5. Distributed Algorithms #
For analytical workloads, the majority of the time is spent doing joins and reading from disk, showing the importance of this topic. The efficiency of a distributed join depends on the target tables’ partitioning schemes.
As we mentioned earlier in the Problem setup above, One approach is to put entire tables on a single node and then perform the join. However, the DBMS loses the parallelism of a distributed DBMS, which defeats the purpose of having a distributed DBMS. This option also entails costly data transfer over the network.
To join tables R and S, the DBMS needs to get the proper tuples on the same node. Once there, it then executes the same join algorithms discussed earlier in the semester. One should always send the minimal amount needed to compute the join, sometimes entailing entire tuples.
There are four scenarios for distributed join algorithms.
Scenario 1 #
One of the tables is replicated at every node and the other table is partitioned across nodes. Each node joins its local data in parallel and then sends their results to a coordinating node.
 |
|---|
| Figure 6: Scenario 1 |
Scenario 2 #
Both tables are partitioned on the join attribute, with IDs matching on each node. Each node performs the join on local data and then sends to a node for coalescing.
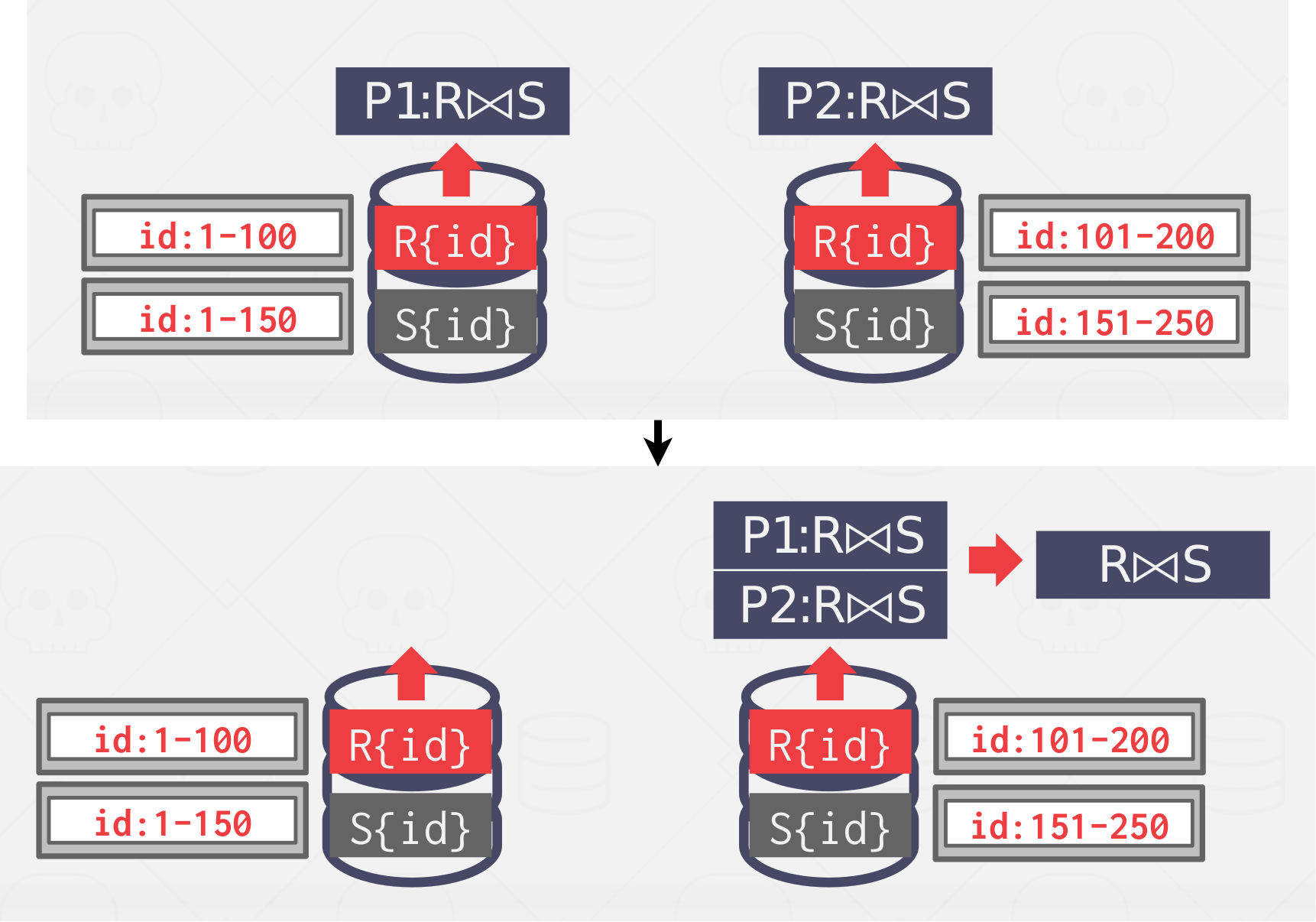 |
|---|
| Figure 7: Scenario 2 |
Scenario 3 #
Both tables are partitioned on different keys. If one of the tables is small, then the DBMS broadcasts that table to all nodes. This takes us back to Scenario 1. Local joins are computed and then those joins are sent to a common node to operate the final join. This is known as a broadcast join.
