Introduction to Distributed Databases #
A censorship circumvention tool may be required to open the links in this post from mainland of china.
1. Indroduction #
Distributed DBMS (Database Management System) aims to solve several problems that arise in scenarios where a centralized DBMS may not be sufficient or efficient. The primary problems that a distributed DBMS tries to address include:
-
Scalability: As the volume of data and the number of users grow, a centralized DBMS may struggle to provide adequate performance. A distributed DBMS can distribute data and processing loads across multiple nodes or locations, allowing the system to scale more easily and handle increased workloads.
-
Availability and fault tolerance: A single point of failure in a centralized DBMS can lead to system downtime and data loss. In a distributed DBMS, data is often replicated across multiple nodes, ensuring that if one node fails, the data remains accessible from other nodes. This redundancy increases the system’s reliability and fault tolerance.
-
Geographic distribution: In some cases, it’s necessary to store and process data close to its source or users to reduce latency and improve performance. A distributed DBMS enables the distribution of data across multiple geographically dispersed locations, providing faster access to data for users in different regions. Additionally, some industries are subject to data residency or data sovereignty regulations that require data to be stored within specific geographic locations or jurisdictions. A distributed DBMS can help organizations comply with these requirements by distributing data across multiple locations as needed.
Difference between parallel and distributed DBMSs:
Parallel Database:
- Nodes are physically close to each other.
- Nodes are connected via high-speed LAN(fast, reliable communication fabric)
- The communication cost between nodes is assumed to be small. As such, one does not need to worry about nodes crashing or packets getting dropped when designing internal protocols.
Distributed Database:
- Nodes can be from each other.
- Nodes are potentially connected via a public network, which can be slow and unreliable.
- The communication cost and connection problems cannot be ignored(i.e., nodes can crash, and packets can get dropped).
2. System architectures #
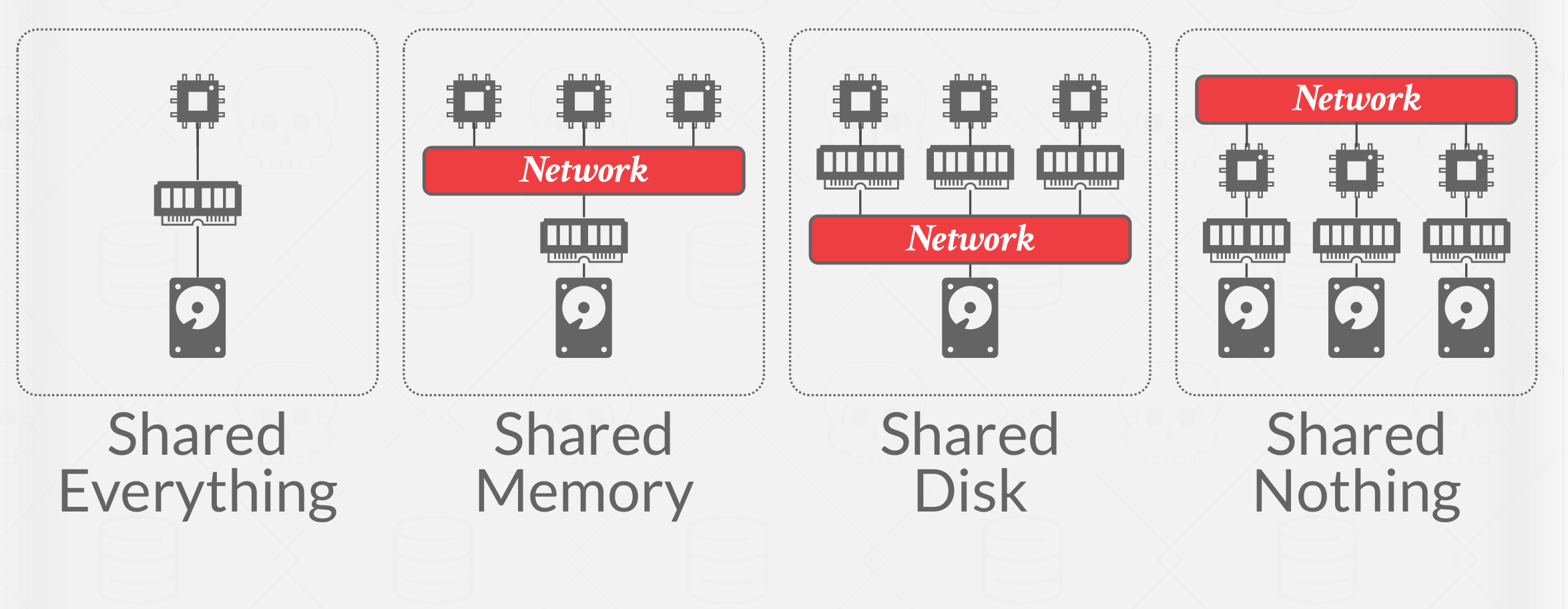
A DBMS’s system architecture specifies what shared resources are directly accessible to CPUs. It affects how CPUs coordinate with each other and where they retrieve and store objects in the database.
A single-node DBMS uses what is called a shared everything architecture. This single node executes workers on a local CPU(s) with its own local memory address space and disk.
 |
|---|
| Figure 1: DBMS Architectures |
Shared Memory #
An alternative to shared everything architecture in a distributed system is shared memory. CPUs have access to common memory address space via a fast interconnect. CPUs also share the same disk.
In practice, most DBMSs do not use this architecture, as it is provided at the OS/Kernel level. It also causes problems, since each process’s scope of memory is the same memory address space, which can be modified by multiple processes.
