Distributed OLTP Databases #
A censorship circumvention tool may be required to open the links in this post from mainland of china.
1. Introduction #
What we’ve discussed so far in terms of the distributed database are:
- The DBMS system architecture: Shared-Memory, Shared-Disk, Shared-Nothing systems
- Partitioning/Sharding: e.g., Hash, Range, Round Robin
- Transaction coordination: Centralized vs. Decentralized
This class and the next class will talk about the distributed database in the context of OLAP and OLAP, so this class will focus on the OLTP system
On-line Transaction Processing(OLTP)
- Short lived read/write transactions.
- Small footprint
- Repetitive operations.
On-line Analytical Processing(OLAP)
- Long-running, read-only queries.
- Complex joins.
- Exploratory queries.
2. Distributed Transactions #
Continuing from the last class where we have distributed coordinator, we have not discussed how we decide which one to be the primary and how we can decide whether a transaction is safe to commit. At a high level, they are essentially the same problem because it is basically figuring out what should be the new state of the database be no matter whether that state is “which one is the primary” or “is the transaction allowed to commit”.
A transaction is “distributed” if it accesses data on multiple nodes. Executing these transactions is more challenging that single-node transactions because now when the transaction commits, the DBMS has to make sure that all the nodes agree to commit the transaction. The DBMS ensures that the database provides the same ACID guarantees as a single-node DBMS even in case of node failures, message delays, or message loss.
One can assume that all nodes in a distributed DBMS are well-behaved and under the same administrative domain. In other words, given that there is not a node failure, a node that is told to commit a transaction will commit the transaction. If the other nodes in a distributed DBMS cannot be trusted, then the DBMS needs to use a Byzantine Fault Tolerant protocol for transactions (e.g., blockchain)
3. Atomic Commit Protocols #
When a multi-node transaction finishes, the DBMS needs to ask all of the nodes involved whether it is safe to commit. Depending on the protocol, a majority of the nodes of all of the nodes may be needed to commit. Example protocols include:
- Tow-Phase Commit(Common)
- Three-Phase Commit(not used)
- Paxos(Common)
- Raft(Common)
- ZAB(Zookeeper Atomic Broadcast protocol, Apache Zookeeper)
- Viewstamped Replication(fist provably correct protocol)
Two-Phase Commit(2PC) #
Two-Phase Commit basically as it sounds, there are two phases, Prepare Phase and Commit Phase, A basic 2PC example is shown in Figure 1.
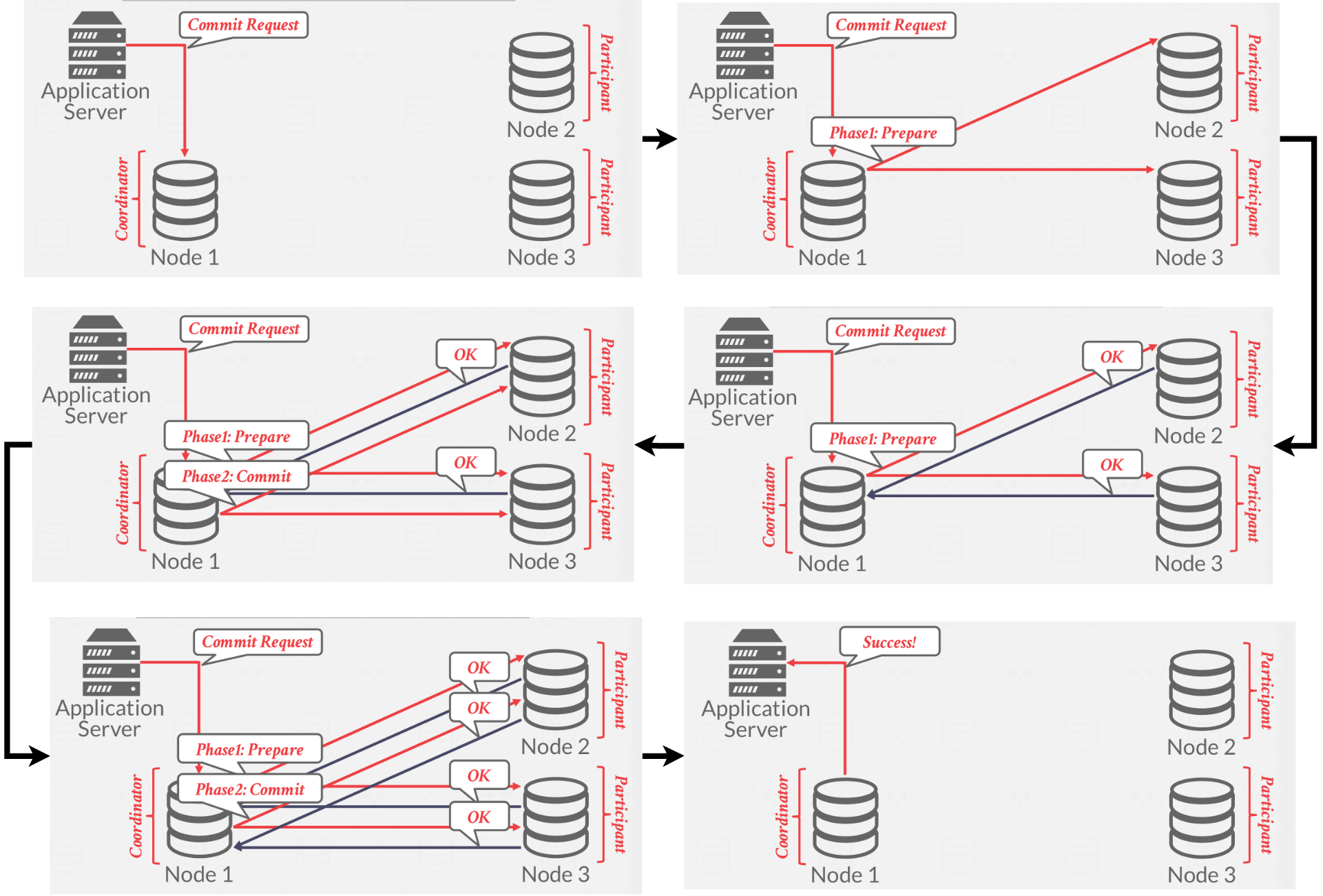 |
|---|
| Figure 1: A 2PC success example |
And a 2PC Abort example is shown in Figure 2.
