Multi-Version Concurrency Control #
A censorship circumvention tool may be required to open the links in this post from mainland of china.
1. Introduction #
Multi-Version Concurrency Control (MVCC) is a larger concept than just a concurrency control protocol.It involves all aspects of the DBMS’s design and implementation. MVCC is the most widely used scheme in DBMSs. It is now used in almost every new DBMS implemented in last 10 years. Even some systems (e.g., NoSQL) that do not support multi-statement transactions use it.
2. Multi-Version Concurrency Control #
With MVCC, the DBMS maintains multiple physical versions of a single logical object in the database. When a transaction writes to an object, the DBMS creates a new version of that object. When a transaction reads an object, it reads the newest version that existed when the transaction started.
The fundamental concept/benefit of MVCC is that writers do not block readers and readers do not block writers. This means that one transaction can modify an object while other transactions read old versions.
One advantage of using MVCC is that read-only transactions can read a consistent snapshot of the database without using locks of any kind. Additionally, multi-versioned DBMSs can easily support time-travel queries, which are queries based on the state of the database at some other point in time (e.g. performing a query on the database as it was 3 hours ago).
A simple MVCC example:
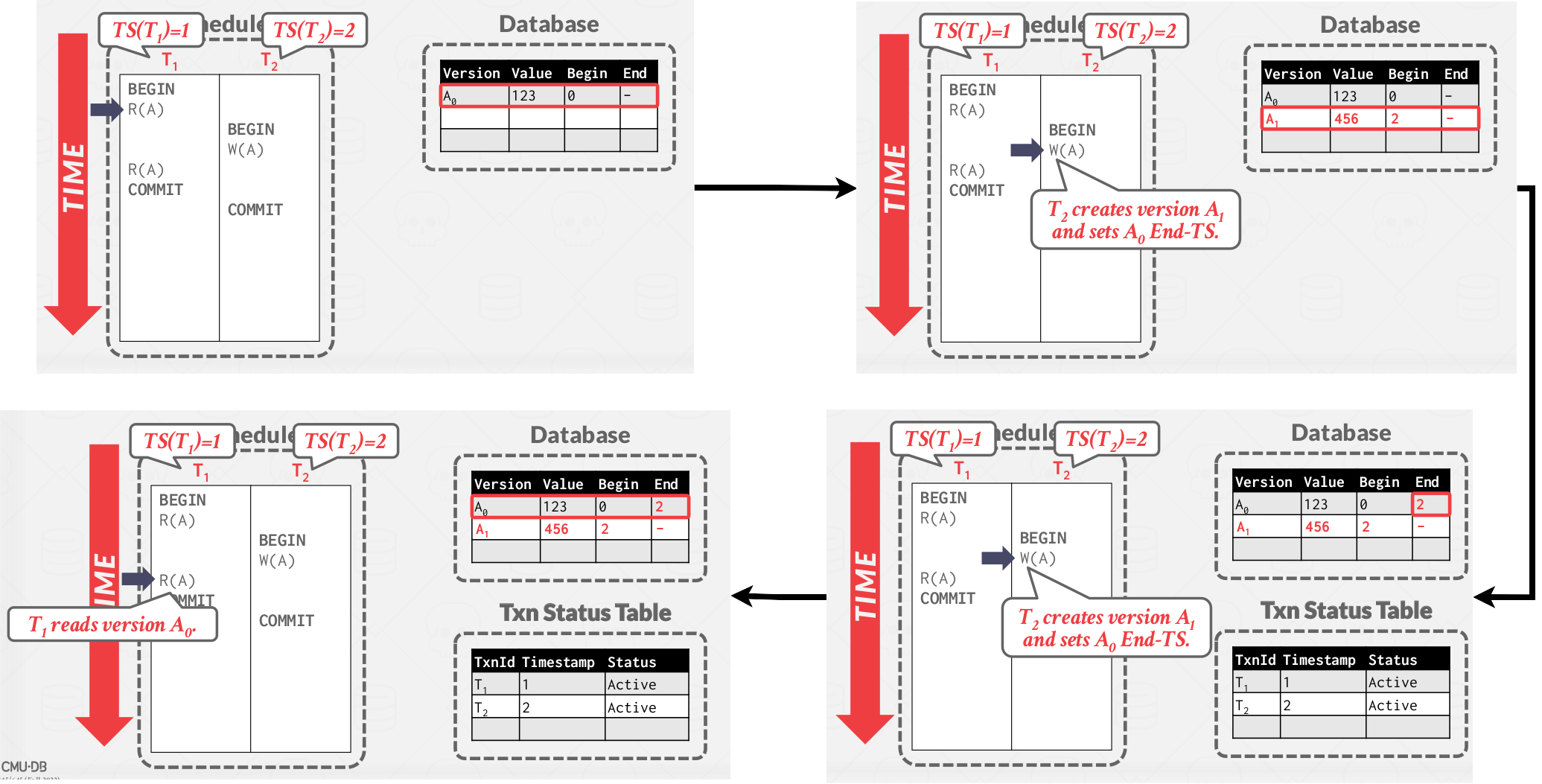 |
|---|
| MVCC example #1 |
A MVCC example with conflict:
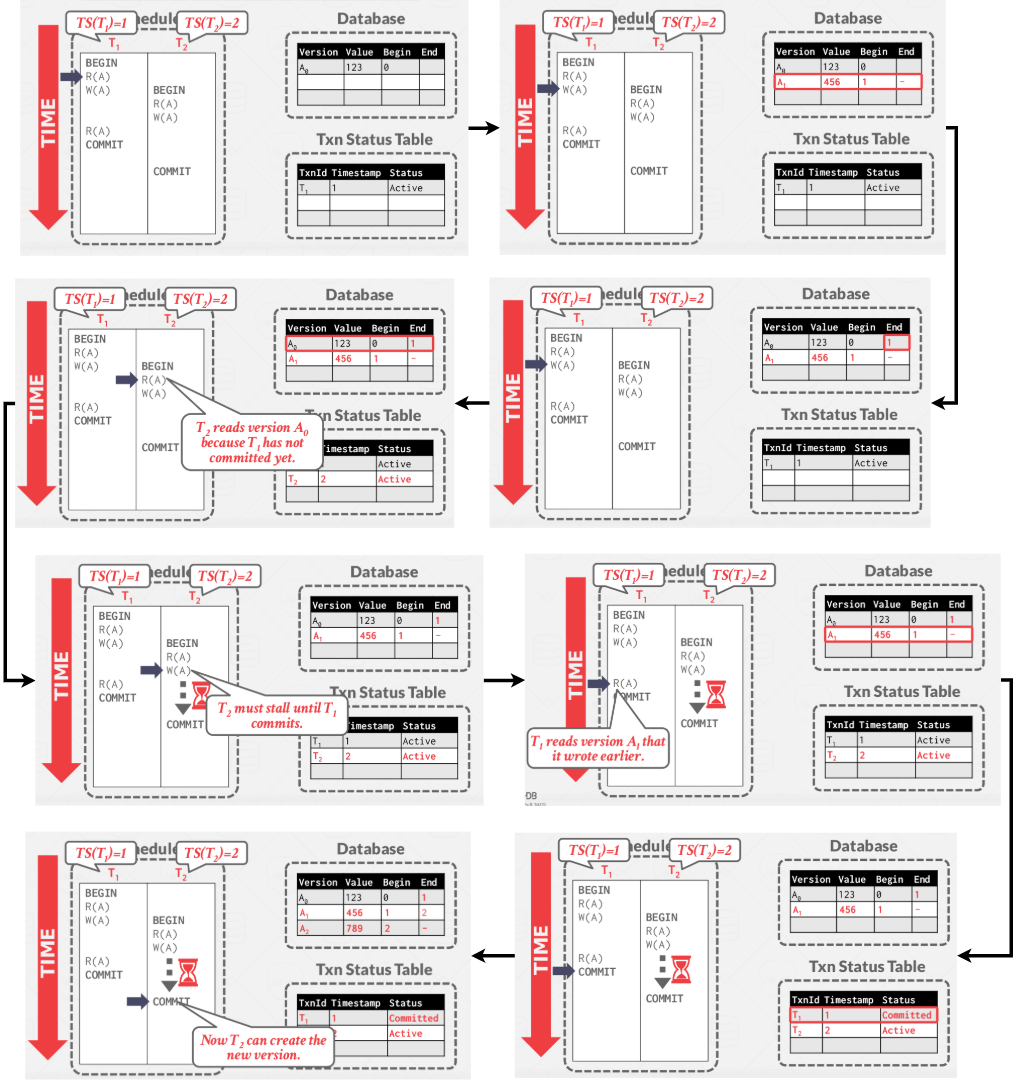 |
|---|
| MVCC example #2 |
Snapshot Isolation
Snapshot Isolation involves providing a transaction with a consistent snapshot of the database when the transaction started. Data values from a snapshot consist of only values from committed transactions, and the transaction operates in complete isolation from other transactions until it finishes. This is idea for read-only transactions since they do not need to wait for writes from other transactions. Writes are maintained in a transaction’s private workspace and only become visible to the database once the transaction successfully commits. If two transactions update the same object, the first writer wins.