Each processor has a global view of all the in-memory data structures. Each DBMS instance on a processor has to “know” about the other instances.
Shared Disk #
In a shared disk architecture, all CPUs can read and write to a single logical disk directly via a interconnect, but each have their own private memories. The local storage on each compute node can act as a cache. This approach is more common in cloud-based DBMSs.
The DBMS’s execution layer can scale independently from the storage layer. Adding new storage nodes or execution nodes does not affect the layout or location of data in the other layer.
Nodes must send messages between them to learn about other nodes’ current state, That is since memory is local if data is modified, changes must be communicated to other CPUs in the case that piece of data is in memory for the other CPUs.
Nodes have their own buffer pool and are considered stateless. A node crash does not affect the state of the database since that is stored separately on the shared disk. The storage layer persists the state in the case of crashes.
Shared Nothing #
In a shared nothing environment, each node has its own CPU, memory, and disk. Nodes only communicate with each other via network. Before the rise of cloud storage platforms, the shared nothing architecture used to be considered the correct way to build distributed DBMSs.
It is more difficult to increase capacity in this architecture because the DBMS has to physically move data to new nodes. It is also difficult to ensure consistency across all nodes in the DBMS, since the nodes must coordinate with each other on the state of transactions. The advantage, however, is that shared nothing DBMSs can potentially achieve better performance and are more efficient than other types of distributed DBMS architectures.
3. Design Issues #
Distributed DBMSs aim to maintain data transparency, meaning that users should not be required to know where data is physically located, or how tables are partitioned or replicated. The details of how data is being stored is hidden from the application. In other words, a SQL query that works on a single-node DBMS should work the same on a distributed DBMS.
The key design questions that distributed database systems must address are the following:
- How does the application find data?
- How should queries be executed on a distributed data? Should the query be pushed to where the data is located? Or should the data be pulled into where the query is executed on?
- How does the DBMS ensure correctness, e.g, how to ensure that all nodes agree to commit a txn and then to make sure it does commit if we decide that it should.(this will be duscussed next class)
- How do we divide the database across resources?
Another design decision to make involves deciding how the nodes will intetact in their clusters. Two options are homogeneous and heterogeneous nodes, which are both used in modern-day systems.
-
Homogeneous Nodes: Every node in the cluster can perform the same set of tasks(albeit on potentially different partitions of data), lending itself well to a shared nothing architecture. This makes provisioning and failover “easier”. Failed tasks are assigned to available nodes.
-
Heterogeneous Nodes: Nodes are assigned specific tasks, so communication must happen between nodes to carry out a given task. Can allow a single physical node to host multiple “virtual” node types for dedicated tasks. Can independently scale from one node to other. MongoDB is an example of this approach which is shown in Figure 2.
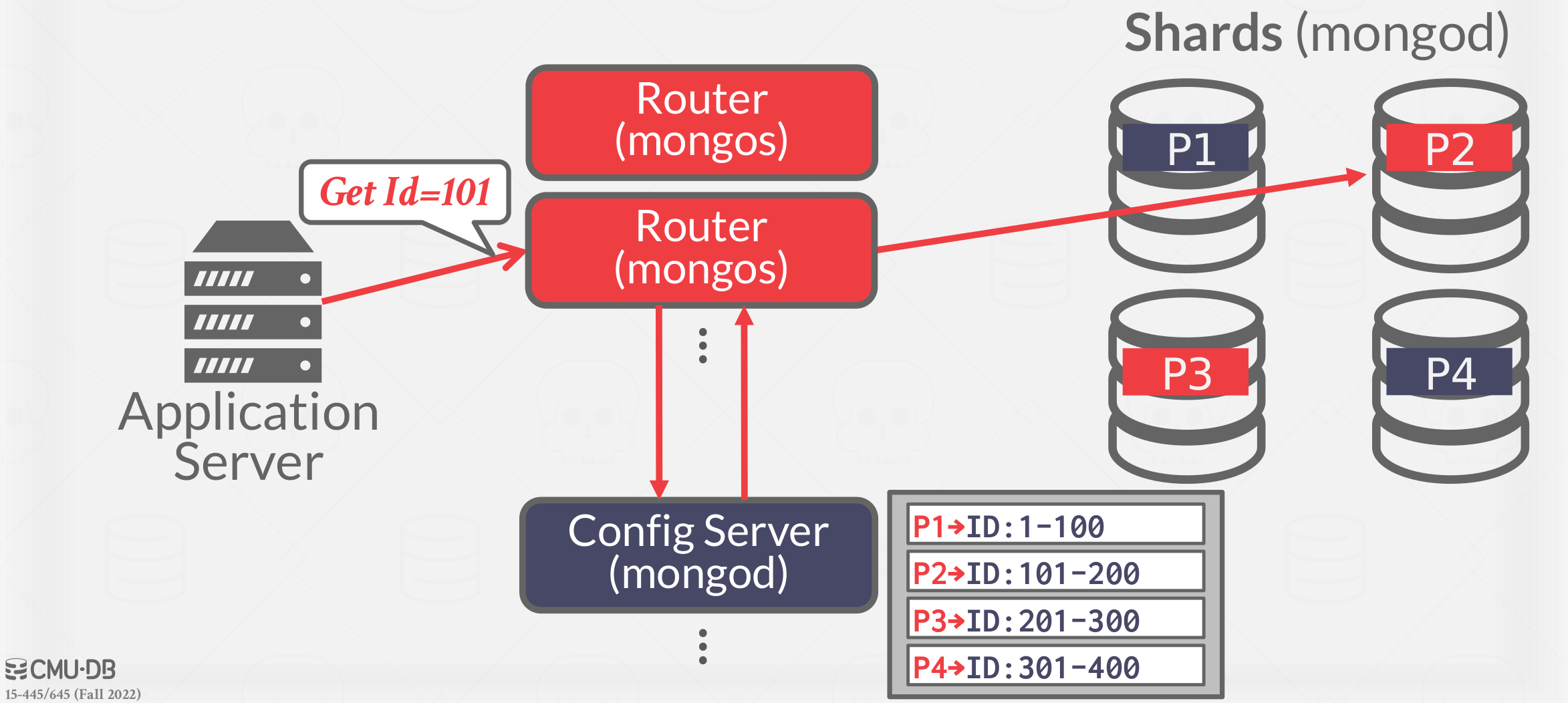 |
|---|
| Figure 2: MongoDB as Heterogeneous Nodes example |
Notice: In practice, developers need to be aware of the communication costs of queries to avoid excessively “expensive” data movement.