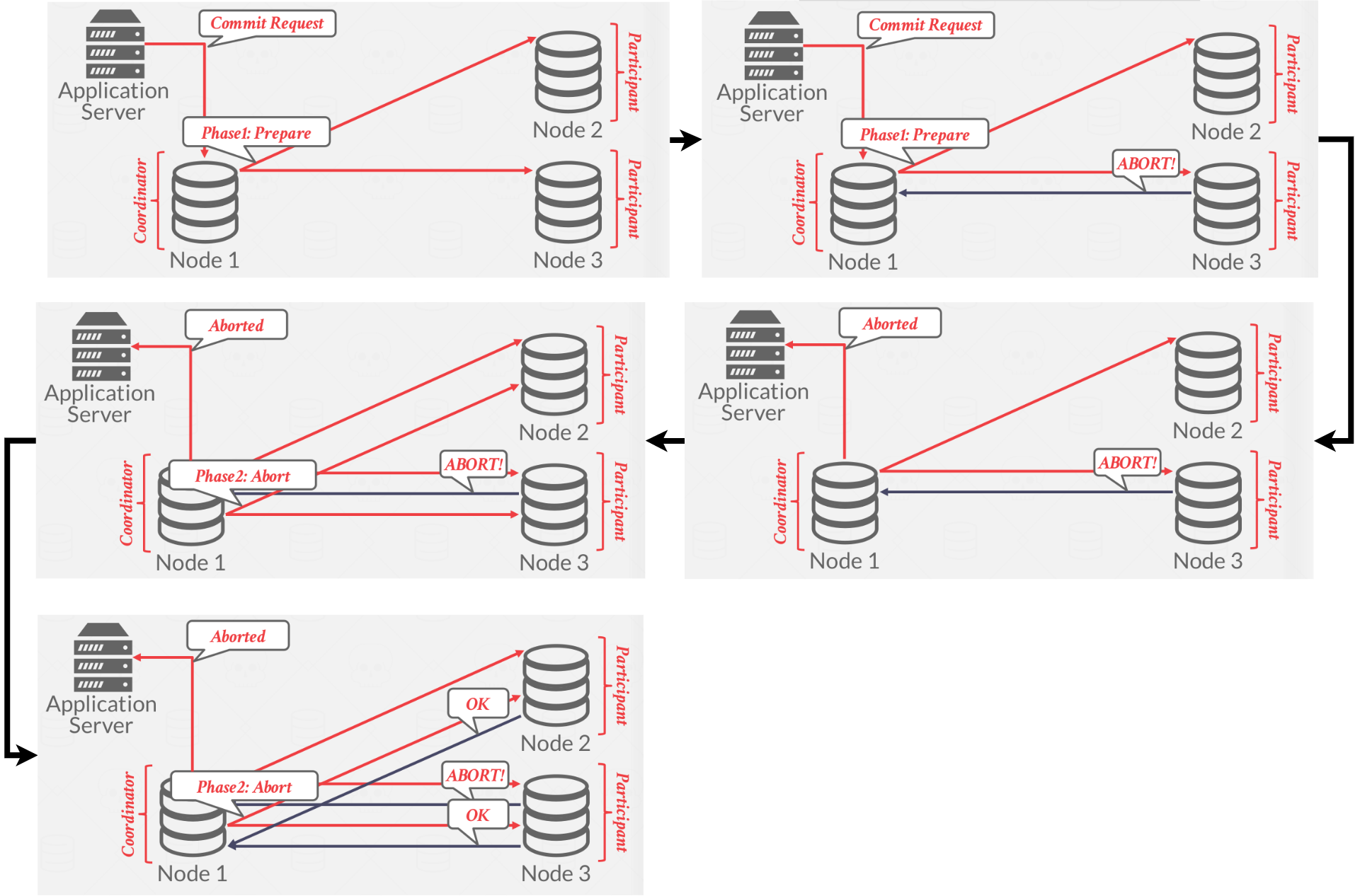 |
|---|
| Figure 2: A 2PC abort example |
The client sends a Commit Request to the coordinator. In the first phase of this protocol, the coordinator sends a Prepare message, essentially asking the participant nodes if the current transaction is allowed to commit. If a given participant verifies that the given transaction is valid, they send an OK to the coordinator. If the coordinator receives an OK from all participants, the system can now go into the second phase of the protocol. If anyone sends an Abort to the coordinator, the coordinator sends an Abort to the client immediately.