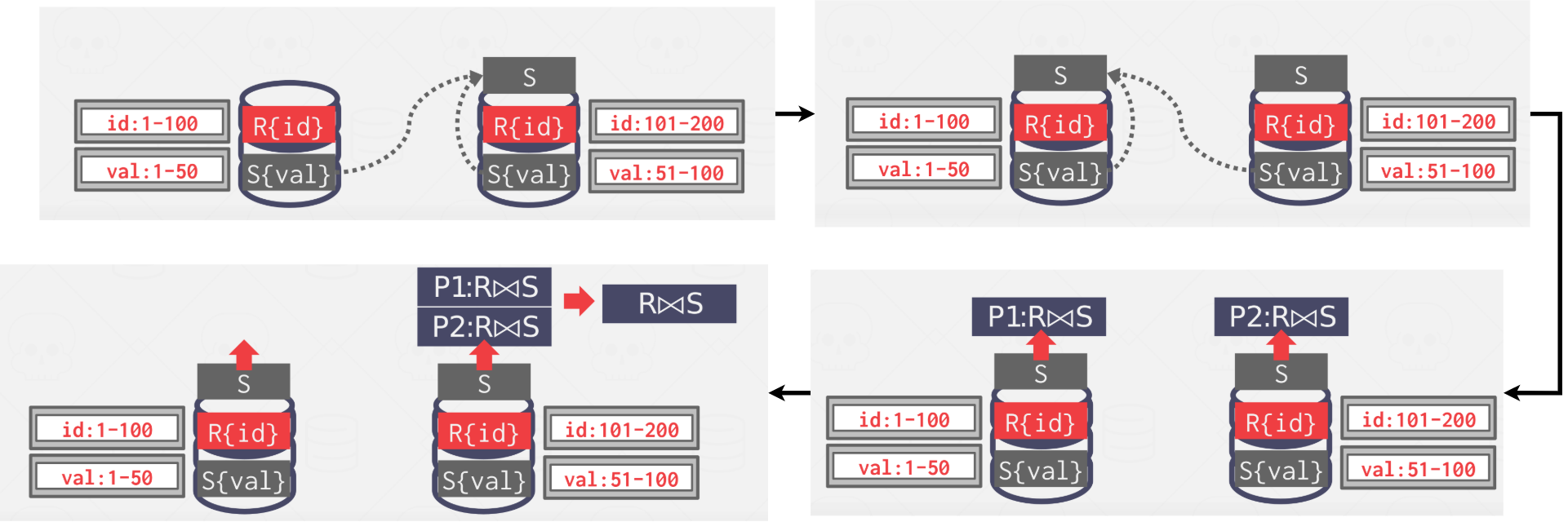 |
|---|
| Figure 8: Scenario 3 |
Scenario 4 #
This is the worst case scenario. Both tables are not partitioned on the join key. The DBMS copies the tables by reshuffling them across nodes. Local joins are computed and then the results are sent to a common node for the final join. If there isn’t enough disk space, a failure is unavoidable. This is called a shuffle join.