4. Partitioning Schemes #
Distributed system must partition the database across multiple resources, including disks, nodes, processors. This process is somtimes called sharding in NoSQL systems.
When the DBMS receives a query, it first analyzes the data that the query plan needs to access. The DBMS may potentially send fragments of the query plan to different nodes, then combines the results to produce a single anwser.
The goal of a partitioning scheme is to maximize single-node transactions, or transactions that only access data contained on one partition. This is allows the DBMS to not need to coordinate the behavior of concurrent transactions running on other nodes. On the other hand, a distributed transaction accesses data at one of more partitions would require expensive coordination.
The DBMS can partition a database physically(shared nothing) or logically(shared disk).
Naive Partitioning #
The simplest way to partition tables is naive data partitioning
- Assign an entire table to a single node.
- Assumes that each node has enough storage space for an entire table.
This is easy to implement because a query is just routed to a specific partitioning. However, this can be bad, since it is not scalable. One partition’s resouces can be exhausted if that one table is queried on often, not using all nodes available. See Figure 3 for an example.
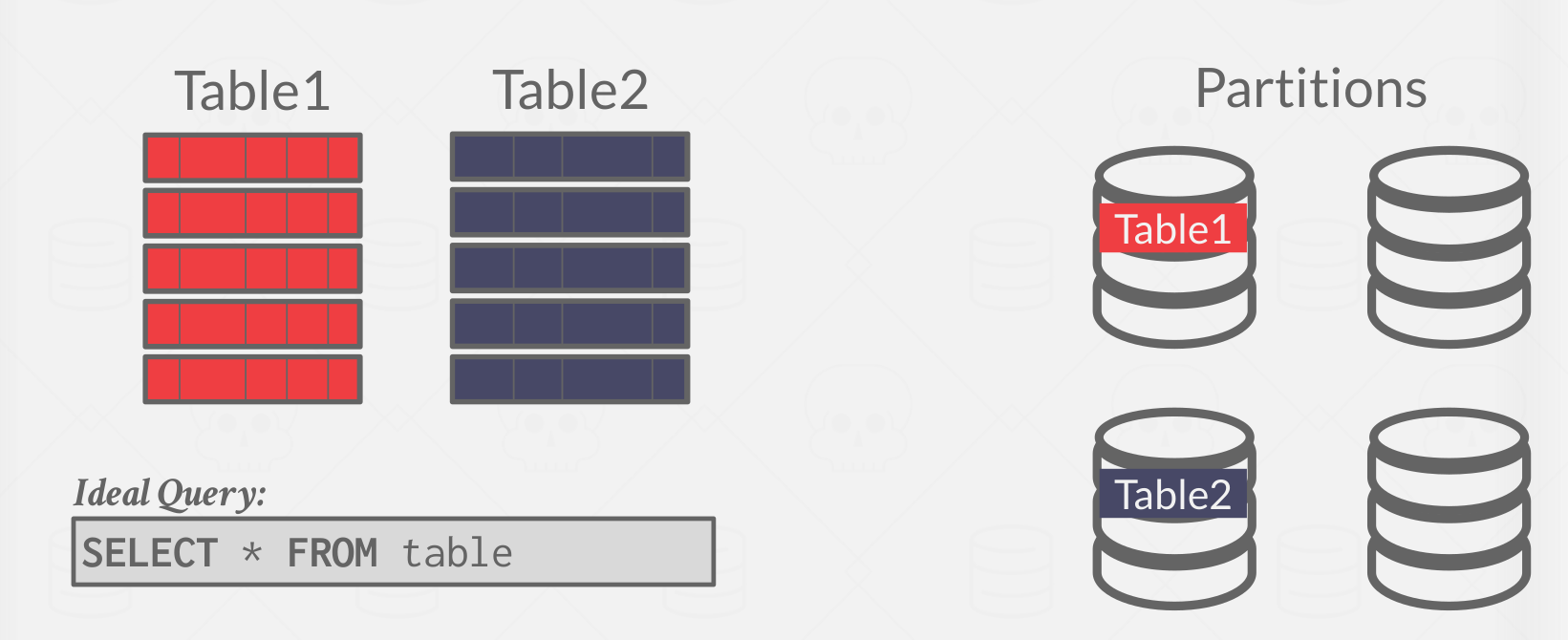 |
|---|
| Figure 3: Naive Partitioning example |
Vertical Partitioning #
Another way of partitioning is vertical partitioning, which split a table’s attributes into separate paritions.
