Database Crash Recovery #
A censorship circumvention tool may be required to open the links in this post from mainland of china.
1. Indroduction #
The DBMS relies on its recovery algorithms to ensure database consistency, transaction atomicity, and durability despite failures. Each recovery algorithm is comprised of two parts:
- Actions during normal transaction processing to ensure that the DBMS can recover from a failure(discussed in Logging Schemes)
- Actions after a failure to recover the database to a state that ensures the atomicity, consistency, and durability of transactions(discuss in the following).
Algorithms for Recovery and Isolation Exploiting Semantics (ARIES) is a recovery algorithm developed at IBM research in early 1990s for the DB2 system.
There are three key concepts in the ARIES recovery protocol:
- Write Ahead Logging: Any change is recorded in log on stable storage before the database change is written to disk (STEAL + NO-FORCE).
- Repeating History During Redo: On restart, retrace actions and restore database to exact state before crash.
- Logging Changes During Undo: Record undo actions to log to ensure action is not repeated in the event of repeated failures.
Not all systems implement ARIES exactly as defined in this paper but they’re close enough.
2. WAL Records #
Write-ahead log records is extended to include a globally unique log sequence number(LSN). LSNs represent the physical order that txns make changes to the database.
Various components in the system keep track of LSNs that pertain to them. A table of these LSNs is shown in Figure 1.
 |
|---|
| Figure 1: LSN Types - Different parts of the system also maintain different types LSN’s that store relevant information |
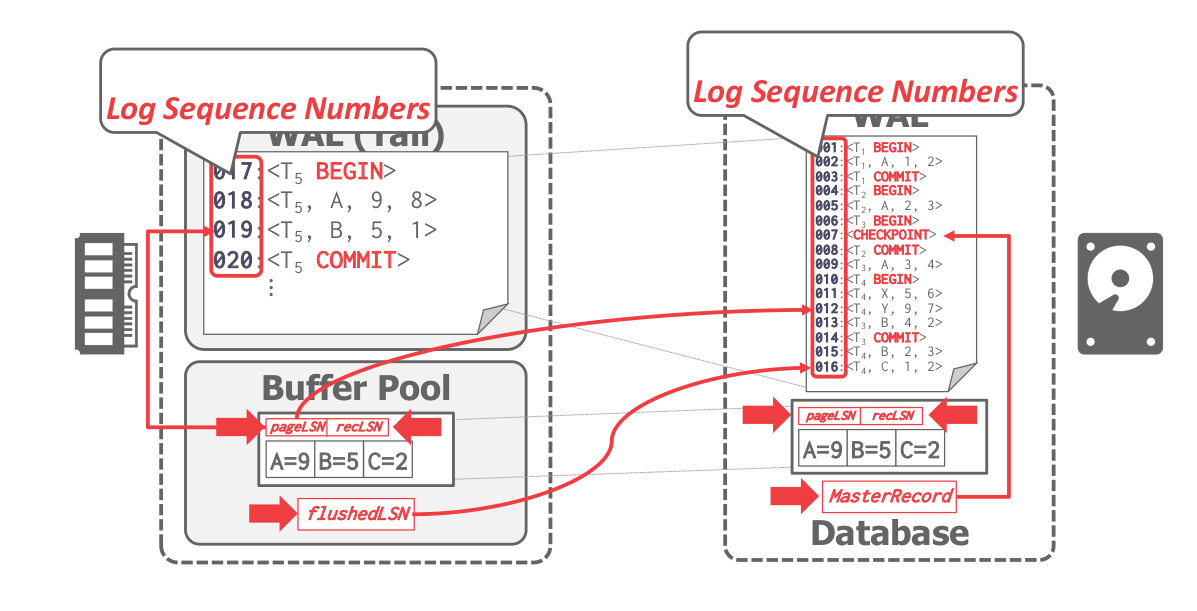
Each data page contains a pageLSN, which is the LSN of the most recent update to that page. The DBMS also keeps track of the max LSN flushed so far (flushedLSN).
Before the DBMS can write page i to disk, it must flush log at least to the point where \( pageLSN_i \leq flushedLSN\) .
A high level diagram of how log records with LSN’s are written is shown in Figure 2.
 |
|---|
| Figure 2: Writing Log Records |
Each WAL has a counter of LSNs that is incremented at every step. The page also keeps a pageLSN and a recLSN, which stores the first log record that made the page dirty. The flushedLSN is a pointer to the last LSN that was written out to disk. The MasterRecord points to the last successful checkpoint passed.
