Logging Schemes #
A censorship circumvention tool may be required to open the links in this post from mainland of china.
1. Introduction #
The logging protocol is a machanism to make sure if the application write bunch of changes of the database, and application commit a transaction, the database system tells the application that the transaction is committed, how does the DBMS make sure that there is a crash or something happens, the application come back and the changes still there.
Here is a simple example for the motivation of the logging.
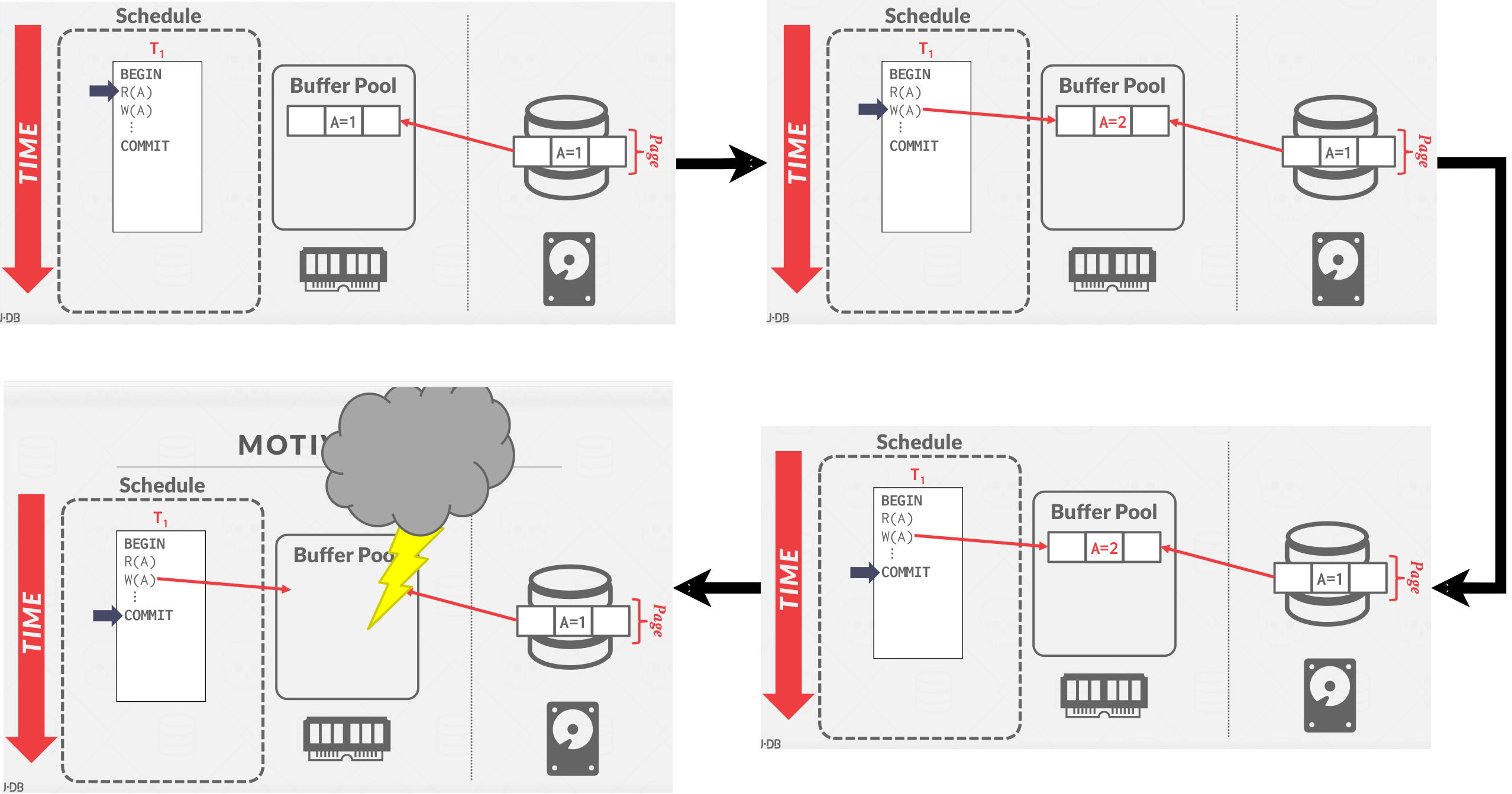 |
|---|
| Motiation |
2. Crash Recovery #
Recovery algorithms are techniques to ensure database consistency, transaction atomicity, and durability despite failures. When a crash occurs, all the data in memory that has not been committed to disk is at risk of being lost. Recovery algorithms act to prevent loss of information after a crash.
Every recovery algorithm has two parts:
- Actions during normal transaction processing to ensure that the DBMS can recover from a failure(discuss in the following).
- Actions after a failure to recover the database to a state that ensures atomicity, consistency, and durability(discuss in Database Crash Recovery).
The key primitives that used in recovery algorithms are UNDO and REDO. Not all algorithms use both primitives.
- UNDO: The process of removing the effects of an incomplete or aborted transaction.
- REDO: The process of re-applying the effects of a committed transaction for durability.
DBMS is divided into different components based on the underlying storage device(Volatile vs. Non-Volatile). We must also classify the different types of failures that the DBMS needs to handle.
3. Storage Types #
-
Volitile Storage
- Data does not persist after power is lost or program exists.
- Examples: DRAM, SRAM.
-
Non-Volatile Storage
- Data persists after losing power or program exists.
- Examples: HDD, SDD.
-
Stable Storage
- A non-existent form of non-volatile storage that survives all possible failures scenarios.
- User multiple storage devices to approximate.