Each partition must aldo store tuple information for reconstructing the original record.
 |
|---|
| Figure 4: Verticale Partitioning example |
Horizontal Partitioning #
The more commonly used is horizontal Partitioning. which splits a table’s tuples into disjoint subsets. Choose column(s) that divides the database equally in terms of size, load, or usage, called partitioning key(s) and scheme.
Picking the right partitioning scheme is actually the NP-complete problem and there’s a bunch of research on how to do this automatically. Offer times for OLTP, it is pretty obvious, the schema is usually a tree structure like customer account, customer orders, and customer order items, you would partition those tables on the customer id. For OLAP it’s a bit harder because there could be joints across any arbitrary keys and one partitioning scheme for one query may be the best, while the worst for another set of queries.
The potentially Partitioning Schemes are:
- Hashing
- Ranges
- Predicates
Predicates partitioning is not that common, it is usually Hasing partitioning and Range partitioning and in between these two, Hashing partitioning is used more common.
For different architectures, there are different partition strategies:
Logical Partitioning: A node is responsible for a set of keys, but it doesn’t actually store those keys. This is commonly used in a shared disk architecture.
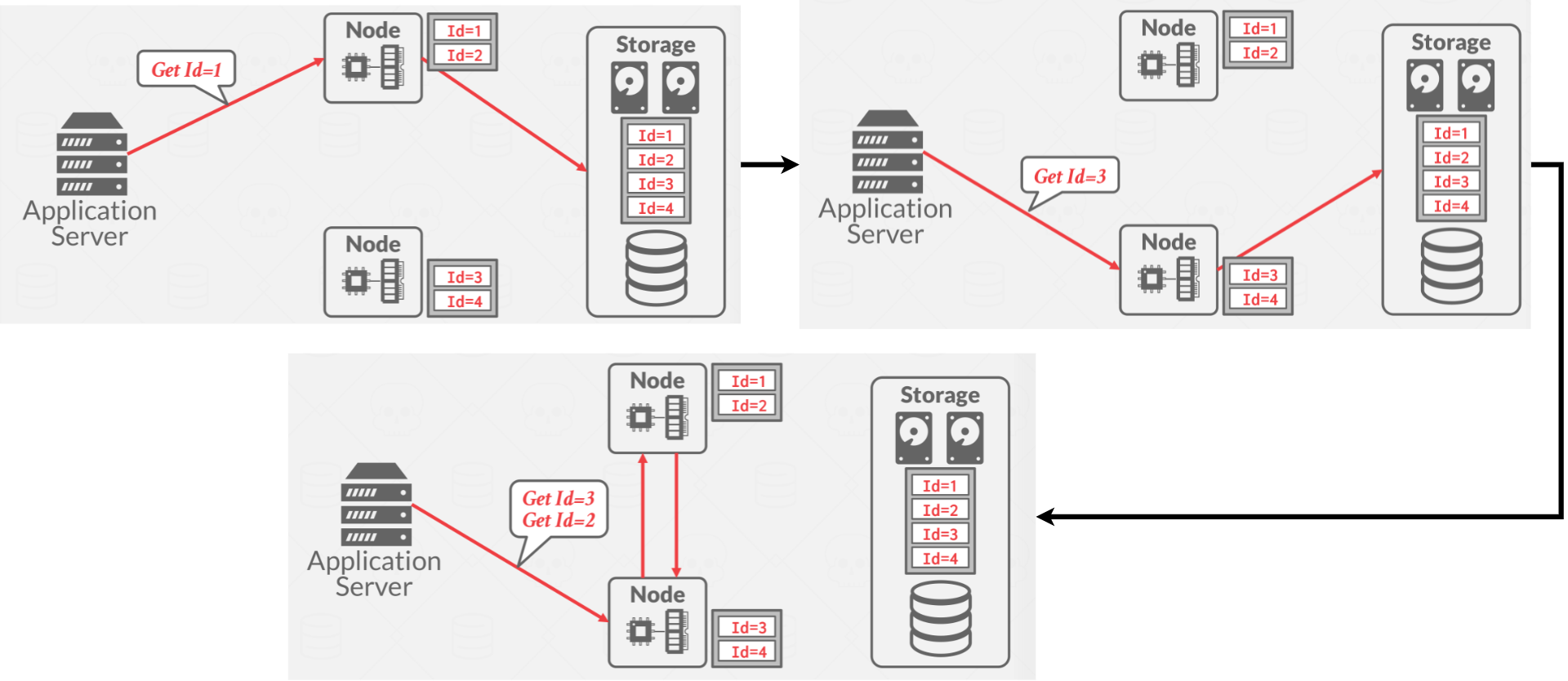 |
|---|
| Figure 6: Logical Partitioning |
Physical Partitioning: A node is responsible for a set of keys, and it physically stores those keys. This is commonly used in a shared nothing architecture.