DBMS Update the pageLSN every time a txn modifies a record in the page. Update the flushedLSN in memory every time the DBMS writes out the WAL buffer to disk.
3. Normal Execution #
Each transaction invokes a sequence of reads and writes, followed by commit or abort. It is this sequence of events that recovery algorithms must have.
Assumptions in this lecture
- All log records fit within a single page.
- Disk writes are atomic.
- Single-versioned tuples with Strong Strict 2PL.
- STEAL + NO-FORCE buffer management with WAL.
Transaction Commit #
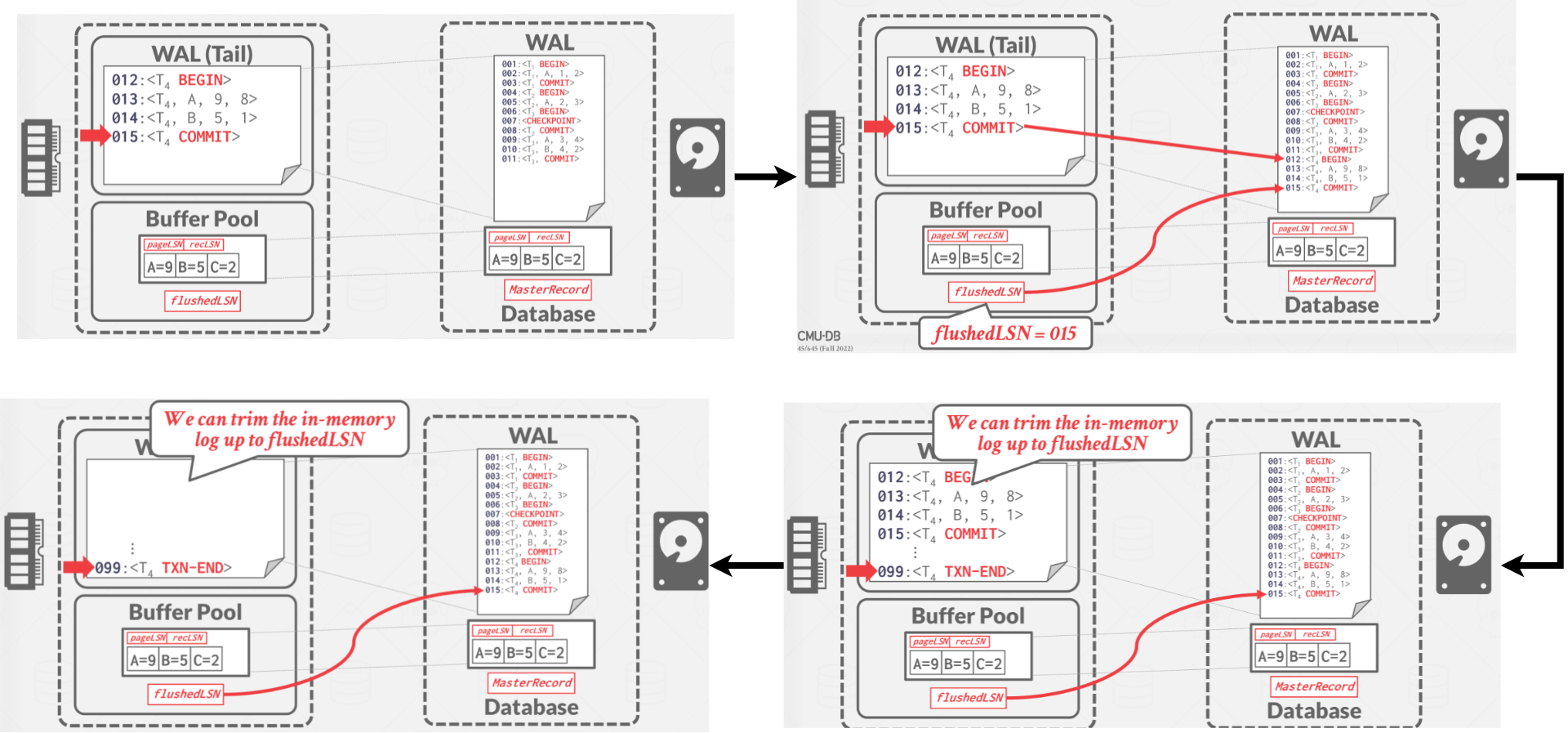
When a transaction goes to commit, the DBMS first writes COMMIT record to log buffer in memory. Then the DBMS flushes all log records up to and including the tranasction’s COMMIT record to disk. Note that these log flushes are sequential, synchronous writes to disk. There can be multiple log records per log page. A diagram of transaction commit is shown in Figure 3.