Write Skew Anomaly can occur in Snapshot Isolation when two concurrent transaction modify different objects resulting in race conditions.
Assume we have a database of marbles and marbles can either be black or white, and there are two transactions run at exact same time the first transaction will change all the white marbles into black, and the second transaction will change all the black marbles into white.
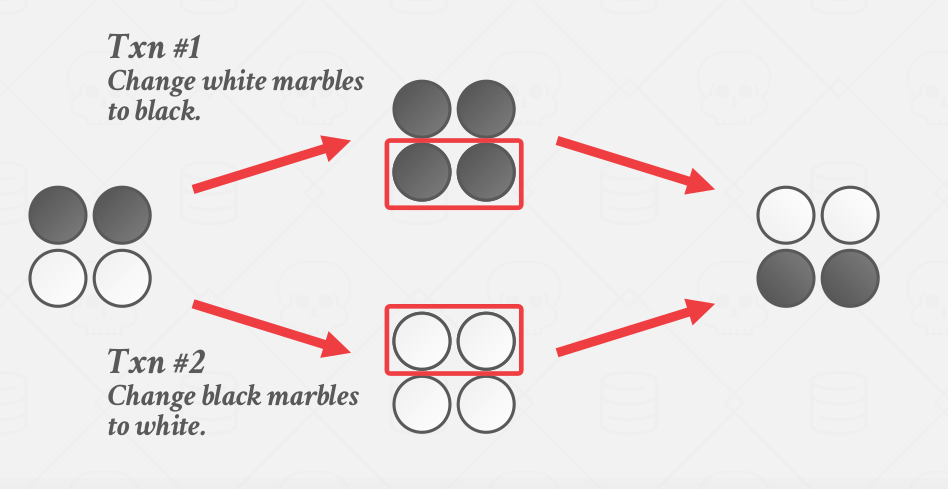 |
|---|
| Write Skew Anomaly with marbles example |
So the way it would work is they both first do a read on a consistent snapshot of the database under multi-versioning. They would see the database state described in the first column in the picture above. They would go and update the corresponding tuples and they both think they’ve done what they’re supposed to do(have all the white marbles black or have all the black marbles white). Still, the DBMS writes it back to the database because the DBMS does not take write locks on the objects(because there is technically no conflict between the two transactions), and the database ends up with the incorrect state(half white and half black). The serializable isolation would result in the correct state that is described in the picture below.
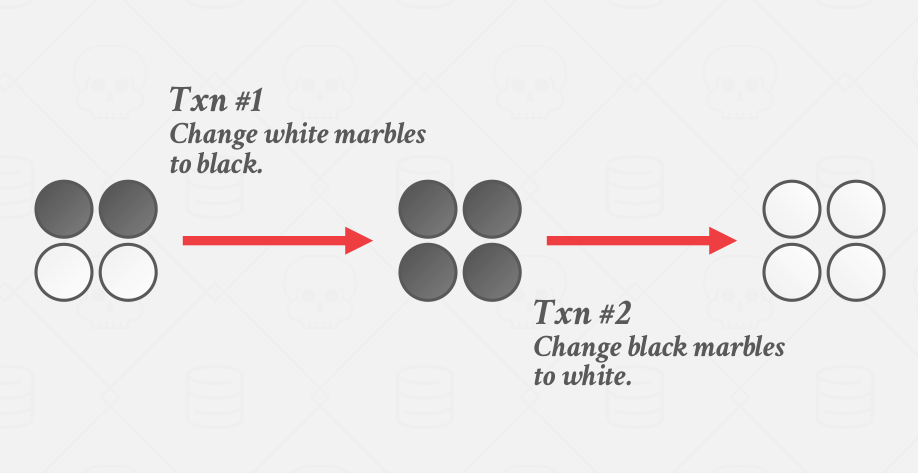 |
|---|
| One of correct serializable ordering of marbles example |
Again, MVCC is more than just a concurrency control protocol, It completely affects how the DBMS manages transactions and the databases.