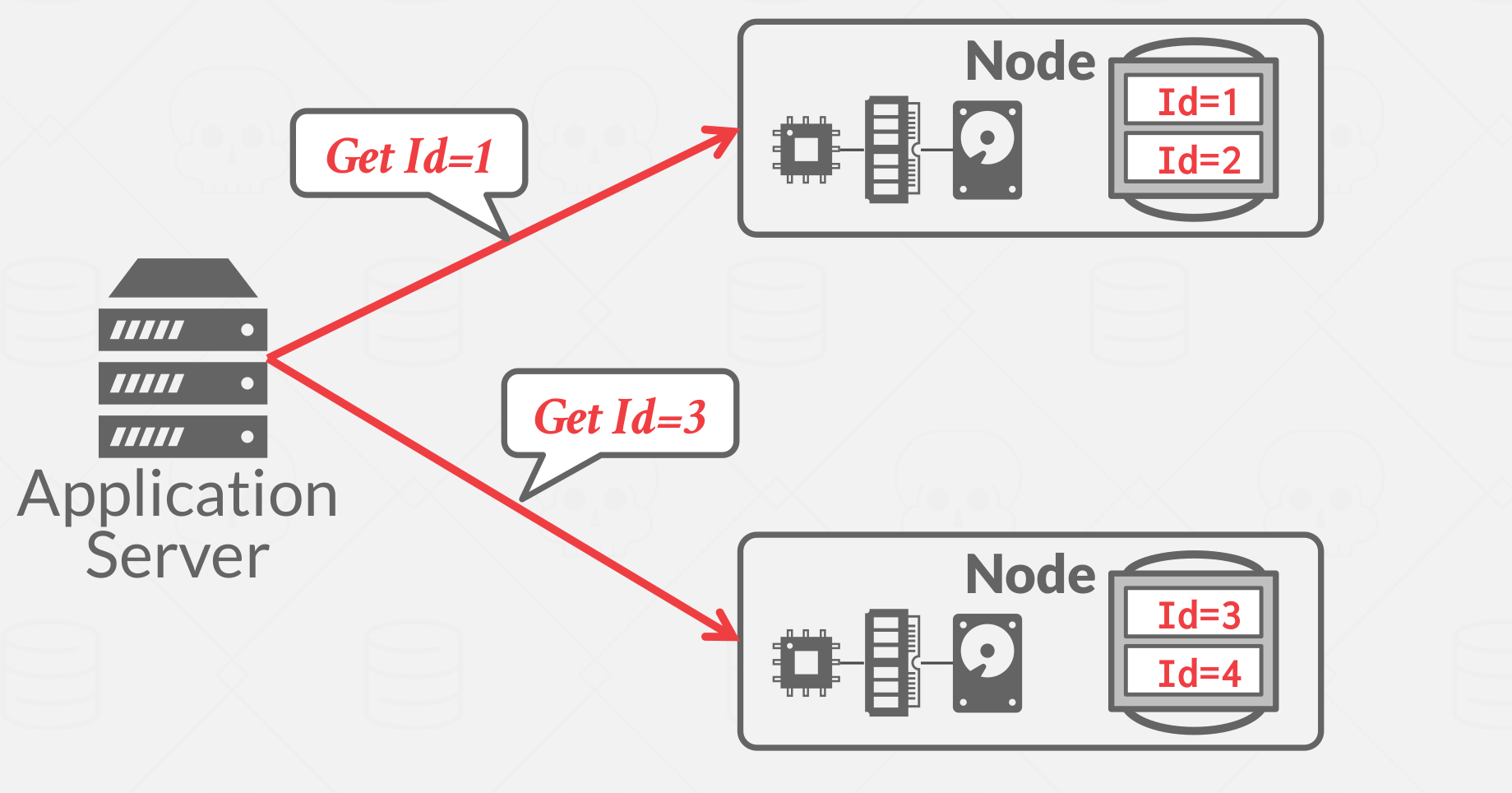 |
|---|
| Figure 7: Physical Partitioning |
The DBMS can partition a database physically(shared nothing) or logically(shared disk) via hash partitioning or range partitioning. See Figure 5 for an example.
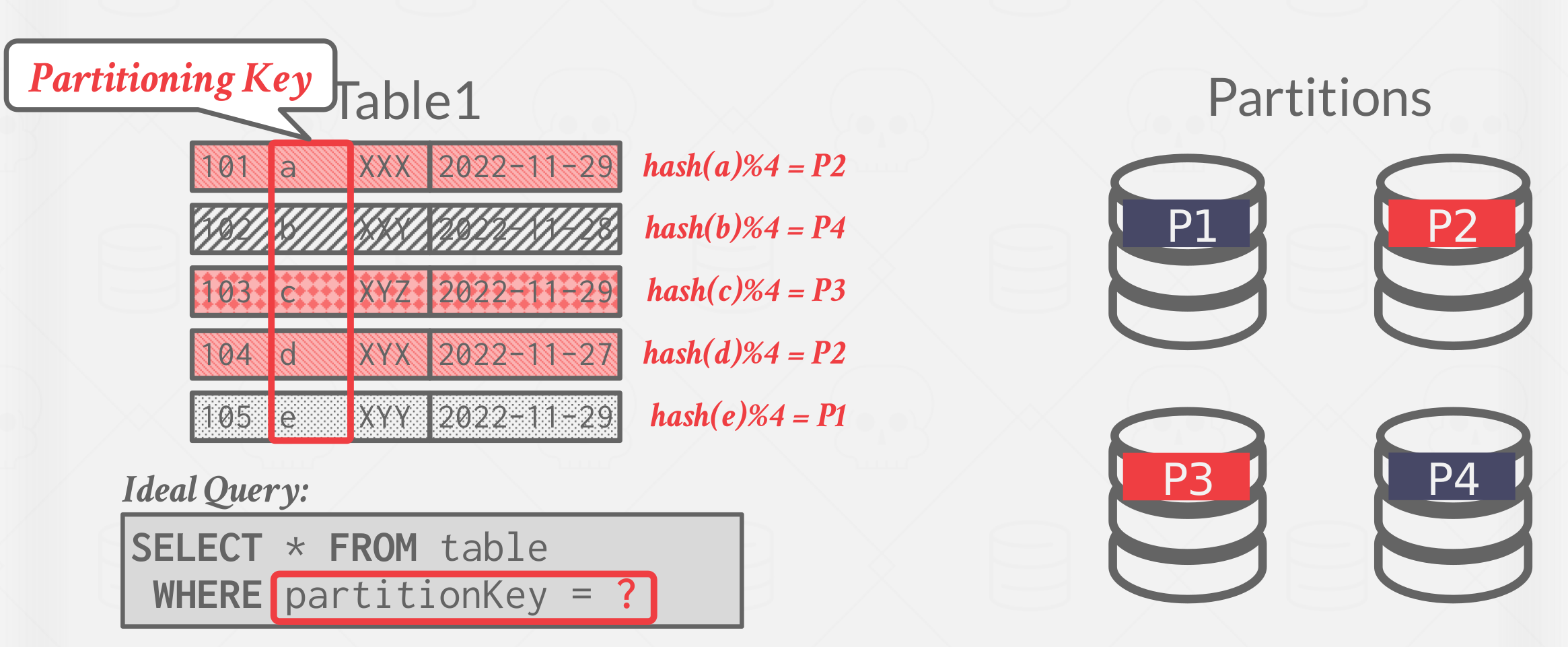 |
|---|
| Figure 5: Hasing Partitioning example |
The problem of hash partitioning is that when a new node is added or remove, a lot of data needs to be shuffled around. The solution for this is Consistent Hashing.