Once the COMMIT record is safely stored on disk, the DBMS returns an acknowledgment back to the application that the transaction has committed. At some later point, the DBMS will write a special TXN-END record to log. This indicates that the transaction is completely finished in the system and there will not be anymore log records for it. These TXN-END records are used for internal bookkeeping and do not need to be flushed immediately.
 |
|---|
| Figure 3: Normal Execution - Tranasction Commit |
Transaction Abort #
Aborting a transaction is a special case of the ARIES undo operation applied to only one transaction.
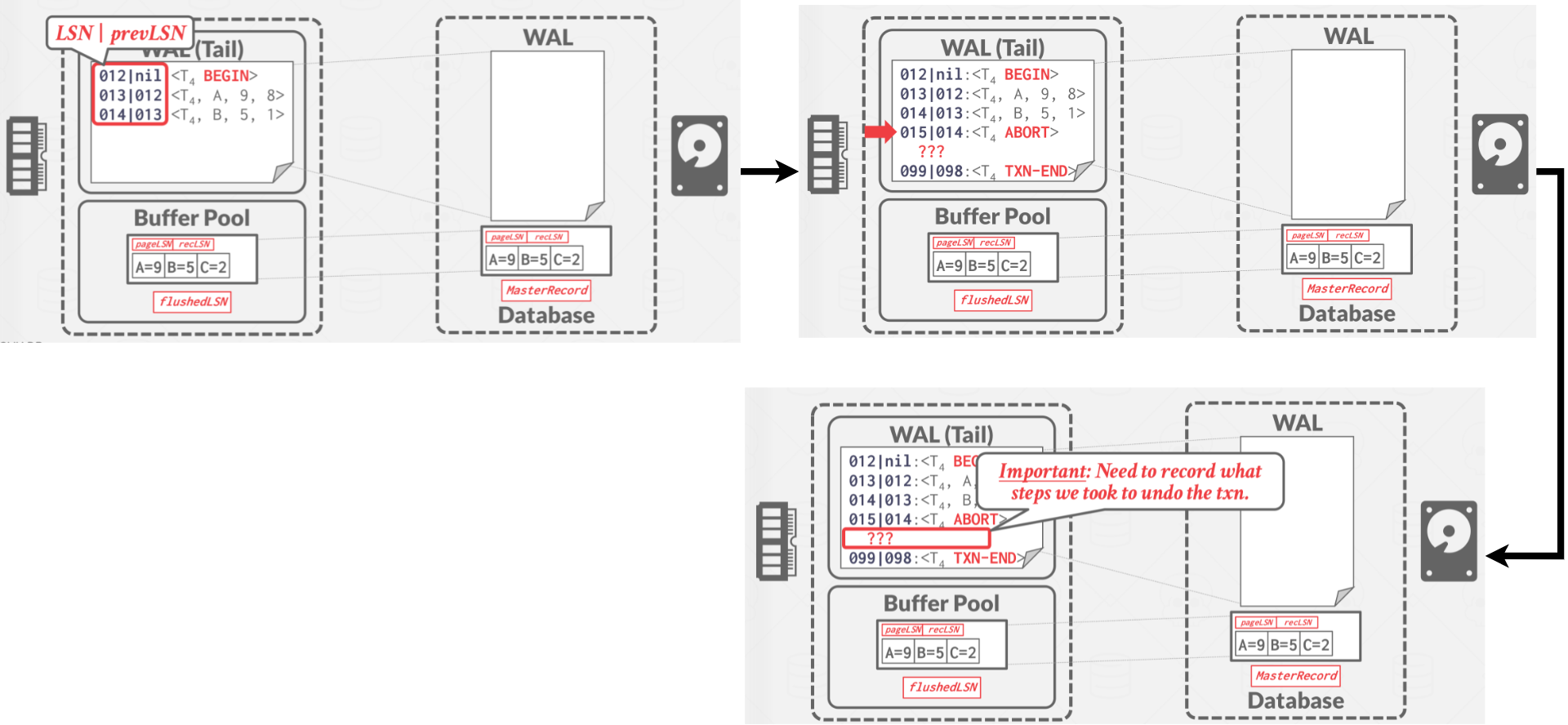
An additional field is added to the log records called the prevLSN. This corresponds to the previous LSN for the transaction. The DBMS uses these prevLSN values to maintain a linked-list for each transaction that makes it easier to walk through the log to find its records. A diagram of transaction commit is shown in Figure 4.