The coordinator sends a Commit to all the participants, telling those nodes to commit the transaction, if all the participants send an OK. Once the participants respond with an OK, the coordinator can tell the client that the transaction is committed. If the transaction was aborted in the first phase, the participants receive an Abort from the coordinator, to which they should respond with an OK. Either everyone commits or no one does.
The coordinator can also be a participant in the system.
Additionally, in the case of a crash, Each node keeps track of a non-volatile log of the inbound/outbound messages and the outcome of each phase. Nodes block until they can figure out the next course of action.
What happends if the coordinator crashes:
- Participants must decide what to do after a timeout. A safe option is just to abort. Alternatively, the nodes can communicate with each other to see if they can commit without the explicit permission of the coordinator.
- System is not available during this time.
What happends if participant crashes:
- The coordinator assumes that it responded with an abort if it has not sent an acknowledgment yet
- If the participant crashes at the Commit phase, the following scenarios may occur:
- The participant has not received the “commit” message: In this case, the participant doesn’t know if the transaction should be committed or not. Upon recovery, the participant can consult its logs to determine its vote during the Prepare Phase. If the participant had voted “yes,” it can contact the coordinator or other participants to find out the outcome of the transaction. The participant should commit the transaction if it is informed that the transaction was committed. If the participant cannot obtain the transaction’s outcome, it must keep the transaction in a prepared state until it receives further information.
- The participant has received the “commit” message but has not yet committed the transaction: Upon recovery, the participant can consult its logs to check the state of the transaction. If the participant finds that it was in the middle of the Commit Phase, it should commit the transaction, as all participants had already voted “yes” during the Prepare Phase.
- The participant has committed the transaction but has not yet sent an acknowledgment to the coordinator: After the crash and upon recovery, the participant should consult its logs to determine the transaction’s state. If the participant finds that the transaction was committed, it should send an acknowledgment to the coordinator, informing it of the successful commit.
- Again, nodes use a timeout to determine that the participant is dead.
The 2PC involves multiple network round trips and having to go with these round trips makes things really expensive and you may only commit few transactions a second if you’re always waiting for the network. So there are some optimizations we can take to speed thins up.
Early Prepare Voting(Rare):
If the DBMS sends a query to a remote node that it knows will be the last one executed there, then that node will also return their vote for prepare with the query result. This is rare because it’s hard to know if a query is the last one to execute on a node except for the store procedures.
Early Ack After Prepare(Common):
If all nodes vote to commit a transaction, the coordinator can send the client an acknowledgment that their transaction was successful before the commit phase finishes, This optimization aims to reduce latency, as the client does not need to wait for the completion of the Commit Phase. However, this optimization makes handling crashes during the Commit Phase more complex.
-
If a participant crashes after the commit message is acknowledged to the client, the following scenarios may occur:
-
The participant has not yet received the “commit” message: In this case, the participant is unaware that the transaction should be committed. Upon recovery, the participant should consult its logs to determine its vote during the Prepare Phase. If the participant had voted “yes,” it can contact the coordinator or other participants to find out the outcome of the transaction. The participant should commit the transaction if it is informed that the transaction was committed. If the participant cannot obtain the transaction’s outcome, it must keep the transaction in a prepared state until it receives further information.
-
The participant has received the “commit” message but has not yet committed the transaction: Upon recovery, the participant can consult its logs to check the state of the transaction. If the participant finds that it was in the middle of the Commit Phase, it should commit the transaction, as all participants had already voted “yes” during the Prepare Phase.
-
The participant has committed the transaction but has not yet sent an acknowledgment to the coordinator: After the crash and upon recovery, the participant should consult its logs to determine the transaction’s state. If the participant finds that the transaction was committed, it should send an acknowledgment to the coordinator, informing it of the successful commit.
-
-
If the coordinator crashes after the commit message is acknowledged to the client, the protocol should handle this situation to maintain consistency across all participating nodes. Upon recovery, the coordinator can follow these steps:
-
Check its logs: The coordinator should consult its logs to determine the state of the transaction. If the logs indicate that the transaction was in the Commit Phase, the coordinator knows that all participants had voted “yes” during the Prepare Phase.
-
Resend “commit” messages: If the coordinator finds that it was in the middle of the Commit Phase, it should resend the “commit” messages to all participants. This ensures that all participants are informed of the decision to commit the transaction.
-
Collect acknowledgments: The coordinator should wait for acknowledgments from all participants. If any participant has not yet acknowledged the “commit” message, the coordinator should resend the message as needed.
-
Complete the transaction: Once the coordinator has received acknowledgments from all participants, it can consider the transaction complete.
-
The key to handling coordinator/participant crashes during the Commit Phase in the Early Ack After Prepare optimization is to use logs and communication to maintain consistency across all nodes.
Paxos #
Paxos(along with Raft) is more prevalent in modern system than 2PC. 2PC is a degenerate case of Paxos; Paxos uses 2F + 1 coordinators and makes progress as long as at least F + 1 of them are working properly, 2PC sets F = 0.
Paxos is a consensus protocol where a coordinator proposes an outcome(e.g., commit or abort) and then the participants vote on whether that outcome should succeed. This protocol does not block if a majority of participants are avialable and has provably minimal messages delays in the best case. For Paxos, the coordinator is called proposer and participants are called acceptor. An simplified diagram of Paxos is shown in Figure 3.