Consistent Hashing assigns every node to a location on some logical ring. Then the hash of every partition key maps to some location on the ring. The node that is closest to the key in the clockwise direction is responsible for that key. See Figure 8 for an example. When a node is added or removed, keys are only moved between nodes adjacent to the new/removed node.
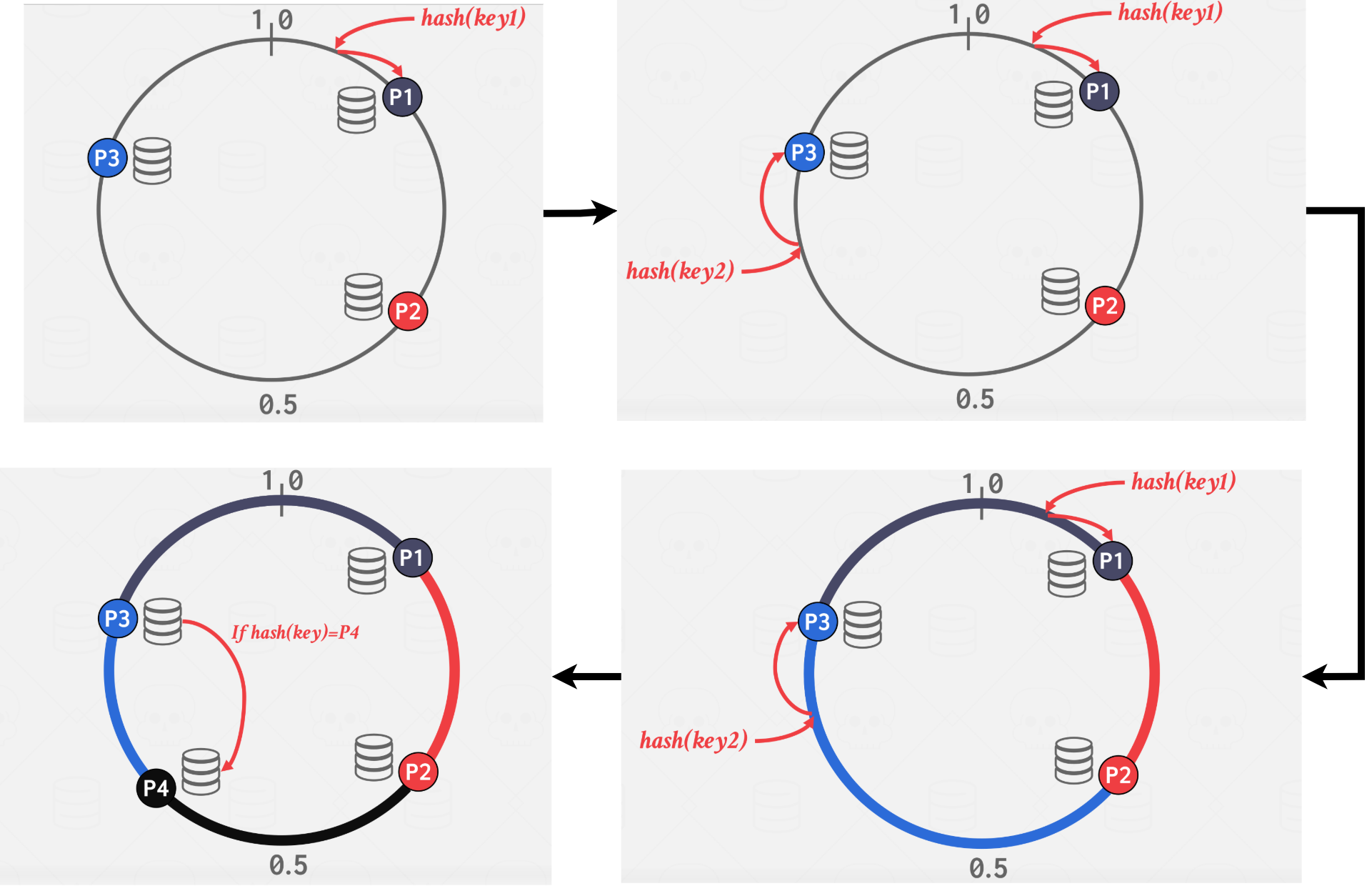 |
|---|
| Figure 8: Consistent Hashing Example |
A replication factor of n means that each key is replicated at the n closest nodes in the clockwise direction. See Figure 9 for an example.