 |
|---|
| Figure 4: Normal Abort - Tranasction Abort, use Compensation Log Record that disscussed below to record the undo steps |
Compensation Log Records
A new type of record called the compensation log record(CLR) is also introduced. A CLR describes the actions taken to undo the actions of a previous update record. It has all the fields of an update log record plus the undoNext pointer (i.e., the next-to-be-undone LSN).
The DBMS adds CLRs to the log like any other record. A diagram of CLR example shown in Figure 5.
 |
|---|
| Figure 5: CLR example |
Abort Algorithm
To abort a transaction, the DBMS
- First append a ABORT record to the log buffer in memory.
- Then analyze the transaction’s updates in reverse order. For each update record:
- Write a CLR entry to the log.
- Restore old value.
- Lastly, write a TXN-END record and release locks.
Notice:
- CLRs never need to be undone
- The DBMS does not wait for them to be flushed before notifying the application that the txn aborted, because the high-level concurrency protocol like MVCC or 2PL would protect other transactions from reading the data that needed to undo under normal execution cases.
4. Checkpointing #
The DBMS periodically takes checkpoints where it writes the dirty pages in its buffer pool out to disk. This is used to minimize how much of the log it has to replay upon recovery.
The first two blocking checkpoint methods discussed below pause transactions during the checkpoint process. This pausing is necessary to ensure that the DBMS does not miss updates to pages during the checkpoint. Then, a better approach that allows transactions to continue to execute during the checkpoint but requires the DBMS to record additional information to determine what updates it may have missed is presented.
Blocking Checkpoints #
The DBMS halts the execution of transactions and queries when it takes a checkpoint to ensure that it writes a consistent snapshot of the database to disk. The is the same approach discussed in previous lecture:
- Halt the start of any new transactions.
- Wait until all active transactions finish executing.
- Flush dirty pages to disk.
This is bad for runtime performance but makes recovery easy.
Slightly Better Blocking Checkpoints #
Pause modifying transactions while the DBMS takes the checkpoint.
- Prevent queries from acquiring write latch on table/index pages.
- Don’t have to wait until all txns finish before taking the checkpoint.
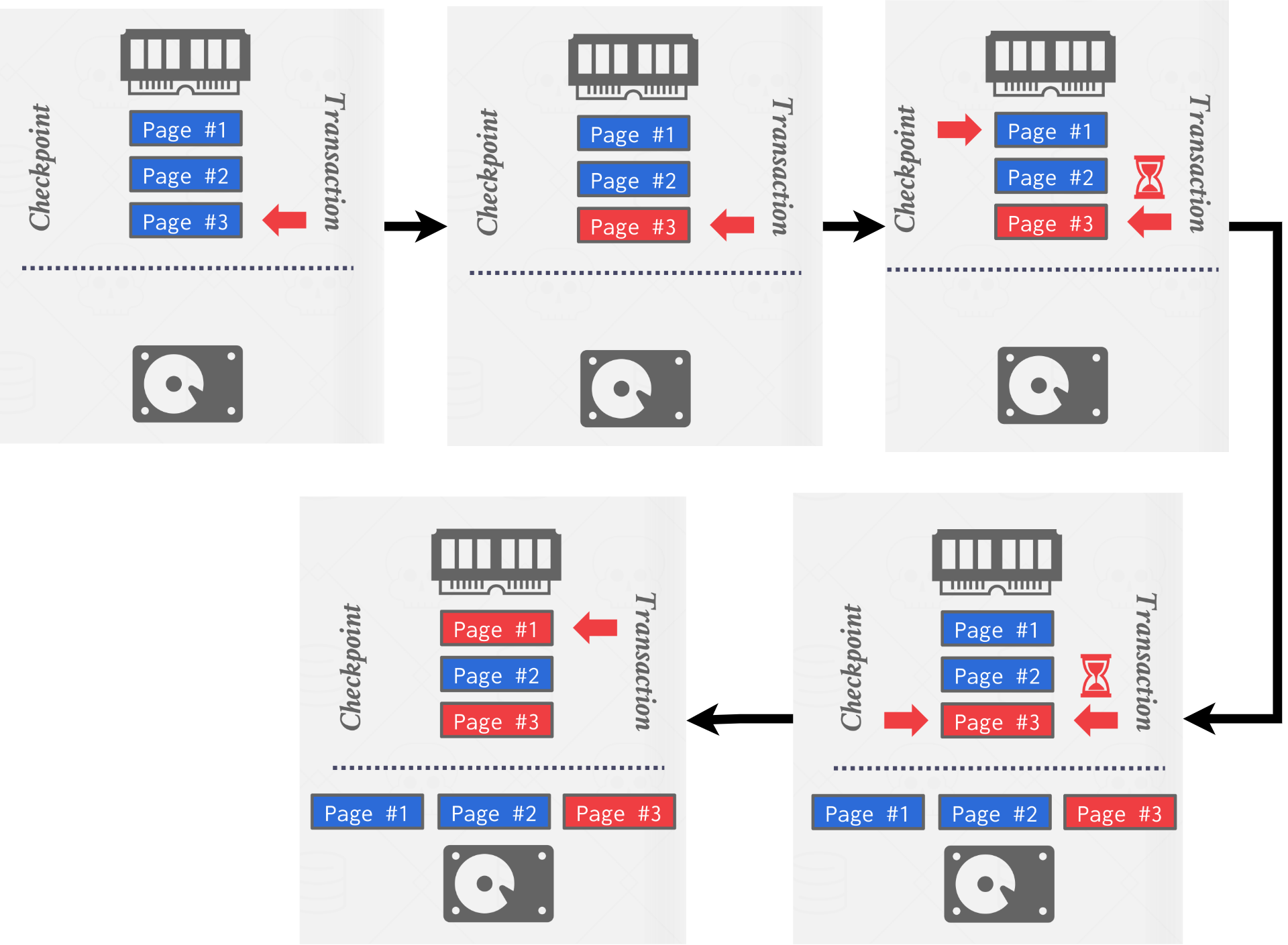
Here is a exmaple show in Figure 6.
 |