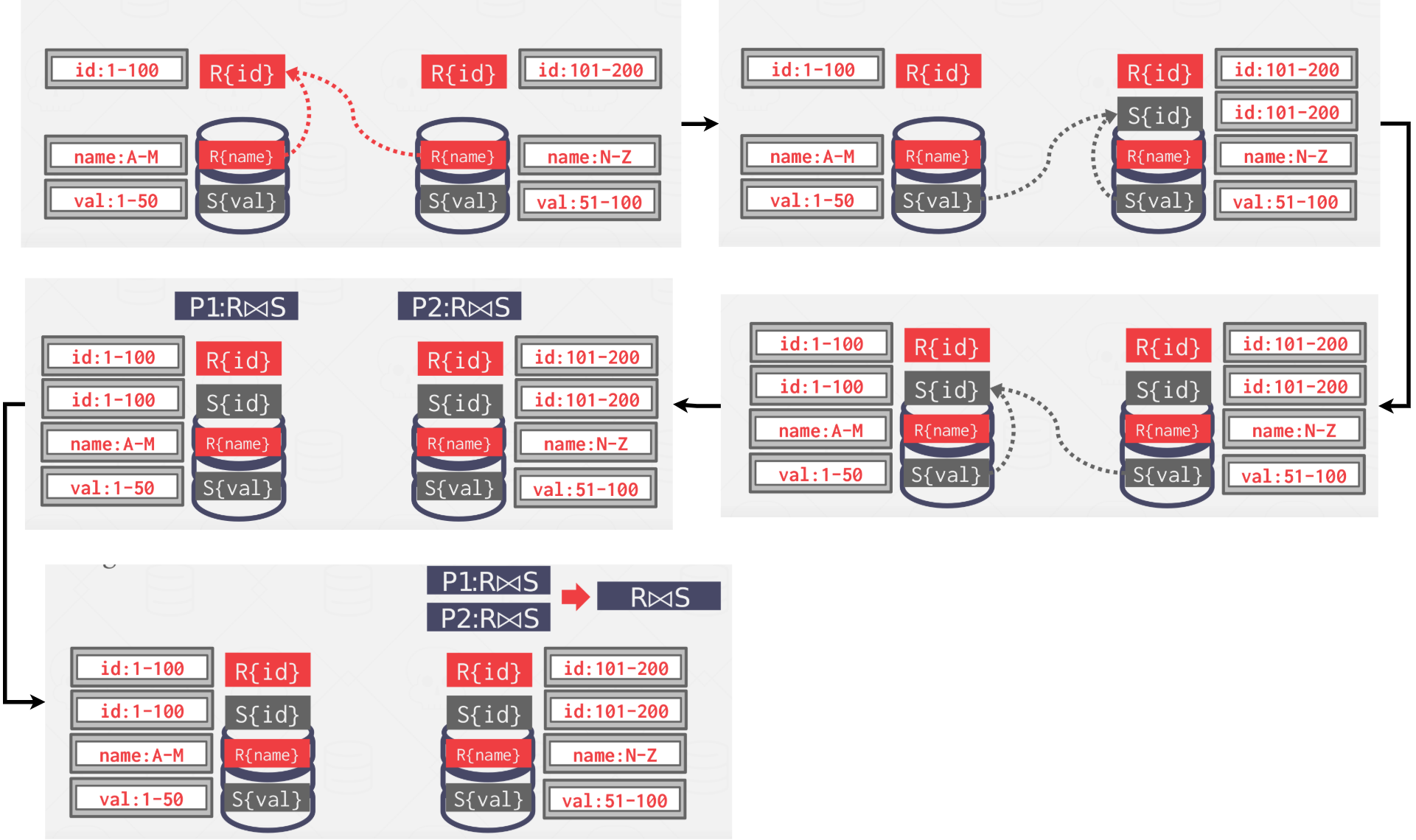 |
|---|
| Figure 9: Scenario 4 |
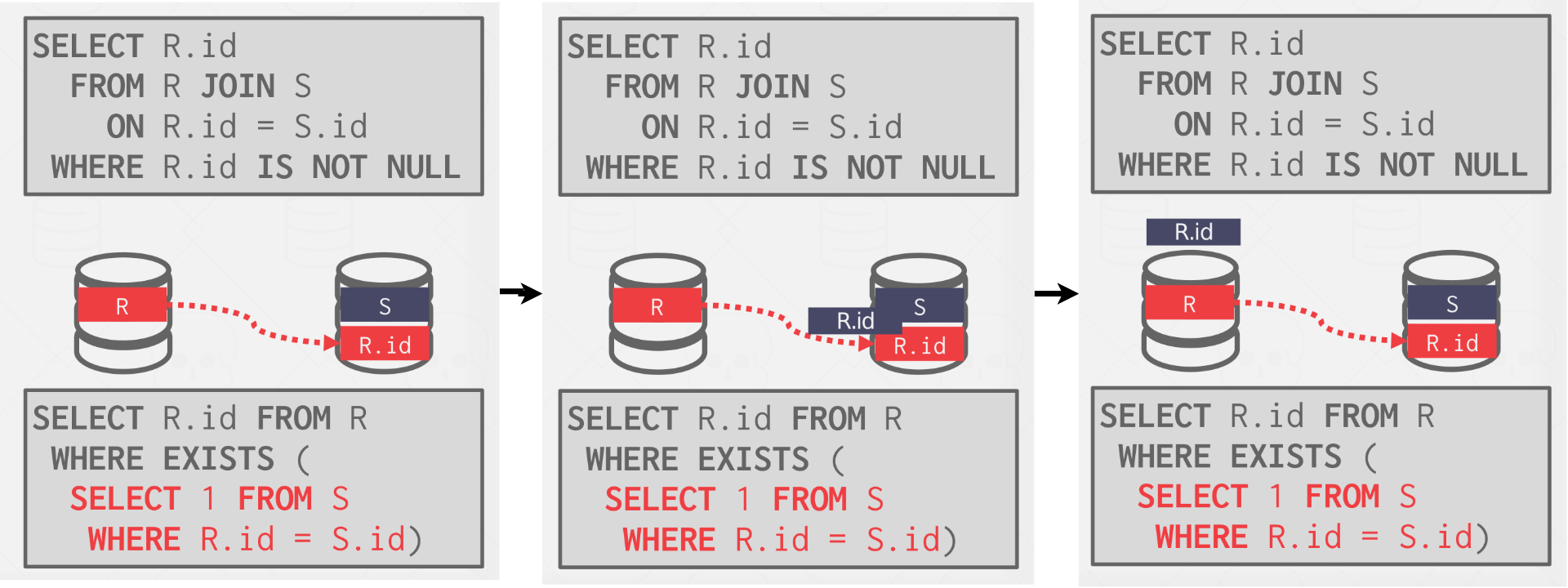
Semi-Join #
A semi-join is a join operator where the result only contains columns from the left table, it’s like a projection pushdown. Distributed DBMSs use semi-join to minimize the amount of data sent during joins.
 |
|---|
| Figure 10: Semi-Join |
It is like a natural join, except that the attributes on the right table that are not used to compute the join are restricted. Some DBMSs support SEMI JOIN SQL syntax. Otherwise DBMS fake it with EXISTS.
6. Cloud Systems #
Vendors provide database-as-a-service(DBaaS) offerings that are managed DBMS environments. The idea here is that instead of you spinning up your own ec2 instance downloading Postgres or MySQL and managing that yourself directly in the OS, the vendor will run the database system for you and give you a connection URL.
Newer system are starting to blur the lines between shared-nothing and shared-disk, For example, Amazon S3 allows for simple filtering before copying data to compute nodes. There are two types of cloud systems, managed or cloud-native DBMSs.
Managed DBMSs #
In a managed DBMS, no significant modification to the DBMS to be “aware” that it is running in a cloud environment. It provides a way to abstract away all the backup and recovery for the client. This approach is deployed in most vendors.
Cloud-Native DBMS #
A cloud-native system is designed explicitly to run in a cloud environment. This is usually based on a shared-disk architecture. This approach is used in Snowflace, Google BigQuery, Amazon Redshift, and Microsoft SQL Azure etc.
Cloud-native is not a scientific term, it’s more like a marketing term. Because the scientific term would usually define exactly the features it needs to support, But Cloud-native does not.