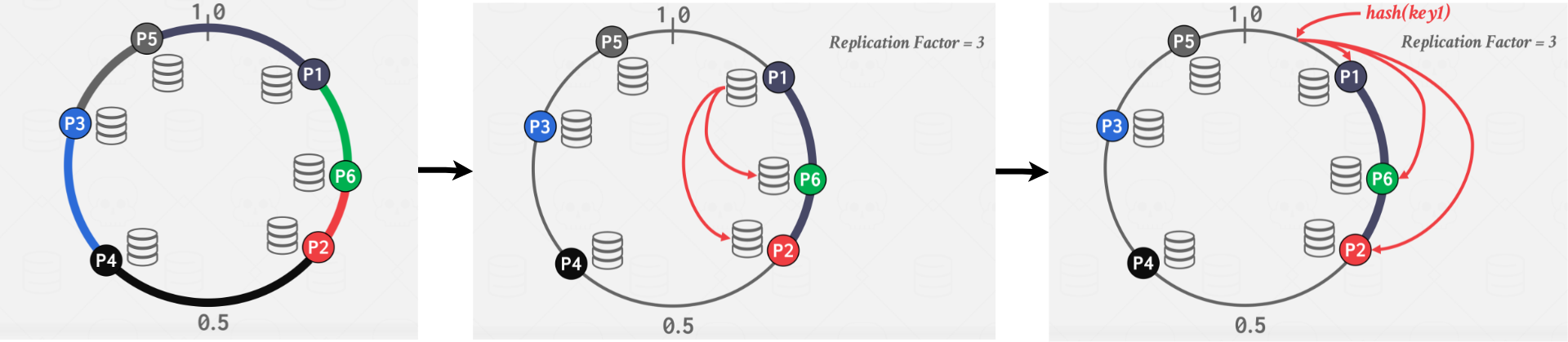 |
|---|
| Figure 9: Consistent Hashing Example with Replication Factor |
5. Transaction coordination #
Compared to a Single-Node transaction where the transaction only accesses data contained on one partition and the DBMS may not need to check the concurrent transactions running on other nodes, A distributed transaction accesses data at one or more partitions and requires expensive coordination.
There are two different approaches for the coordination:
- Centralized: The centralized coordinator acts as a global “traffic cop” that coordinates all the behavior. See Figure 10 for a diagram.
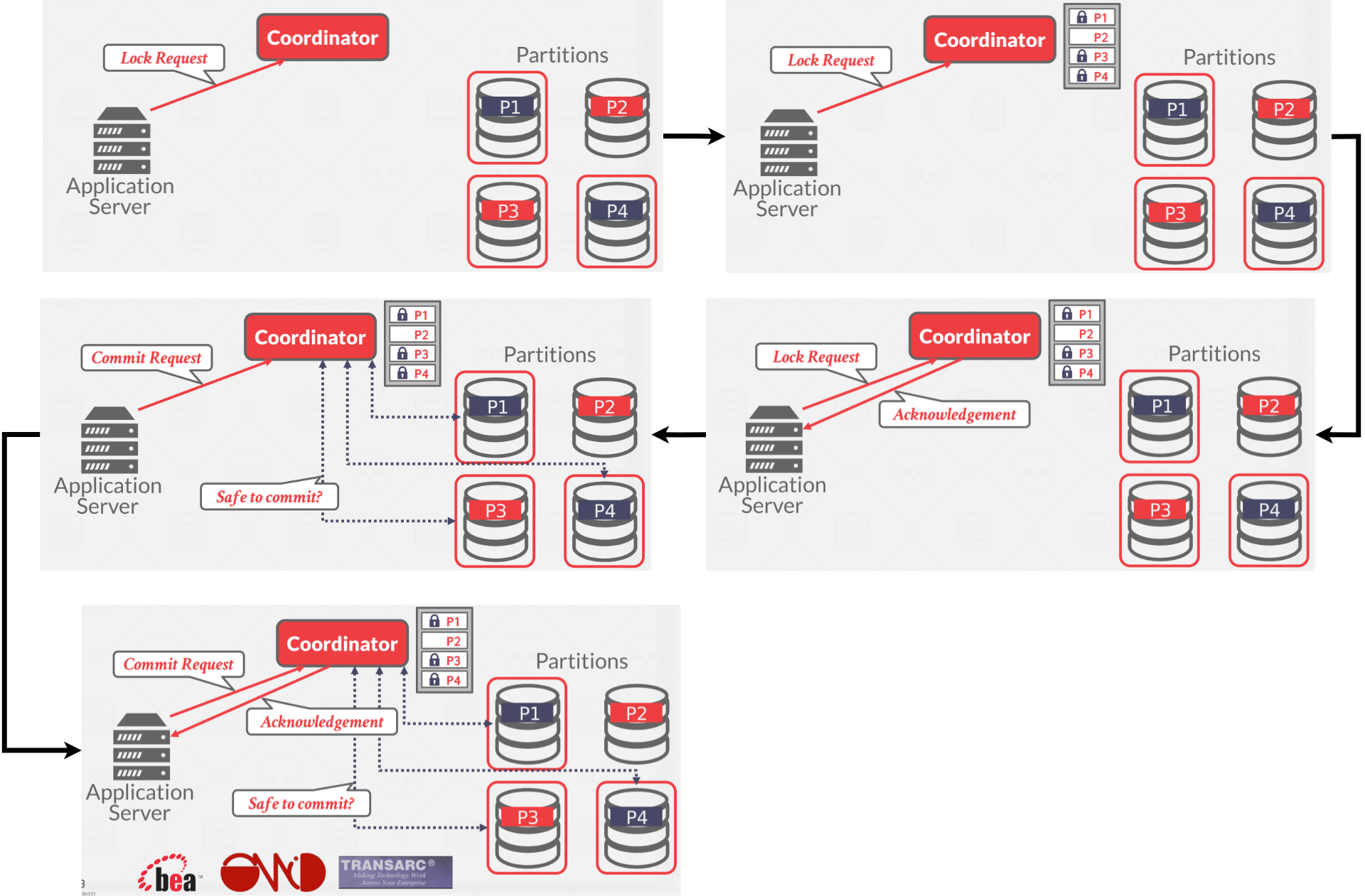 |
|---|
| Figure 10: Centralized coordination |
The client communicates with the coordinator to acquire locks on the partitions that the client wants to access. Once it receives an acknowledgement from the coordinator, the client sends its queries to those partitions. Once all queries for a given transaction are done, the client sends a commit request to the coordinator. The coordinator then communicates with the partitions involved in the transaction to determine whether the transaction is allowed to commit.