|---|
| Figure 6: Example of Blocking Checkpoints with Pausing |
In this example, we assume the transaction will need to update Page #1 and Page #3. However it is paused after updating Page #3 before Page #1 and the while the checkpoing will flush all the pages, Page #1, #2, #3 in our example, to the disk. After the checkpoint done, the transaction continue to write the Page #1.
In the example above, a torn-updates problem occurs because the transaction is paused during its execution, and the checkpoint flushes Page #3, which represents only a partial update of the transaction. If the system crashes before the next checkpoint and restarts, the DBMS will have no way to identify Page #3 as a dirty page during recovery mode. Consequently, this results in torn updates.
To address this issue, the DBMS now must records the internal system state as of the beginning of the checkpoint:
- Active Transaction Table(ATT)
- Dirty Page Table(DPT)
Active Transaction Table (ATT): The ATT represents the state of transactions that are actively running in the DBMS, For each transaction entry, the ATT contains the following information:
- transactionId: Unique transaction identifier
- status: The current “mode” of transaction, one of (Running, Committing, Undo Candidate)
- lastLSN: Most recent LSN written by transaction
An ATT entry is removed after the DBMS completes the commit/abort process for that transaction, meaning it occurs after the TXN-END is written to log record.
Note that the ATT contains every transcation without the TXN-END log record. This includes both transactions that are either committing or aborting.
Dirty Page Table(DPT): The DPT contains information about the pages in the buffer pool that were modified by uncommitted transactions. There is one entry per dirty page, which includes the recLSN (i.e., the LSN of the log record that first caused the page to be dirty).
The DPT encompasses all dirty pages in the buffer pool, regardless of whether the changes were caused by a running, committed, or aborted transaction.
In other words, the DPT keeps track of which pages in the buffer pool contain changes that have not yet been flushed to disk.
Overall, both the ATT and the DPT assist the DBMS in recovering the state of the database from a crash using the ARIES recovery protocol.
 |
|---|
| Figure 7: Example for Slightly Better Blocking Checkpoints |
Fuzzy Checkpoints #
A fuzzy checkpoint is where the DBMS allows other transactions to continue to run. This is what ARIES uses in its protocol.