4. Failure Classification #
Because the DBMS is divided into different components based on the underlying storage device, there are a number of different types of failures that the DBMS needs to handle. Some of these failures are recoverable while others are not.
Type #1: Transaction Failures
Transactions failures occur when a transaction reaches an error and must be aborted. Two types of errors that can cause transaction failures are logical errors and internal state errors.
- Logical Errors: A transaction cannot complete due to some internal error condition(e.g., integrity, constraint violation).
- Internal State Errors: The DBMS must terminate an active transaction due to an error condition(e.g., deadlock).
Type #2: System Failures
System failures are unintented failures in the underlying software or hardware that hosts the DBMS. These faulures must be accounted for in crash recovery protocols.
- Software failure: There is a problem with the DBMS implementation(e.g., uncaught divid-by-zero exception) and the system has to halt.
- Hardware Failure: The computer hosting the DBMS crashes(e.g., power plug gets pulled). We assume that non-volatile storage contents are not corrupted by system crash. This is called “Fail-stop” assumption and simplifies the process recovery.
Type #3: Storage Media Failure
Storage media failures are non-repairable failures that occur when the physical storage device is damaged. When the storage media fails, the DBMS must be restored from an archived versiion. The DBMS cannot recover from a storage failure and requires human intervention.
- Non-Repairable Hardware Failure: A head crash or similar disk failure destroys all or parts of non-volatile storage. Destruction is assumed to be detectable.
5. Buffer Pool Management Policies #
Because the database’s primary storage location is on nonvolatile storage, which is slower than volatile storage, DBMS use volatile memory for faster access:
- First copy target record into memory.
- Perform the writes in memory.
- Write dirty records back to disk.
Because of this cache mechanism of buffer pool, the DBMS needs to ensure the following guarantees:
- The changes for any transaction are durable once the DBMS has told somebody that it committed.
- No partial changes are durable if the transaction aborted.
Here is a basic questions in the buffer pool management:
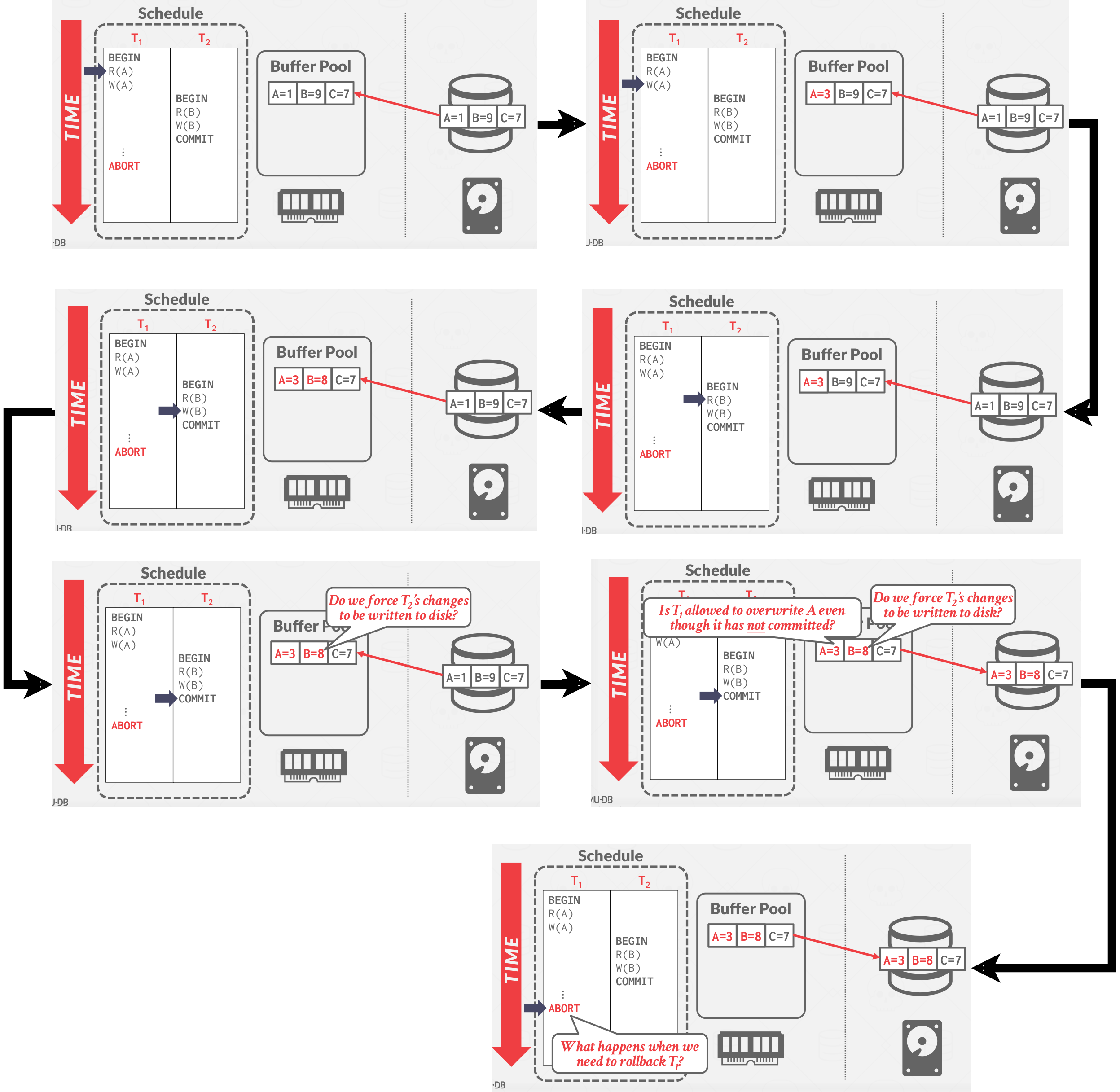 |
|---|
| Basic questions in buffer pool management |
To address these questions, the DBMS introdueced steal policy and force policy.