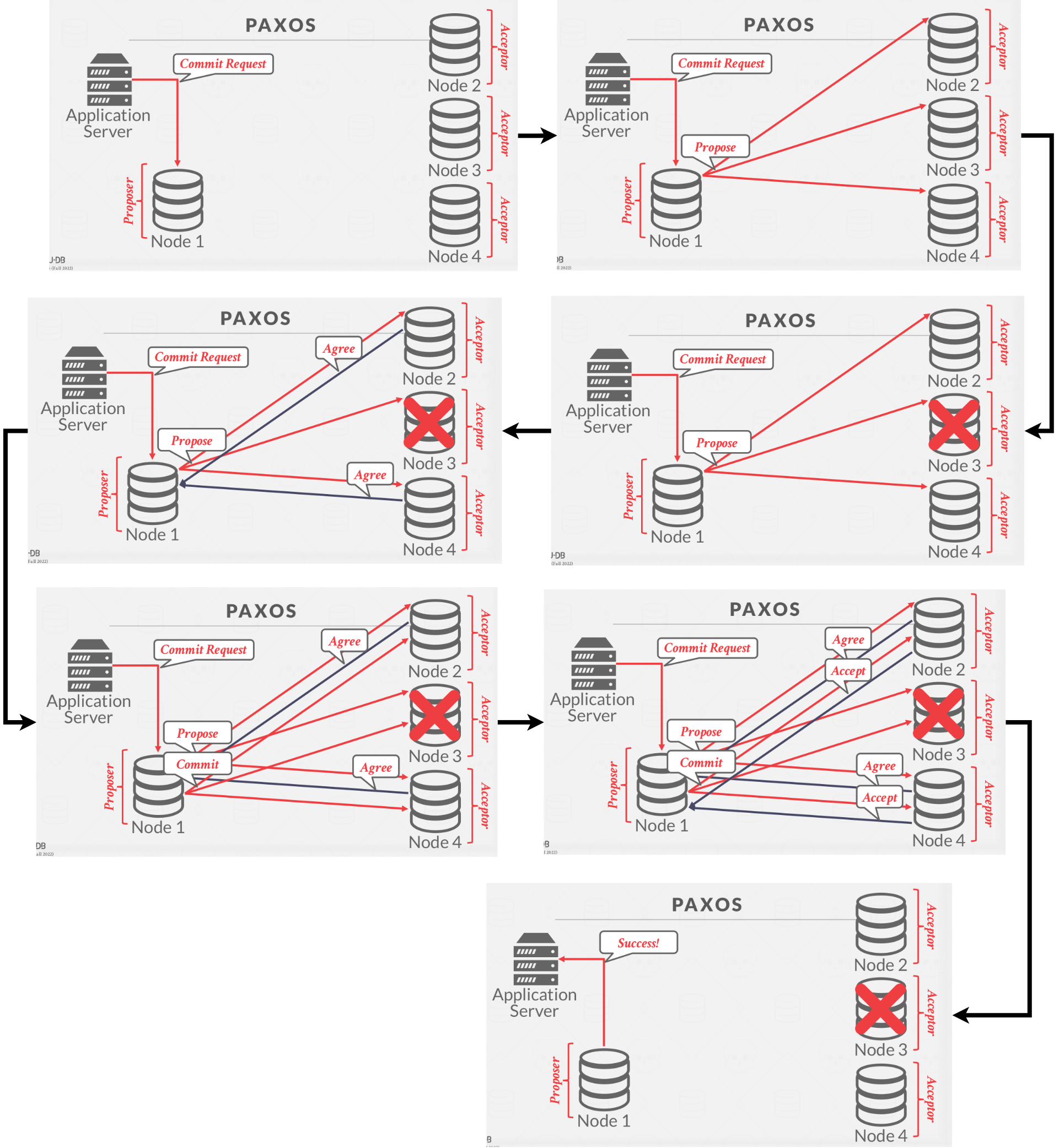 |
|---|
| Figure 3: Paxos |
And here is a time series diagram of how to run Paxos shown in Figure 4.
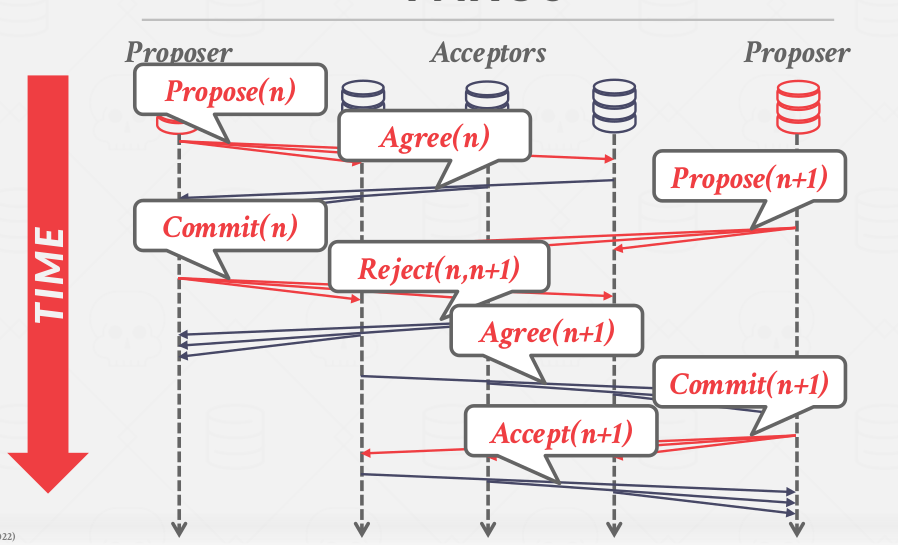 |
|---|
| Figure 4: Paxos time series view |
The client will send a Commit Request to the proposer. The proposer will send a Propose to the other nodes in the system, or the acceptors. A given acceptor will send an Agree if they have not already sent an Agree on a higher logical timestamp. Otherwide send a Reject.