The DBMS uses additional log records to track checkpoint boundaries:
- CHECKPOINT-BEGIN: indicate the start of the checkpoint. At this point, the DBMS takes a snapshot of the current ATT and DPT, which are referenced in the CHECKPOINT-END record.
- CHECKPOINT-END: When the checkpoint has completed. It contains the ATT + DPT, captured just as the CHECKPOINT-BEGIN log record is written.
An example of fuzzy checkpoints is shown in Figure 8, in which we assume the DBMS flushes page #11 before the first checkpoint starts. Any transaction that begins after the checkpoint starts is excluded from the ATT in the CHECKPOINT-END record. The LSN of the CHECKPOINT-BEGIN is written to the MasterRecord when it completes.
 |
|---|
| Figure 8: Example for Fuzzy Checkpoints |
Notice: the fuzzy checkpoint have no attempt to force dirty pages to disk.
5. ARIES Recovery #
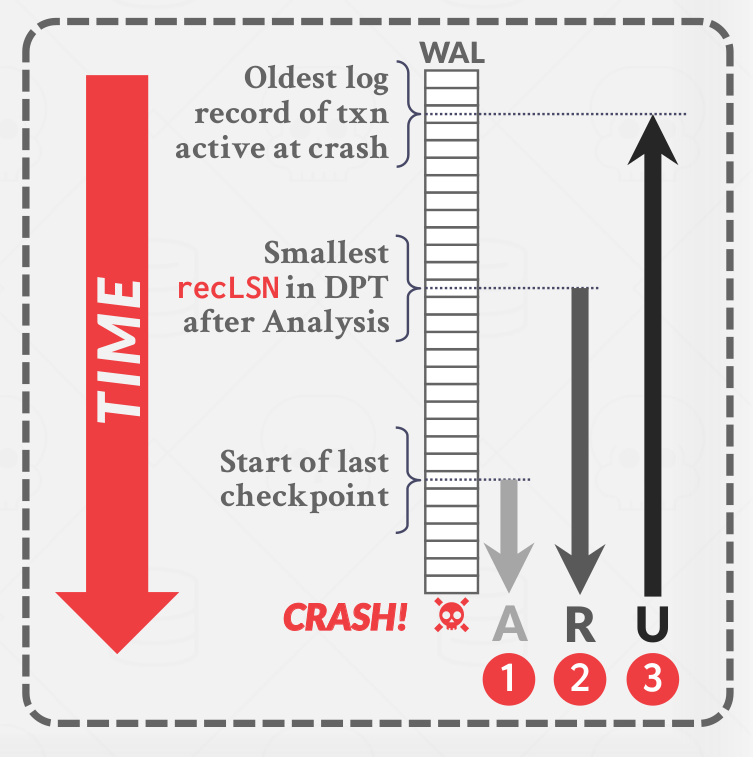
The ARIES protocol is comprised of three phases. Upon start-up after a crash, the DBMS will execute the following phases as shown in Figure 9:
- Analysis: Read the WAL to identify dirty pages in the buffer pool and active transactions at the time of the crash. At the end of the analysis phase the ATT tells the DBMS which transactions were active at the time of the crash. The DPT tells the DBMS which dirty pages might not have made it to disk.
- Redo: Repeat all actions starting from an appropriate point in the log.
- Undo: Reverse the actions of transactions that did not commit before the crash.
 |
|---|
| Figure 9: ARIES Overview |
The DBMS starts the recovery process by examining the log starting from the last CHECKPOINT-BEGIN found via MasterRecord. It then begins the analysis phase by scanning forward through time to build out ATT and DPT. In the Redo phase, the algorithm jumps to the smallest recLSN, which is the oldest log record that may have a modified page not written to disk. The DBMS then applies all changes from the smallest recLSN. The Undo phase starts at the oldest log record of a transaction active at the crash and reverses all changes up to that point.