A steal policy dictates whether the DBMS allows an uncommitted transaction to overwrite the most recent commited value of an object in non-volatile storage(can a transaction write uncommitted changes belonging to a different transaction to disk?).
- STEAL: Is allowed
- NO-STEAL: Is not allowed.
A force policy dictates whether DBMS requires that all updates made by a transaction are reflected on non-volatile storage before the transaction is allowed to commit(ie. return a commit message back to the client).
- FORCE: Is required
- NO-FORCE: Is not required
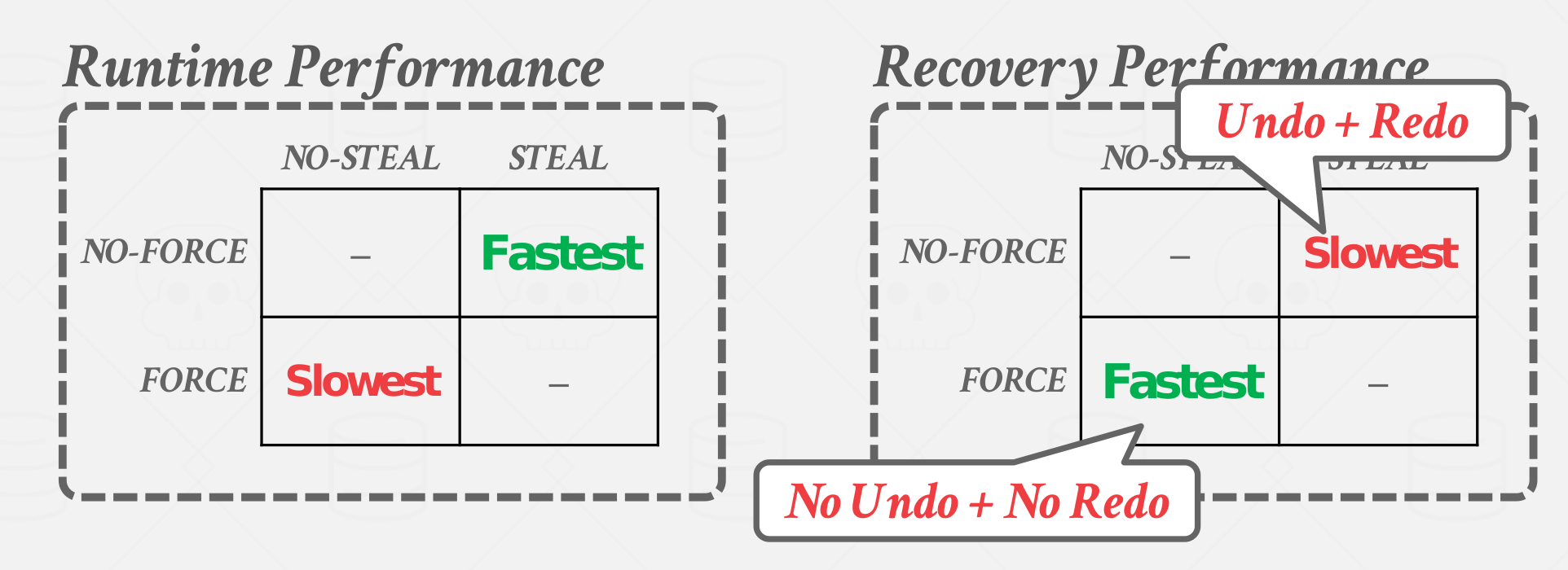
Force writes make it easier to recover since all of the changes are preserved but result in poor runtime performance.
The easiest buffer pool management policy to implement is called NO-STEAL + FORCE. In this policy, the DBMS never has to undo changes of an aborted transaction because the changes were not written to disk. It also never has to redo changes of a committed transaction because all the changes are guaranteed to be written to disk at commit time. An example of NO-STEAL + FORCE is show in Figure 1.
A limitation of NO STEAL + FORCE is that all of the data (ie. the write set) that a transaction needs to modify must fit into memory. Otherwise, that transaction cannot execute because the DBMS is not allowed to write out dirty pages to disk before the transaction commits.
The following is an example that use NO-STEAL + FORCE approach:
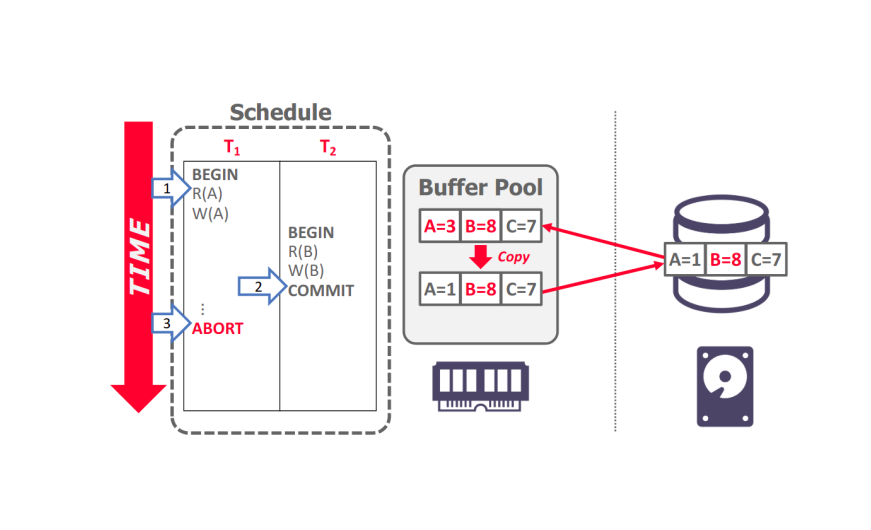 |
|---|
| DBMS using NO-STEAL + FORCE Example |
All changes from a transaction are only written to disk when the transaction is committed. Once the schedule begins at Step #1, changes from \( T_1 \) and \( T_2 \) are written to the buffer pool. Because of the FORCE policy, when \( T_2 \) commits at Step #2, all of its changes must be written to disk. To do this, the DBMS makes a copy of the memory in disk, applies only the changes from \( T_2 \) , and writes it back to disk. This is because NO-STEAL prevents the uncommitted changes from \( T_1 \) to be written to disk. At Step #3, it is trivial for the DBMS to rollback \( T_1 \) since no dirty changes from \( T_1 \) are on disk.