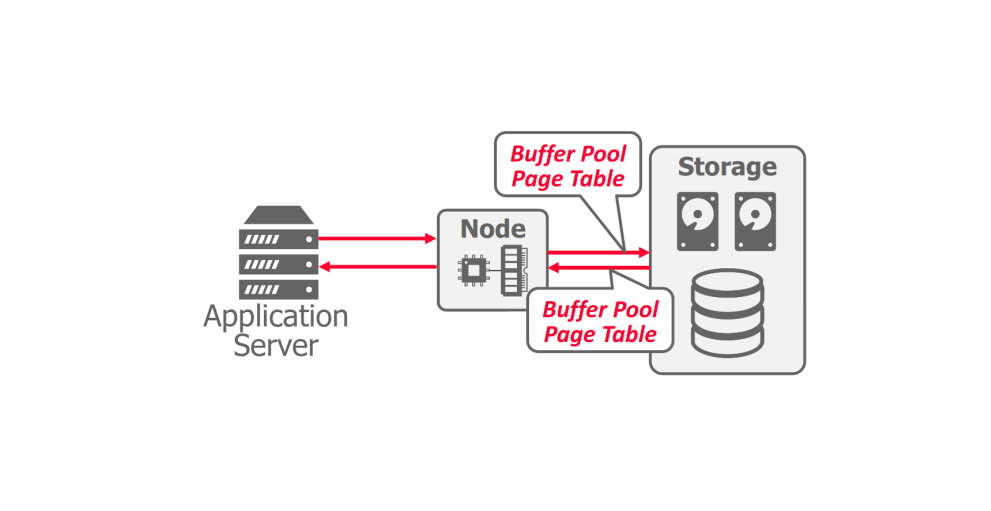
Serverless Database #
Rather than always maintaining compute resources for each customer, a serverless DBMS evicts tenants when they become idle, checkpointing the current progress in the system to disk. Now, a user is only paying for storage when not actively querying, A diagram of this is shown in Figure 11.
 |
|---|
| Figure 11: Serverless Database |
When the application server becomes idle, the user must pay for resources in the node that are not being used. In a serverless database, when the application server stops, the DBMS takes a snapshot of pages in the buffer pool and writes it out to shared disk so that the computation can be stopped. When the application server returns, the buffer pool page table restores the previous state in the node.
Data Lakes #
A Data Lake is a centralized repository for storing large amounts of structured, semi-structured, and unstructured data without having to define a schema or ingest the data into proprietary internal formats.
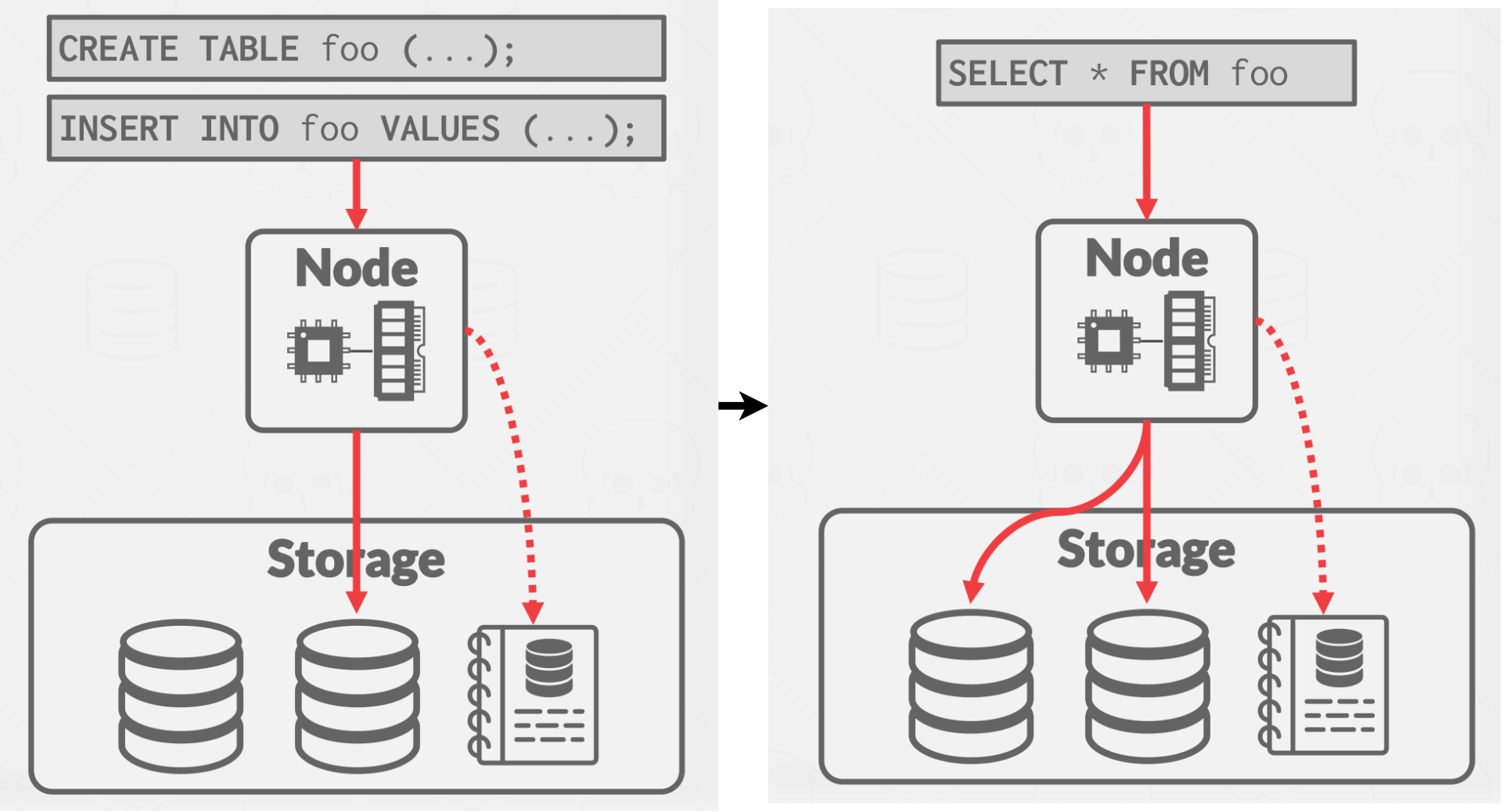
Without a Data Lake the kind of system we talked about so far in a data warehouse OLAP system, it looks like what shown in diagram Figure 12.
 |
|---|
| Figure 12: Data warehouse |