Once the majority of the acceptors sent an Agree, the proposer will send a Commit. The proposer must wait to receive an Accept from the majority of acceptors before sending the final message to the client saying that the transaction is committed(Unlike 2PC with Early Ack After Prepare optimiztion).
To avoid dueling proposers, use exponential back-off times for trying to propose again after a failed proposal.
Multi-Paxos:
If the system elects a single leader that oversees proposing changes for some period, then it can skip the Propose phase(Fall back to full Paxos whenever there is a failure).
The DBMS periodically renews the leader(known as a lease) using another Paxos round, the nodes must exchange log entries during the leadership election to make sure that everyone is up-to-date.
Lease:
A lease can be considered a time-bounded lock in a distributed system. Leases grant temporary, exclusive access to a resource for a specified period, similar to a lock. However, unlike a traditional lock, a lease has a time limit associated with it, which helps manage resources and handle failures in a distributed system more effectively. When a client acquires a lease on a resource, it effectively holds a lock on that resource for the duration of the lease. Other clients cannot access the resource until the lease expires or is voluntarily released by the client holding the lease. This time-bounded nature of leases helps prevent deadlocks, ensures fair access to shared resources, and allows the system to detect and handle failures when a client becomes unresponsive or crashes.
2PC vs. Paxos
If the coordinator fails after the prepare message is sent, Tow-Phase Commit(2PC) blocks until the coordinator recovers. On the other hand, Paxos is non-blocking if a majority of participants are alive, provided that there is a sufficiently long period without further failures. If the nodes are in the same data center, do not fail often. and are not malicious, then 2PC is preferred over Paxos as 2PC usually results in fewer round trips.
4. Replication #
The DBMS can replicate data across redundant nodes to increase availability. In other words, if a node goes down the data is not lost, and the system is still alive and does not need to be rebooted. When designing the replication system, these are the descions that need to consider:
- Replica Configuraton: Primary-Replica or Multi-Primary
- Propagation Scheme: Synchronous or Asynchronous
- Propagation Timing: Continuous or On Commit
- Update Method: Active-Active or Active-Passive
Replica Configurations #
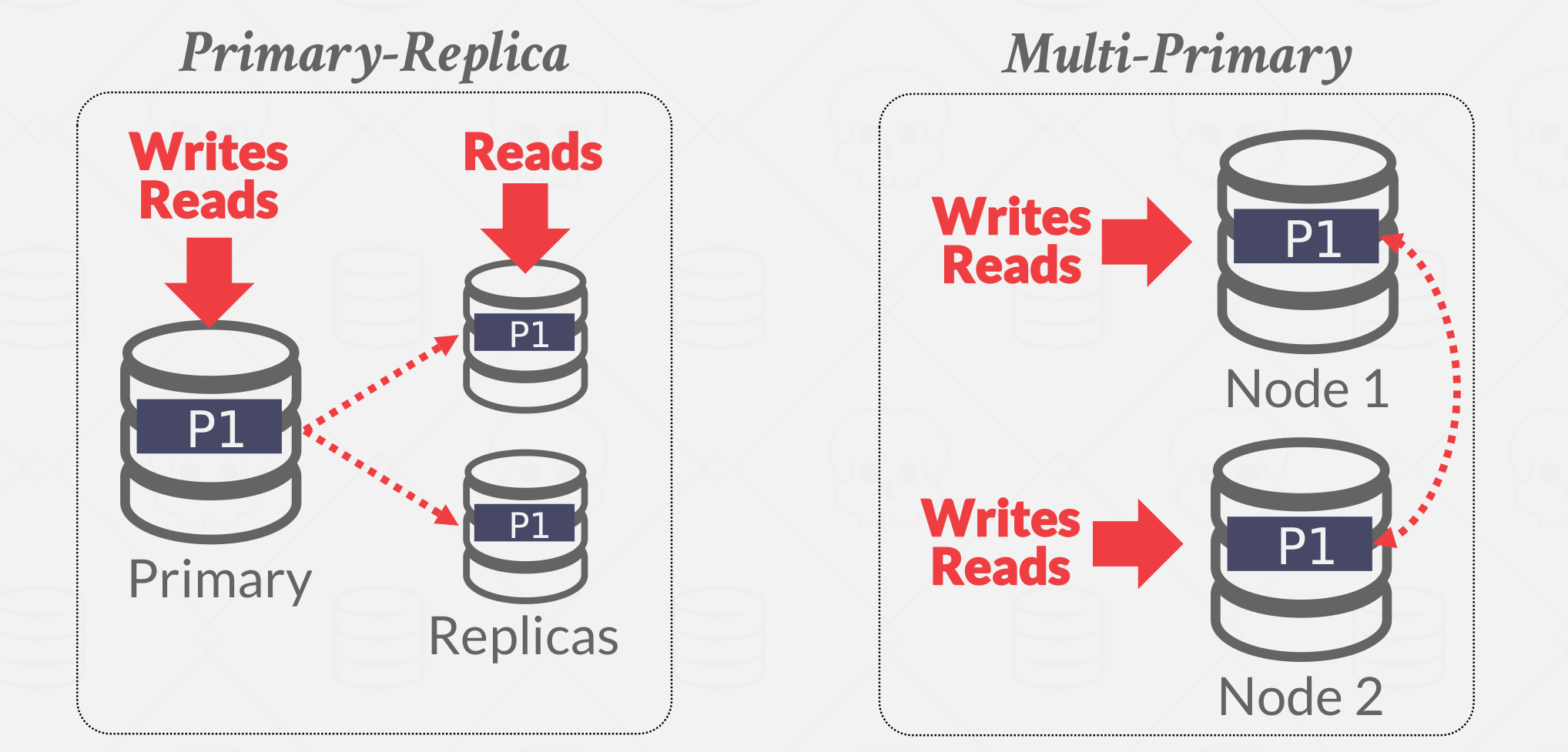
There are two approachs for the Replica Configurations, Primary-Replica and Multi-Primary configurations(shown in Figure 5).