The NO-STEAL + FORCE approach is the easiest to implement, because it
- Never have to undo changes of an aborted txn because the changes were not written to disk
- Never have to redo changes of a committed txn because all the changes are guaranteed to be written to disk at commit time(assuming atomic hardware writes, although it is impossible)
However this NO-STEAL + FORCE approach cannot support write sets that exceed the amount of physical memory available.
6. Shadow Paging #
Shadow Paging is an improvement upon the previous scheme where the DBMS copies pages on write to maintain two separate versions of the database:
- master: Contains only changes from committed txns.
- shadow: Temporary database with changes made from uncommitted transactions.
Updates are only made in the shadow copy. When a transaction commits. the shadow copy is atomically switched to become the new master. The old master is eventually garbage collected. This is an example of a NO-STEAL + FORCE system. A high-level example of shadow paging is shown as follows:
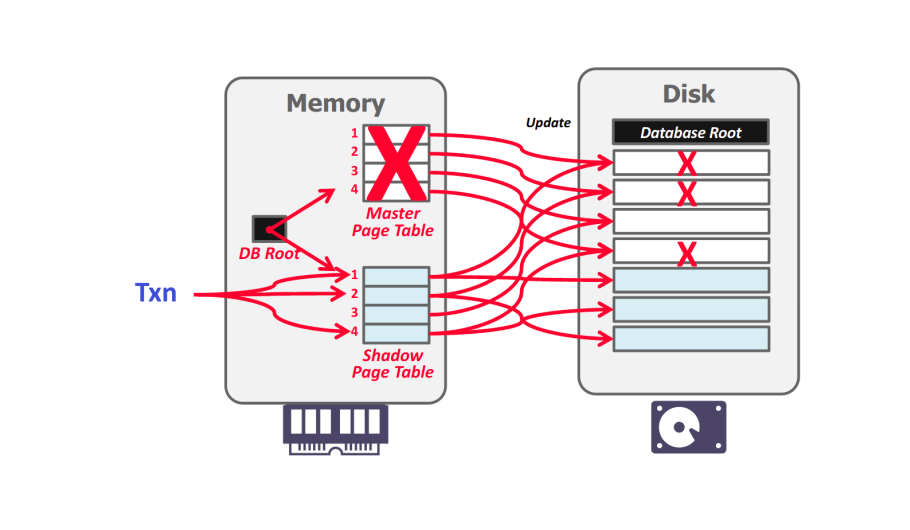 |
|---|
| Shadow Paging |
The database root points to a master page table which in turn points to the pages on disk(all of which contain committed data). When an updating transaction occurs. a shadow page table is created that points to the same pages as the master. Modifications are made to a temporary space on disk and the shadow table is updated. To complete the commit, the database root pointer is redirected to the shadow table, which become the new master.
Recovery
- Undo: Remove the shadow pages. Leave the master and DB root pointer alone.
- Redo: Not needed at all.
Disadvantages
- Copying the entire page table is expensive. Although, it can be voided by using a B+tree structured page table where the database root is essentially the root of the tree and there is no need to copy the entire tree and only need to copy paths in the tree that lead to updated leaf nodes(this is essentially what LMDB does), however, this is a lot more work to maintain these core structure versions.
- Commit overhead is high. It requires the page table, and root, in addition to every updated page to be flushed. and the data would get fragmented which is bad for sequential scans. it also requires garbage collection. Another issue is that this only supports one writer transaction at a time or transactions in a batch because we as the DBMS potentially had the same problem that we had before where we could have two transactions that are running simultaneously and make updates to different objects that are just stored on the same page and when we go to commit we have to make sure that we reverse the change from the uncommitted transaction and let the committed transaction actually go out the disk. we can avoid this by batching this up but the problem is that the transaction could take a long time like hours to finish.
Note
Shadow Paging was what IBM originally invented for system R back in the 1970s. when they were building the first relational database from IBM this is the approach they came up with. but then they ended up abandoning it in the 1980s when they re-built a new relational database system db2 that they were actually going to sell to the real world commercially, because system R was only a research project when they built DB2 they scrapped all this switched to the write-ahead log approach.