There are four important MVCC design decisions:
- Concurrency Control Protocol
- Version Storage
- Garbage Collection
- Index Management
3. Concurrency Control Protocol #
The choice of concurrency protocol in MVCC is between the approaches discussed in previous lectures:
- Approach #1: Timestamp Ordering: Assign transaction timestamps that determine serial order.
- Approach #2: Optimistic Concurrency Control:
- Three-phase protocol that described in the last note
- Use private workspace for new versions.
- Approach #3: Two-Phase Locking: Transaction acquire appropriate lock on physical version before they can read/write a logical tuple.
Most system implement 2PL + MVCC.
4. Version Storage #
This how the DBMS will store the different physical versions of a logical object and how transactions find the newest version visible to them.
The DBMS uses the tuple’s pointer field to create a version chain per logical tuple, which is essentially a linked list of versions sorted by timestamp. This allows the DBMS to find the version that is visible to a particular transaction at runtime.
Indexes always point to the “head” of the chain, which is either the newest or oldest version depending on implementation. A thread traverses chain until it finds the correct version. Different storage schemes determine where/what to store for each version.
Approach #1: Append-Only Storage
All physical versions of a logical tuple are stored in the same table space. Versions are mixed together in the table and each update just appends a new version of the tuple into the table and updates the version chain. The chain can either be sorted oldest-to-newest (O2N) which requires chain traversal on look-ups, or newest-to-oldest (N2O), which requires updating index pointers for every new version.
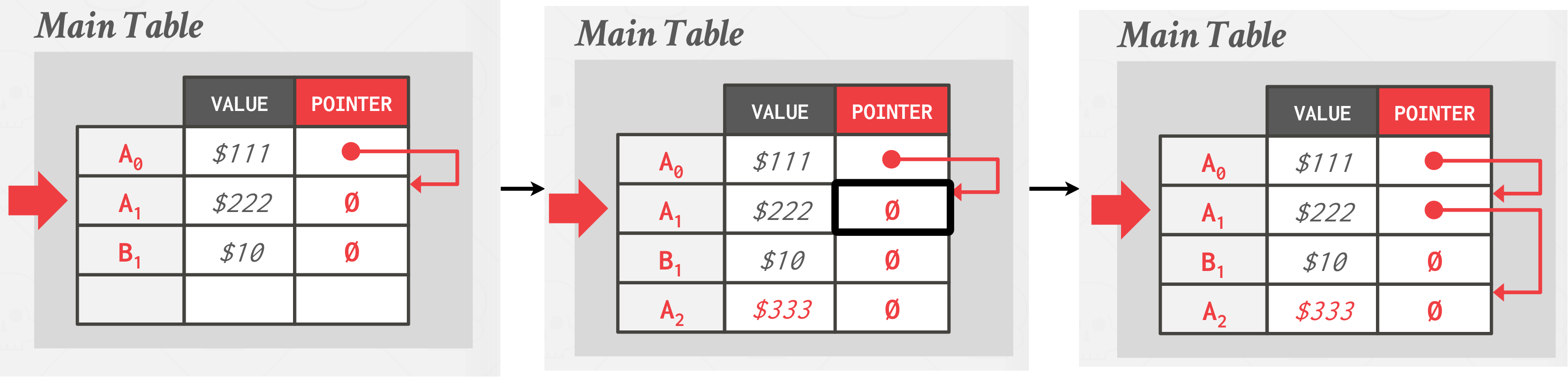 |
|---|
| Append-Only storage |
There are two version chain ordering
- Oldest-to-Newest (O2N):
- Append new version to end of the chain.
- Must traverse chain on look-ups.
- Newest-to-Oldest (N2O)
- Must update index pointers for every new version.
- Do not have to traverse chain on look-ups.
Postgres used to impelemented this approach with N2O.
Approach #2: Time-Travel Storage
The DBMS maintains a separate table called the time-travel table which stores older versions of tuples.
On every update, the DBMS copies the old version of the tuple to the time-travel table and overwrites the tuple in the main table with the new data. Pointers of tuples in the main table point to past versions in the time-travel table.