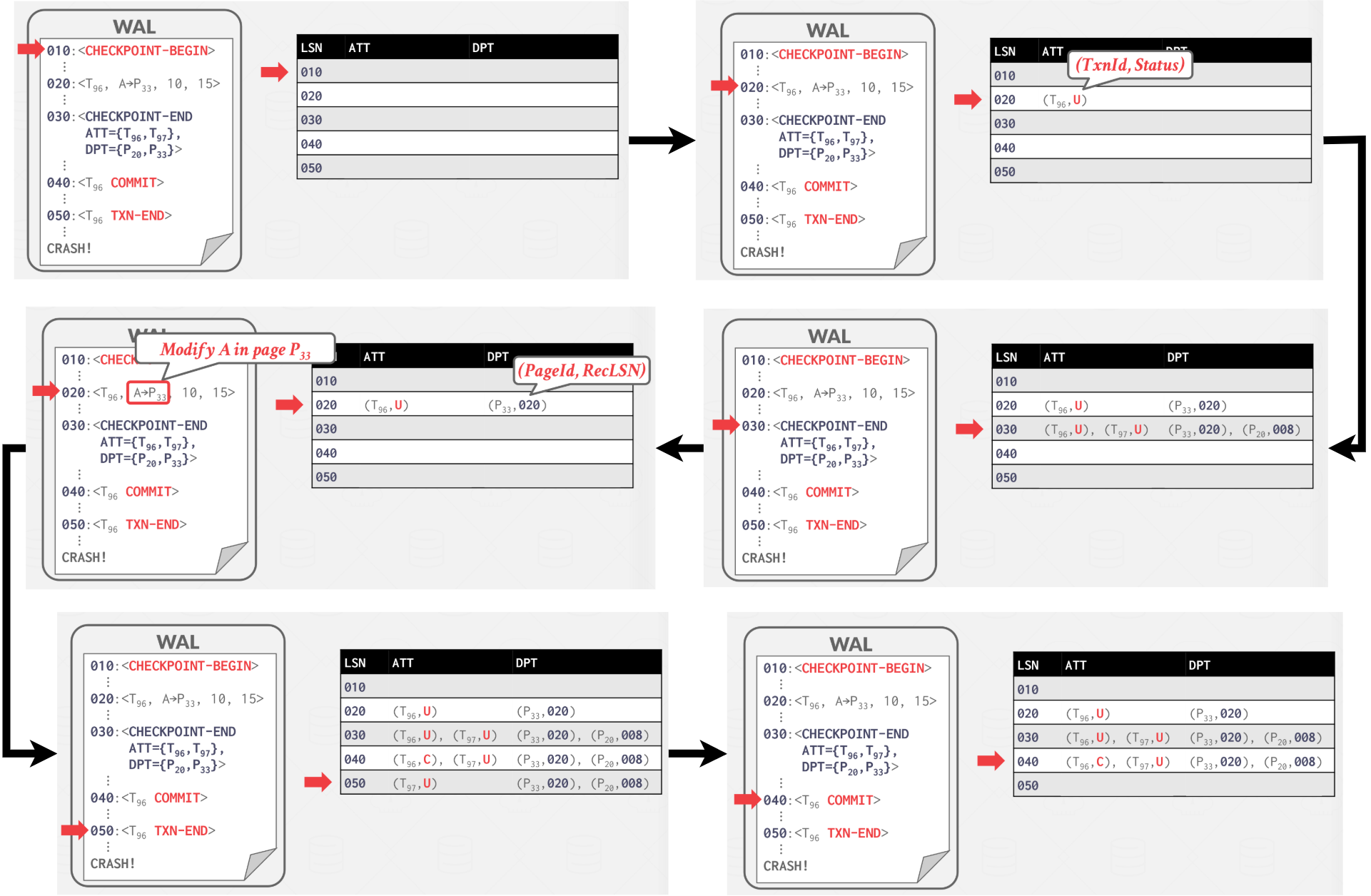
Analysis Phase #
Start from the last checkpoint found via the database’s MasterRecord LSN.
- Scan the log forward from the checkpoint.
- If the DBMS finds a TXN-END record, remove its transaction from ATT.
- For All other records, add transaction to ATT with status UNDO, and on commit, change transaction status to COMMIT*.
- For UPDATE log records, if page P is not in the DPT, then add P to DPT and set P’s recLSN in DPT to the log record’s LSN.
An exmaple of Analysis example as shown in Figure 10:
 |
|---|
| Figure 10: Analysis Example |
At end of the Analysis Phase:
- ATT identifies which transaction were active at time of the crash.
- DPT identifies which dirty pages might not have made it to disk.
Redo Phase #
The goal of this phase is for the DBMS to repleat history to reconstruct its state up to moment of the crash. It will reapply all updates(even aborted transactions) and redo CLRs.