7. Journal File #
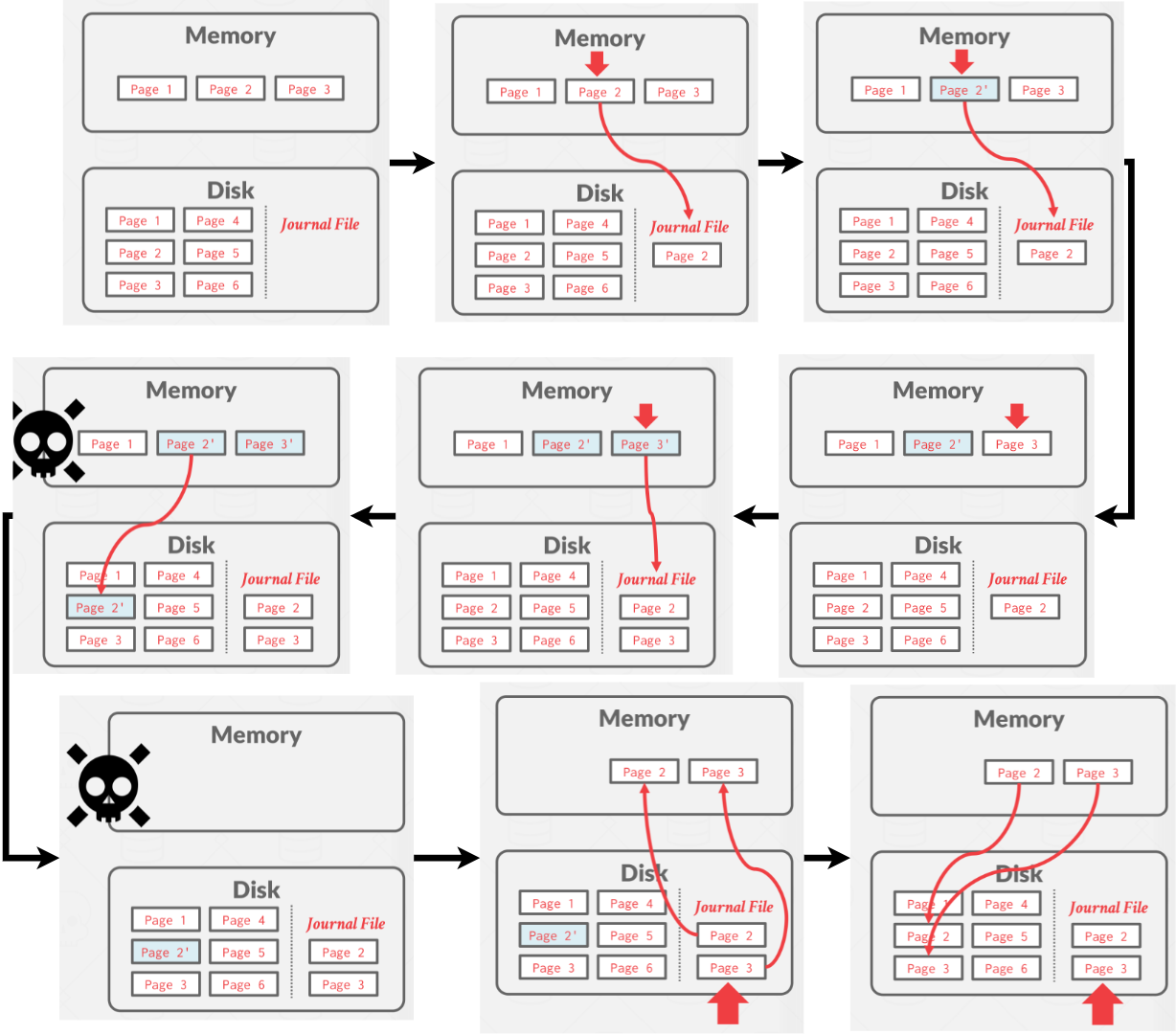
When a transaction modifies a page, the DBMS copies the original page to a separate journal file before overwriting the master version. After restarting, if a journal file exists. then the DBMS restores it to undo changes from uncommited transactions.
This is what SQLLite uses before 2010. Although the newer version still provides the “rollback mode”, SQLLite switches to Write-Ahead Logging as well after 2010.
 |
|---|
| SQLLite journal file example |
Same with the Shadow Paging approach, Jorunal File can only support single writer as well.
Observation
Both Shadowing page requires the DBMS to perform writes to random non-contiguus pages on disk. We need a way for the DBMS convert random writes into sequential writes, this is where the Write-Ahead Logging comes into play.
8. Write-Ahead Logging #
With write-ahead logging, the DBMS records all the changes made to the database in a log file(on stable storage) before the change is made to a disk page. The log contains sufficient information to perform the necessary undo and redo actions to restore the database after a crash. The DBMS must write to disk the log file records that correspond to changes made to a database object before it can flush that object to disk.