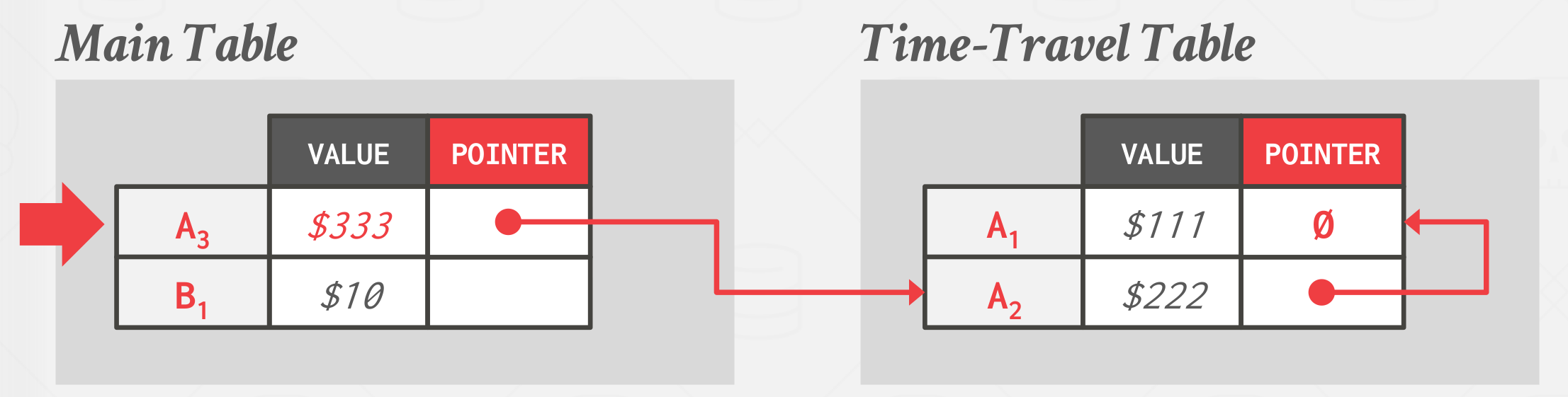 |
|---|
| Time-Travel Storage |
Approach #3: Delta Storage
Like time-travel storage, but instead of the entire past tuples, the DBMS only stores the deltas, or changes between tuples in what is known as the delta storage segment. Transactions can then recreate older versions by iterating through the deltas. This results in faster writes than time-travel storage but slower reads.
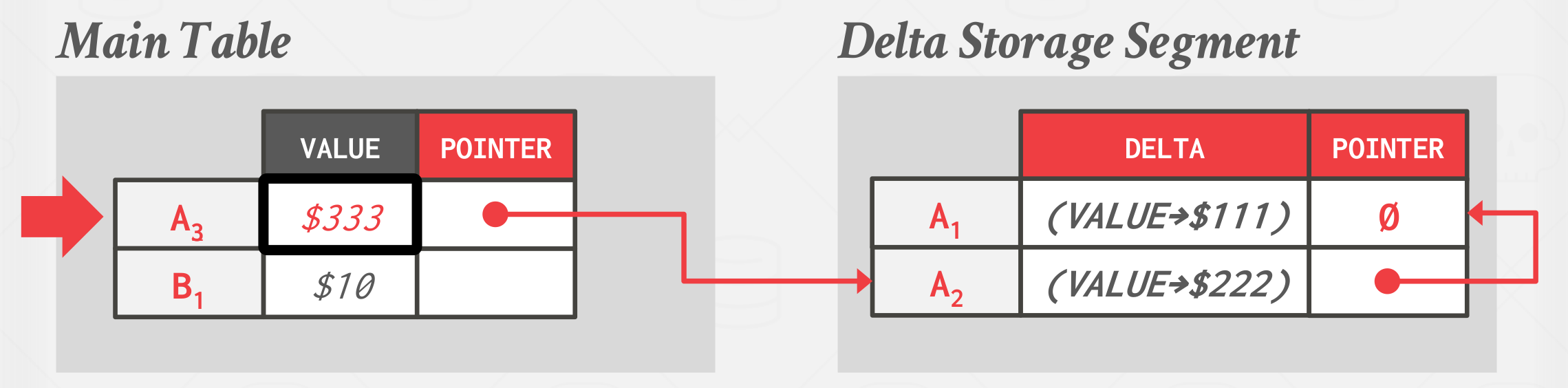 |
|---|
| Delta Storage |
MySql implemented with this approach.