 |
|---|
| Figure 5: Replica Configurations |
Primary-Replica:
- All updates to to a designated primary for each object.
- The primary propagates updates to its replicas without an atomic commit protocol.
- Read-only transactions may be allowed to access replicas.
- If the primary goes down, then hold an election to select a new primary.
Multi-Primary:
- Transactions can update data objects at any replica.
- Replicas must syncronize with each other using an atomic commit protocol like Paxos or 2PC.
Notice: Primary/Replica, Leader/Follower, Master/Slave(Might be found in some older articles) are interchangable.
K-Safety
K-safety is a threshold for determining the fault tolerance of the replicated database. The value K represents the number of replicas per data object that must always be available. If the number of replicas goes below this threshold, then the DBMS halts execution and takes itself offline. A higher value of K reduces the risk of losing data. It is a threshold to determine how available a system can be.
Propagation Scheme #
When a transaction commits on a replicated database, the DBMS decides whether it must wait for that transaction’s changes to propagate to other nodes before it can send the acknowledgment to the application client. There are propagation levels: synchronous(strong consistency) and asynchronous(eventual consistency).
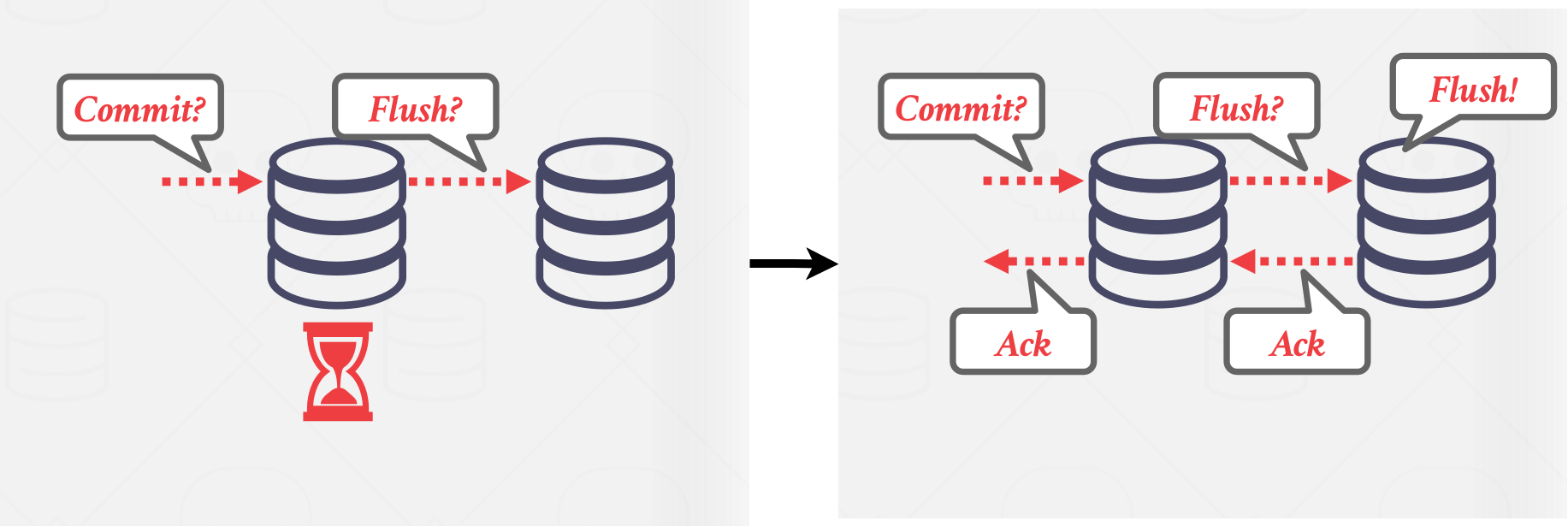
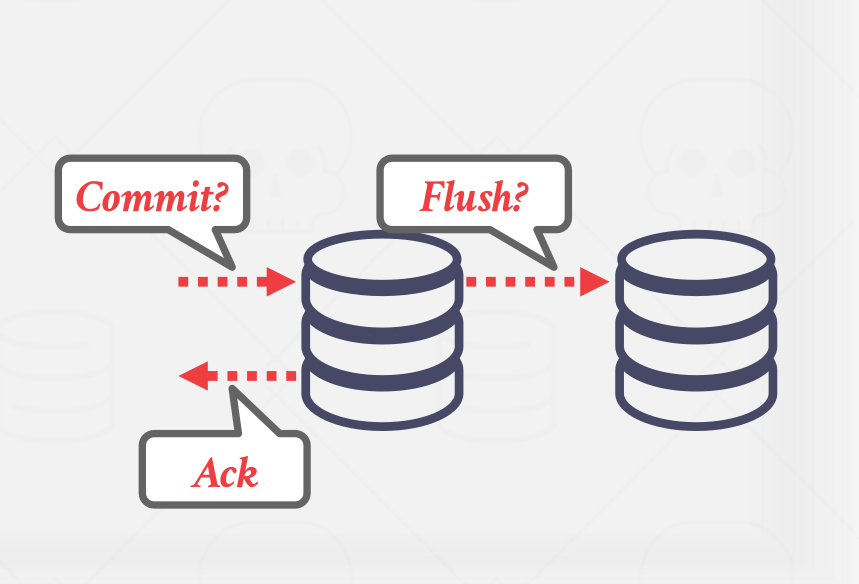
In a synchronous scheme, the primary sends updates to replicas and then waits for them to acknowledge that they fully applied(i.e., logged) the changes. Then the primary can notify the client that the update has succeeded. It ensures that the DBMS will not lose any data due to strong consistency. This is more common in a traditional DBMS. An exmaple diagram shown in Figure 6.