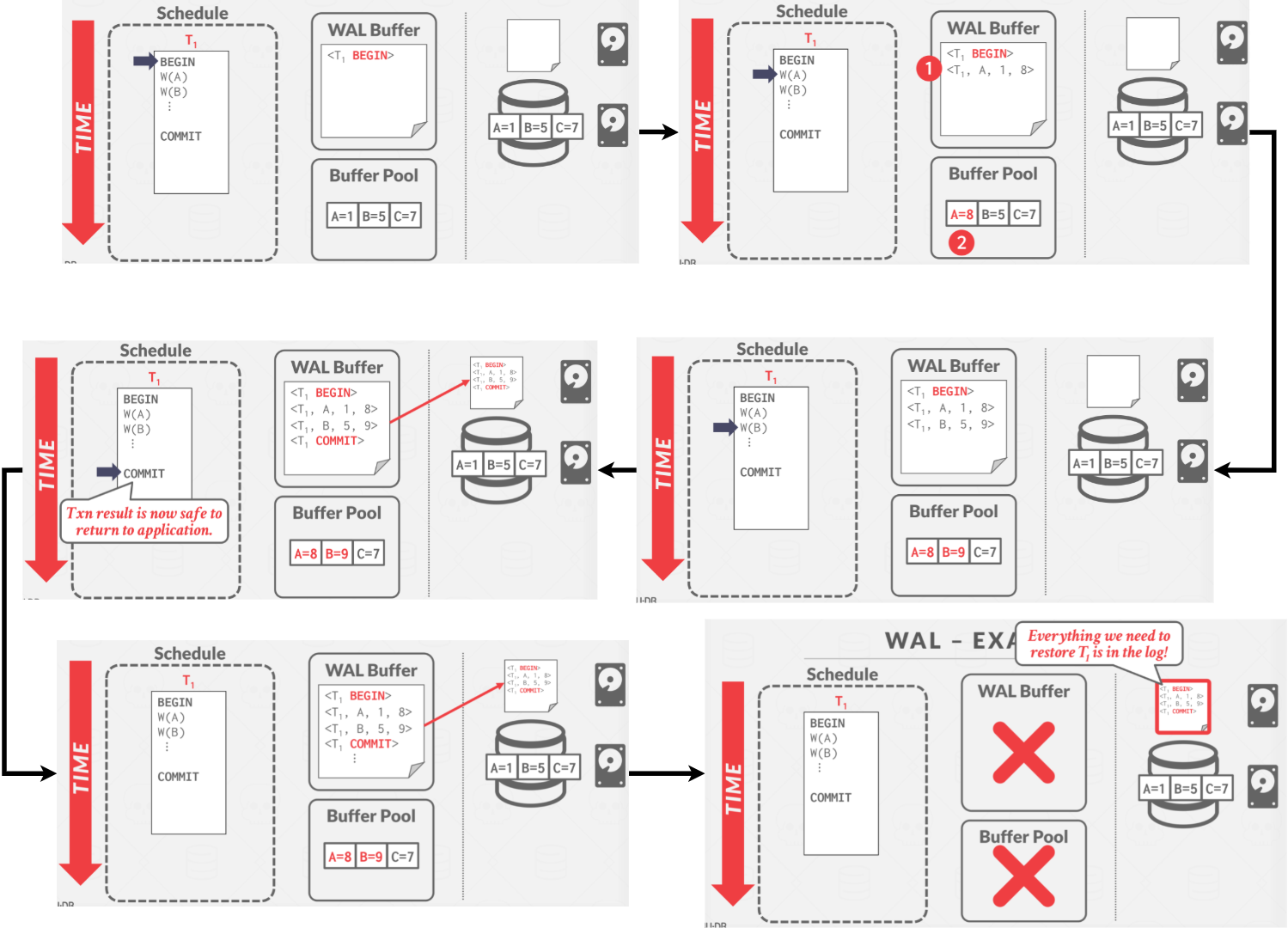
WAL is an example of STEAL + NO-FORCE system. An example of WAL is shown as following:
 |
|---|
| WAL example |
When the transaction begins, all changes are recorded in the WAL buffer in memory before being made to the buffer pool. At the time of commit, the WAL buffer is flushed out to disk. The transaction result can be written out to disk, once the WAL buffer is safely on disk.
Implementation
The DBMS first stages all of a transaction’s log records in volatile storage. All log records pertaining to an updated page are then written to non-volatile storage before the page itself is allowed to be overwritten in non-volatile storage.
A transaction is not considered committed until all its log records have been written to stable storage.
A brief WAL protocol would looks like this:
- Write a record to the log for each transaction to mark its starting point.
- When a transaction finishes, the DBMS will:
- Write a * record on the log
- Make sure that all log records are flushed before it return an acknowledgement to application.
- Each log entiry contains information about the change to a single object:
- Transaction Id
- Object Id
- Before Value(UNDO), It may not necessary if using append-only MVCC.
- After Value(REDO)
Then DBMS must flush all of a transaction’s log entries to disk before it can tell the ourside world that a transaction has successfully committed.
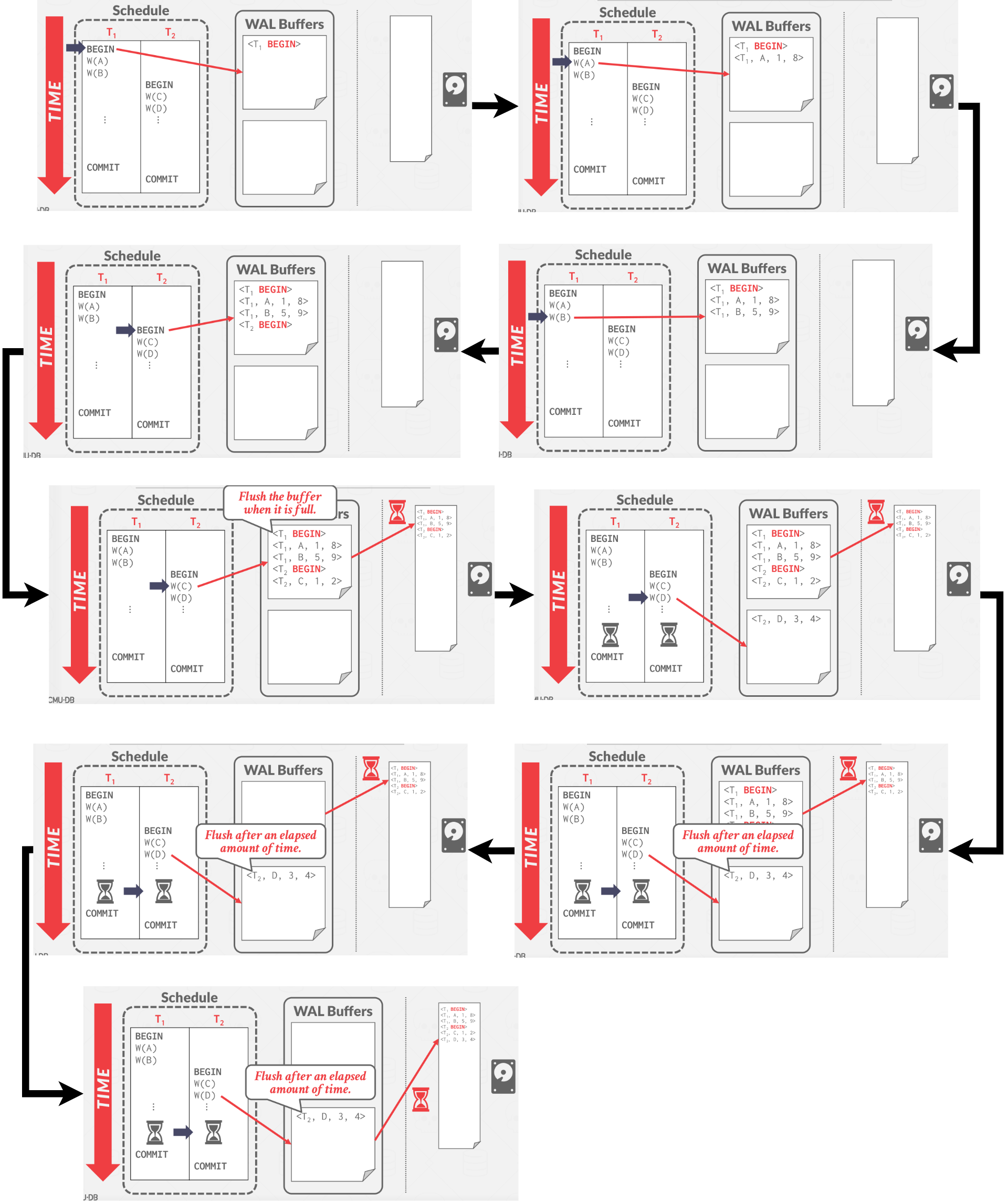
However, Flushing the log buffer to disk every time a transaction commits will become a bottleneck.