- Decentralized: In a decentralized approach, nodes organize themselves. See Figure 11 as an example.
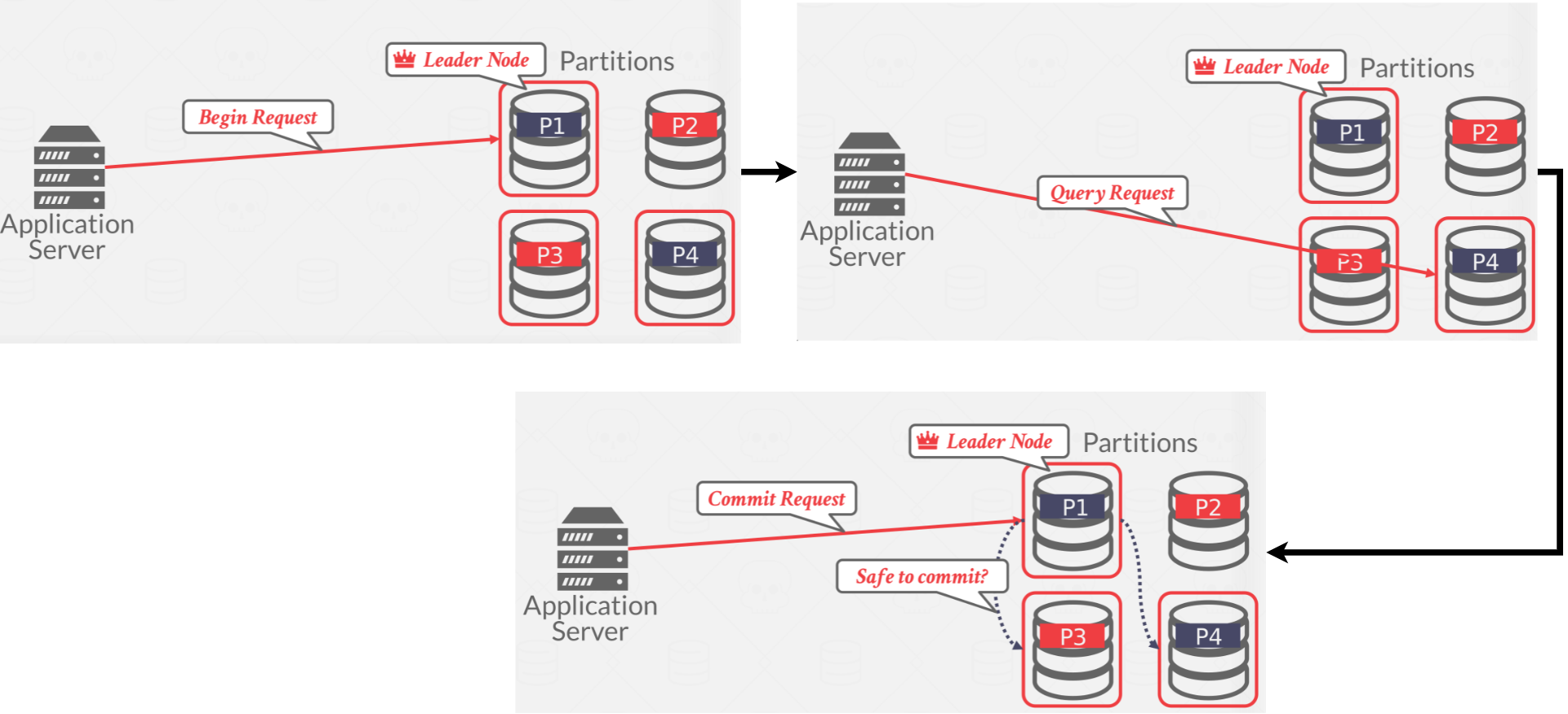 |
|---|
| Figure 11: Decentralized coordination |
The client directly sends queries to one of the partitions. This home partition will send results back to the client. The home partition is in charge of communicating with other partitions and committing accordingly.
Centralized approaches give way to a bottleneck in the case that multiple clients are trying to acquire locks on the same partitions. It can be better for distributed 2PL as it has a central view of the locks and can handle deadlocks more quickly. This is non-trivial with decentralized approaches.
Either approach requires following distributed transactions protocol discussed next class