The DBMS scans forward from log record containing smallest recLSN in the DPT. For each update log record or CLR with a given LSN. the DBMS re-applies the update unless:
- Affected page is not in the DPT, or
- Affected page is in DPT but that record’s LSN is less than the recLSN of the page in DPT, or
- Affected pageLSN(on disk) \( \geq \) LSN
To redo an action, the DBMS:
- Re-applies the change in the log record, and
- Sets the affected page’s pageLSN to that log record’s LSN
- No additional logging, no forced flushes!
At the end of Redo Phase, write TXN-END log for all transactions with status COMMIT and remove them from the ATT.
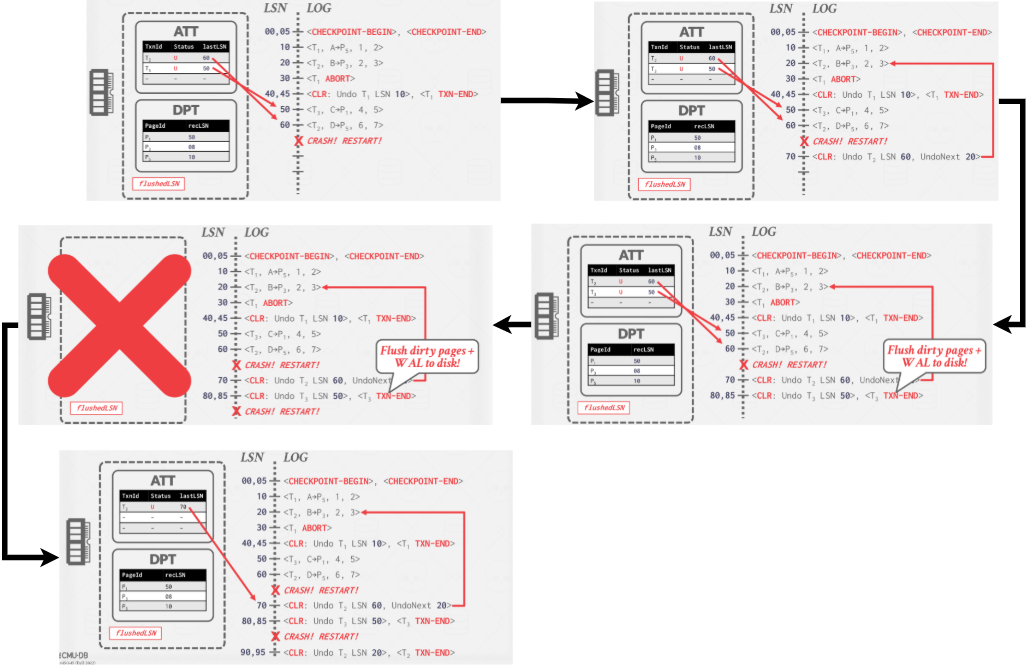
Undo Phase #
In the last phase, the DBMS reverses all transactions that were active at the time of the crash. These are all transactions with UNDO status in the ATT after the Analysis phase.
The DBMS processes transactions in reverse LSN order using lastLSN to speed up traversal. As it reverses the updates of a transaction, the DBMS writes a CLR entry to the log for each modification.
An exmaple of Undo example as shown in Figure 11:
 |
|---|
| Figure 11: Undo Example |
Once the last transaction has been successfully aborted, the DBMS flushes out the log and then is ready to start processing new transactions.
Addional crash issues #
What does the DBMS do if it crashes during recovery in the Analysis Phase?
- Nothing, Just run recovery again.
What does the DBMS do if it crashes during recovery in the Redo Phase?
- Again nothing, Redo everythin again.
How can the DBMS improve performance during recovery in the Redo Phase?
- Assume that it is not going to crash again and flush all changes to disk asynchronously in the background.
How can the DBMS improve performance during recovery in the Undo Phase?
- Lazily rollback changes before new txns access pages.
- Rewrite the application to avoid long-running txns.
6. Conclusion #
Main ideas of ARIES:
- WAL with STEAL/NO-FORCE
- Fuzzy Checkpoints (snapshot of dirty page ids)
- Redo everything since the earliest dirty page
- Undo txns that never commit
- Write CLRs when undoing, to survive failures during restarts
Log Sequence Numbers:
- LSNs identify log records; linked into backwards chains per transaction via prevLSN.
- pageLSN allows comparison of data page and log records.