The DBMS can use the group commit optimization to batch multiple logs flushes to amortize overhead: Flushes happen either when the log buffer is full, or if sufficient time has passed between successive flushes.
 |
|---|
| WAL group commit example |
The DBMS can write dirty pages to disk whenever it wants to, as long as it is after flushing the corresponding log records.
Buffer Pool Policies
Almost every DBMS uses NO-FORCE + STEAL
 |
|---|
| Buffer Pool Policies |
9. Logging Schemes #
The contents of a log record can vary based on the implementation.
Physical Logging:
- Record the byte-level changes made to a specific location in the database.
- Example: git diff
Logical Logging:
- Record the high-level operations executed by transactions.
- Not necessarily restricted to a single page.
- Requires fewer data written in each log record than physical logging because each record can update multiple tuples over multiple pages. However, it is difficult to implement recovery with logical logging when there are concurrent transactions in a non-deterministic concurrency control scheme(Hard to determine which parts of the database been modified by a query before crash). Additionally, recovery takes longer because you must re-execute every transaction.
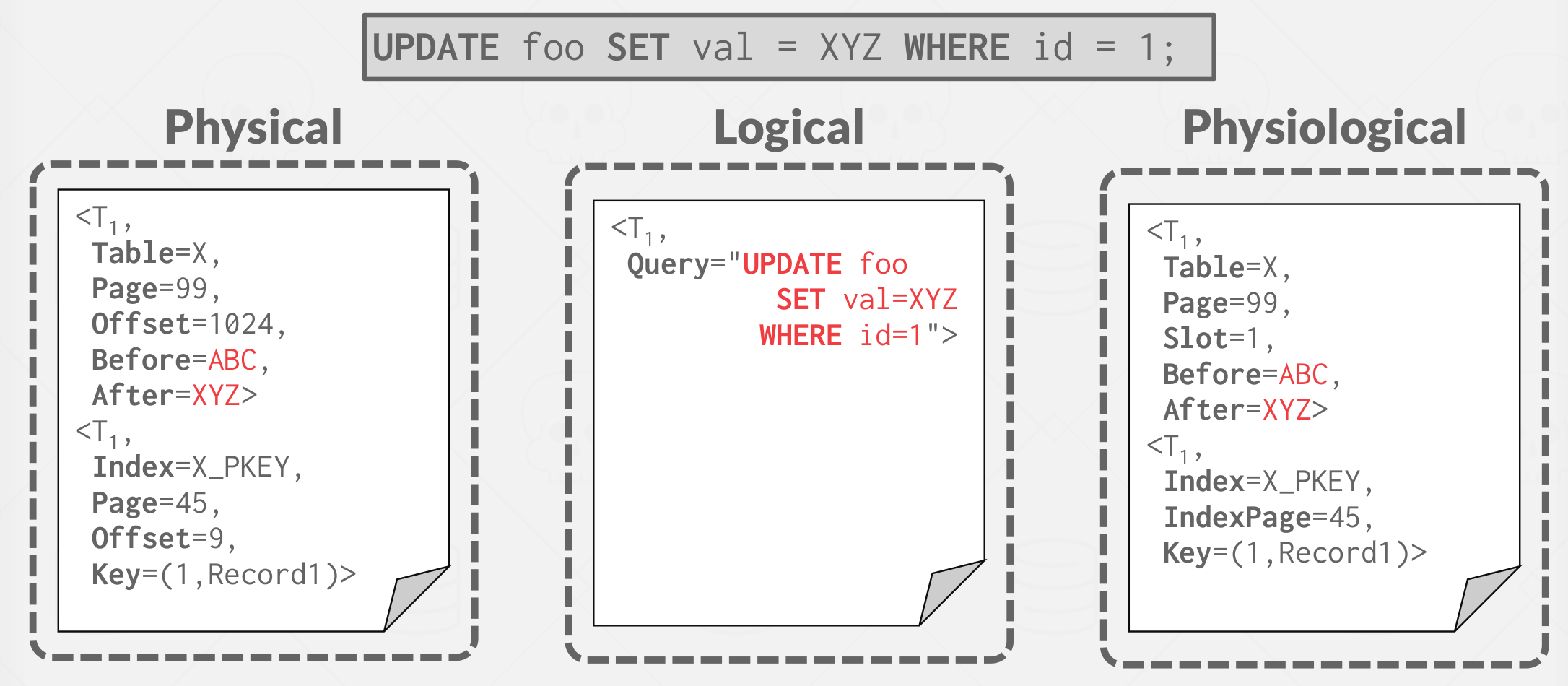
Physiological Logging:
- Hybrid approach where log records target a single page but do not specify data organization of the page, That is, identify tuples based on a slot number in the page without specifying exactly where in the page the change is located. Therefore the DBMS can reorganize pages after a log record has been written to disk.