 |
|---|
| Figure 6: Synchronous propagation |
In an asynchronous schema, the primary immediately returns the acknowledgment to the client without waiting for replicas to apply the changes. Stale reads can occur in this approach, since updates may not be fully applied to replicas when the read is occurring. If some data loss can be tolerated, this option can be a viable optimization. This is commonly used in NoSQL systems. An example diagram is shown in Figure 7.
 |
|---|
| Figure 7: Asynchronous propagation |
Propagation Timing #
Propagation timing decides when the DBMS propagates updates to the replicas, There are two approaches: Continuous and On Commit.
For Continuous propagation timing, the DBMS sends log messages immediately as it generates them. Note that commit and abort messages also need to be sent. Most systems use this approach.
For on commit propagation timing, the DBMS only sends the log messages for a transaction to the replicas once the transaction is committed. This does not waste time sending log records for aborted transactions. It does make the assumption that a transaction’s log records fit entirely in memory.
Active vs. Passive #
There are multiple approaches to applying changes to replicas.
For Active-Active, a transaction executes at each replica independently. In the end, the DBMS needs to check whether the transaction ends up with the same result at each replica to see if the replicas are committed correctly. This is difficult since now the ordering of the transaction must sync between all the nodes, making it less common.
for Active-Passive, each transaction executes at a single location and propagates the overall changes to the replica. The DBMS can either send out the physical bytes that were changed, which is more common, or the logical SQL queries. Most systems are active-passive.
Notice:
-
Active-Passive vs. Primary-Replica: While both Active-Passive and Primary-Replica configurations offer high availability and fault tolerance, the main difference lies in the distribution of read operations. Primary-Replica configurations provide read scalability by allowing read operations to be processed by the replica nodes, whereas Active-Passive configurations do not.
-
Multi-Primary vs. Active-Passive: Multi-Primary configurations offer both read and write scalability, as well as high availability, but can be more complex to manage due to the need for conflict resolution. On the other hand, Active-Passive configurations focus primarily on fault tolerance and high availability, with no read scaling, and are generally easier to manage. The choice between these two configurations depends on the specific requirements of your system, such as the desired level of scalability, fault tolerance, and ease of management.
-
Multi-Primary vs. Active-Active: Both Multi-Primary and Active-Active configurations involve multiple nodes that actively process client requests to provide high availability, fault tolerance, and load balancing. The main difference lies in the context in which these terms are used. Multi-Primary configurations are more commonly associated with databases, where multiple nodes can process write operations and require conflict resolution mechanisms. Active-Active configurations, on the other hand, can be applied to a wider range of systems and may involve either independent nodes or nodes that share data and require synchronization.
Google Spanner as an Example #
Google Spanner is Google’s geo-replicated DBMS that released after 2011.
- Schematized, semi-relational data model
- Decentralized share-disk architecture.
- Log-structured on-disk storage.
- Concurrency Control: Strict 2PL + MVCC + Multi-Paxos + 2PC; Externally consistent global write-transactions with synchronous replication; Lock-free read-only transactions.