Before an application can put any data into the database, the application needs to call create table foo first, and it goes to the compute layer and updates the catalog, now the DBMS knows about the table foo’s columns, and types and will figure out where to store them on files or disk in the storage layer. Once the application has done that, it can calls insert, then the DBMS is going to look up in the catalog so that it knows the columns and types of information and where to store the new data, then the DBMS constructs the node to actually write things. Same thing for Select.
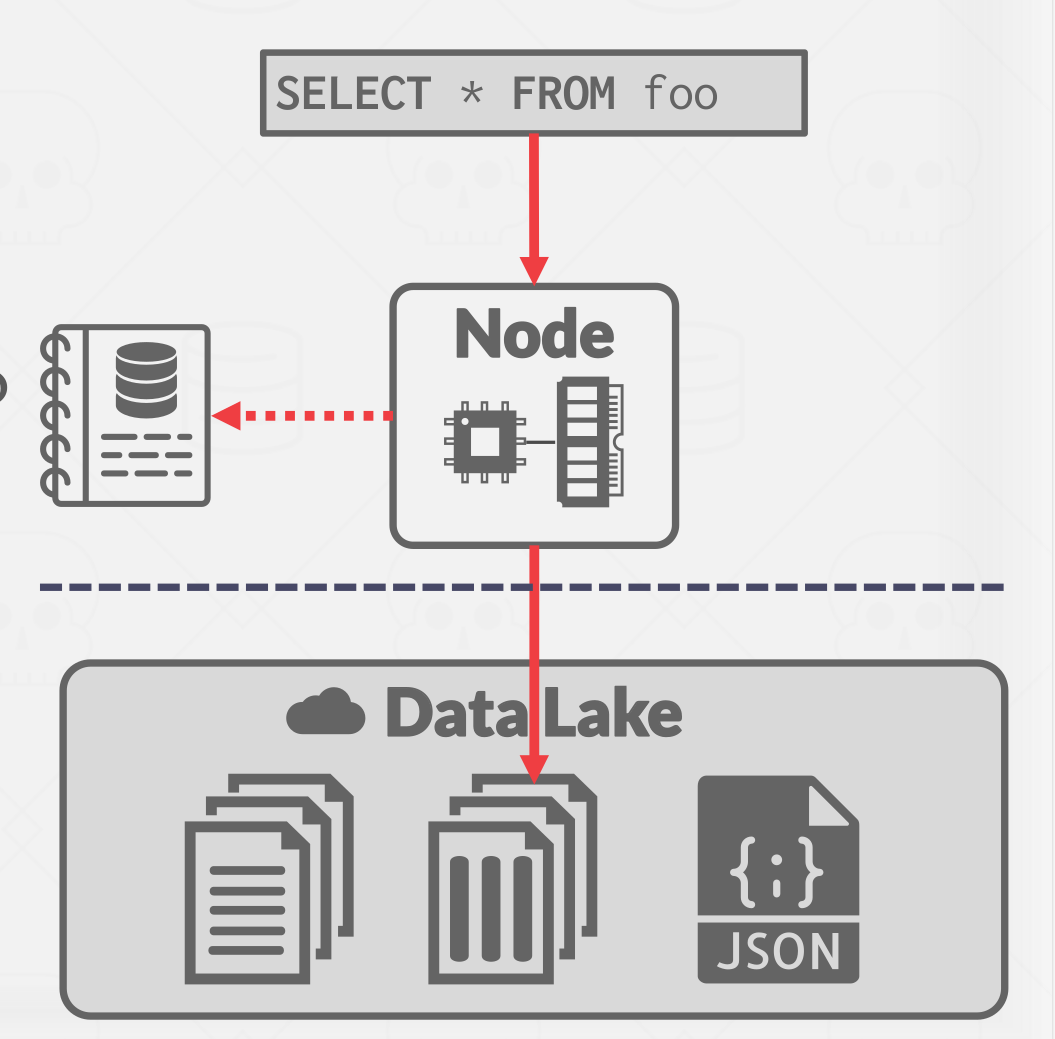
However in a Data Lake, the sort of structured storage layer goes away, when the Select query shows up, the Node may still be got to figure out somewhere from a catalog where the Foo’s location(maybe there is some information about what the schema is maybe there isn’t), the idea is to go this catalog and find the data location then get it. like what is shown in Figure 13.
 |
|---|
| Figure 13: Data Lake |
The simple takeaway are:
- Data Lake can store data without having to define a schema or ingest the data into proprietary internal formats
- Data lakes are usually faster at ingesting data, as they do not require transformation right away.
- They do require the user to write their own transformation pipelines.
7. Disaggregarted Components #
Many existing libraries/systems implement a single component of a distributed database. Distributed databases can then leverage these components instead of re-implementing it themselves. Additionally different distributed databases can share components with each other.
Notable examples are:
- System Catalogs: HCatalog, Google Data Catalog, Amazon Glue Data Catalog,
- Node Management: Kubernetes, Apache YARN, Cloud Vendor Tools
- Query Optimizers: Greenplum Orca, Apache Calcite
8. Universal Formats #
Most DBMSs use a proprietary on-disk binary file format for their database, The only way to share data between systems is to convert data into a common text-based format, including, CSV, JSON, and XML. There are new open-source binary file formats, which cloud vendors and distributed database systems support, that make it easier to access data across systems. Writing a custom file format would give way to better compression and performance, but this gives way to better interoperability.
Notable examples of universal database file formats:
- Apache Parquet: Compressed columnar storage from Cloudera/Twitter.
- Apache ORC: Compressed columnar storage from Apache Hive.
- Apache CarbonData: Compressed columnar storage with indexes from Huawei.
- Apache Iceberg: Flexible data format that supports schema evolution from Netflix.
- HDF5: Multi-dimensional arrays for scientific workloads.
- Apache Arrow: In-memory compressed columnar storage from Pandas/Dremio.