- Most common approach used in DBMS.
 |
|---|
| Logging Schemes |
10. Log-Structured Systems #
Log-structured DBMSs do not have dirty pages, any page retrieved from disk is immutable.
The DBMS buffers log records in in-memory pages(Mem Table). If this buffer is full, it must be flushed to disk. But it may contain changes uncommitted transactions. These DBMSs still maintain a separate WAL to recreate the Mem Table on crash.
11. Checkpoints #
The main problem with a WAL-based DBMS is that the log file will grow forever. After a crash, the DBMS has to replay the entire log, which can take a long time if the log file is large. Thus, the DBMS can periodically take a checkpoint where it flushes all buffers out to disk. This provides a hint on how far back it needs to replay the WAL after a crash.
Blocking Checkpoint Implementation:
- Halt the start of any new transactions.
- Wait until all active transactions finish executing.
- Flush dirty pages to disk.
- Write a entry to WAL and flush to disk.
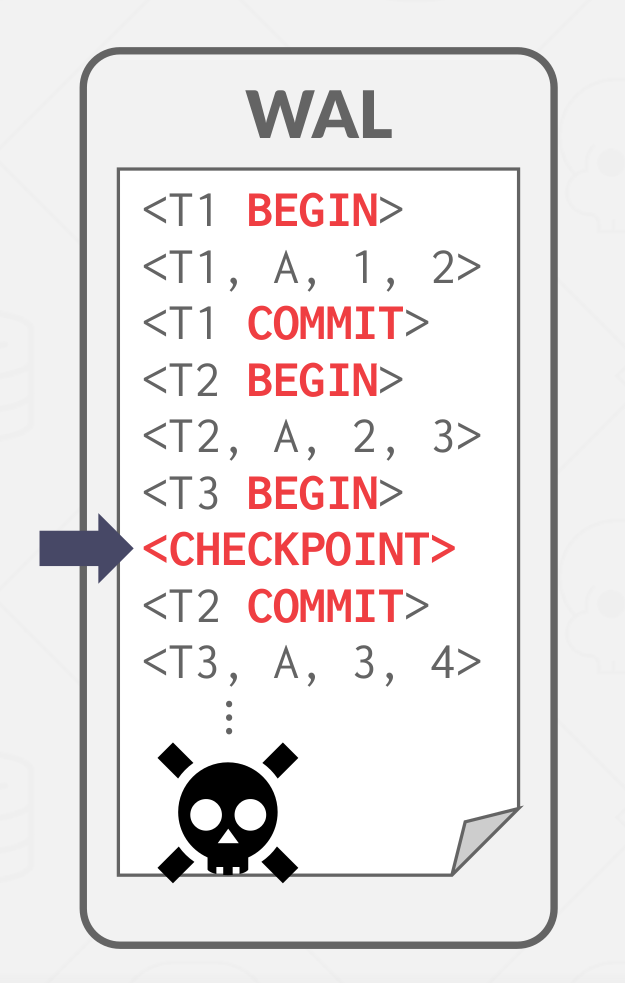
Use the record as the starting point for analyzing the WAL, for example:
 |
|---|
| an exmple of analyzing WAL |
- Any txn that committed before the checkpoint is ignored, e.g., \( T_1 \)
- \( T_2 \) + \( T_3 \) did not commit before the last checkpoing
- Need to redo \( T_2 \) because it committed after checkpoint
- Need to undo \( T_3 \) because it did not commit before crash
Checkpoint Challenges
- In this example, the DBMS must stall txns when it takes a checkpoint to ensure a consistent snapshot, we will see how to get around this problem next class.
- Scanning the log to find uncommitted txns can take a long time. Althouth, it is unvoidable but we will add hints to the record to speed things up next class.
- How often the DBMS should take a checkpoint depends on the application’s performance and downtime requirements. Taking a checkpoint too often causes the DBMS’s runtime performance to degrade. But waiting a long time between checkpoints can potentially be just as bad as the system’s recovery time after a restart increases.
12. Conclusion #
Write-Ahead Logging is (almost) always the best approach to handle loss of volatile storage.
Use incremental updates (STEAL + NO-FORCE) with checkpoints.
On Recovery: undo uncommitted txns + redo committed txns.