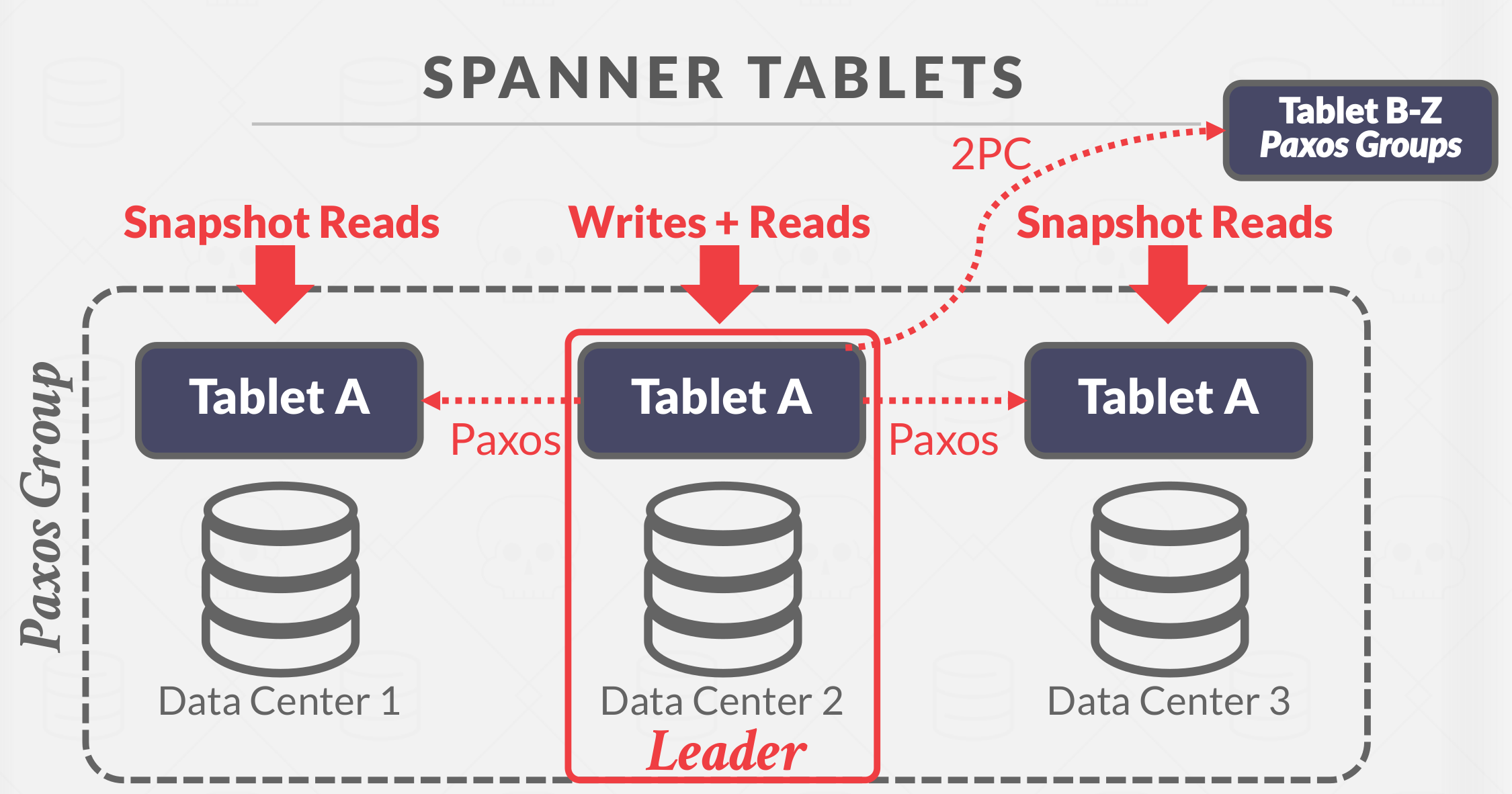
Here is a Simplified Spanner Concurrency Control diagram shown in Figure 8.
 |
|---|
| Figure 8: Simplified Spanner Concurrency Control |
Spanner Database is broken up into tablets(partitions):
- Use Paxos to elect leader in tablet group.
- Use 2PC for transactions that span tablets.
5. CAP Theorem #
The CAP Theorem, proposed by Eric Brewer and later proved in 2002 at MIT, explained that it is impossible for a distributed system to always be Consistent, Available and Partition Tolerant. Only two of these three properties can be chosen.
Consistency: Every read receives the most recent write or an error. Consistency is synonymous with linearizability for operations on all nodes. Once a write completes, all future reads should return the value of that write applied or a later write applied. Additionally, once a read has been returned, future reads should return that value or the value of a later applied write. NoSQL systems compromise this property in favor of the latter two. Other systems will favor this property and one of the latter two.
Availability: Every request receives a non-error response, without the guarantee that it contains the most recent write. Availability is the concept that all nodes that are up can satisfy all requests.
Partition tolerance: The system continues to operate despite an arbitrary number of network partitions between nodes. Partition tolerance means that the system can still operate correctly despite some message loss between nodes that are trying to reach a consensus on values. If consistency and partition tolerance is chosen for a system, in a CP system, not every request is guaranteed to receive a non-error response. During a network partition, the system may choose to reject requests to maintain consistency, making some nodes or portions of the system temporarily unavailable. In another word, updates will not be allowed until a majority of nodes are reconnected, typically done in traditional or NewSQL DBMS.
There is a modern version that considers consistency vs. latency trade-offs: PACELC theorem. It expands upon the CAP theorem by considering the trade-offs between consistency and latency in distributed systems, both during normal operation (when there are no network partitions) and during network partitions. PACELC stands for:
Partition (P): When a partition occurs (network failure between nodes), the system must choose between availability (A) and consistency (C), just like in the CAP theorem. Else (E): When there are no partitions (normal operation), the system must choose between latency (L) and consistency (C).
The PACELC theorem highlights the additional trade-offs between latency and consistency during normal operation, emphasizing that even in the absence of network partitions, there are still important decisions to be made in the design of a distributed system. See PACELC theorem