5. Garbage Collection #
The DBMS needs to remove reclaimable physical versions from the database over time. A version is reclaimable if no active transaction can “see” that version or if it was created by a transaction that was aborted.
Approach #1: Tuple-level GC
With tuple-level garbage collection, the DBMS finds old versions by examining tuples directly. There are two approaches to achieve this:
-
Background Vacuuming: Separate threads periodically scan the table and look for reclaimable versions. This works with any version storage scheme. A simple optimization is to maintain a “dirty page bitmap,” which keeps track of which pages have been modified since the last scan. This allows the threads to skip pages which have not changed.
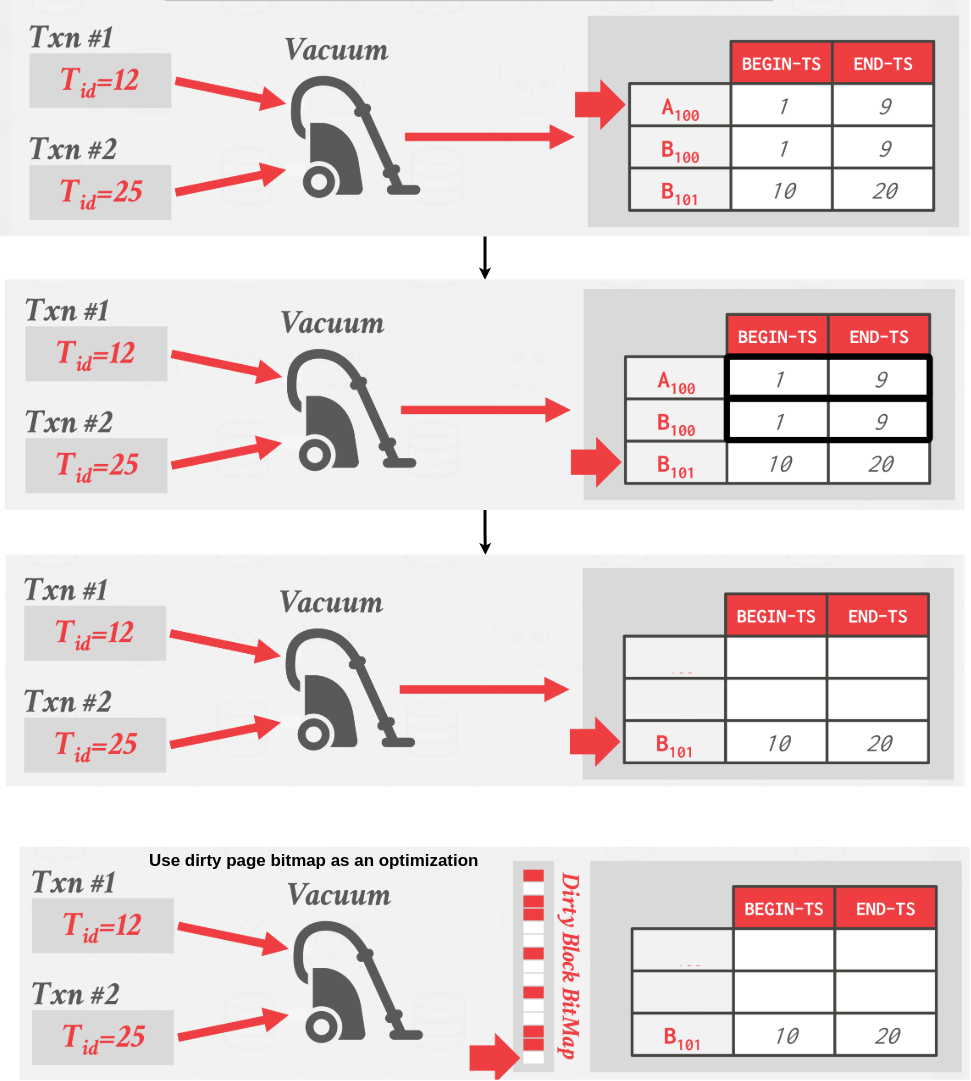
Background Vacuuming -
Cooperative Cleaning: Worker threads identify reclaimable versions as they traverse version chain. This only works with O2N chains.
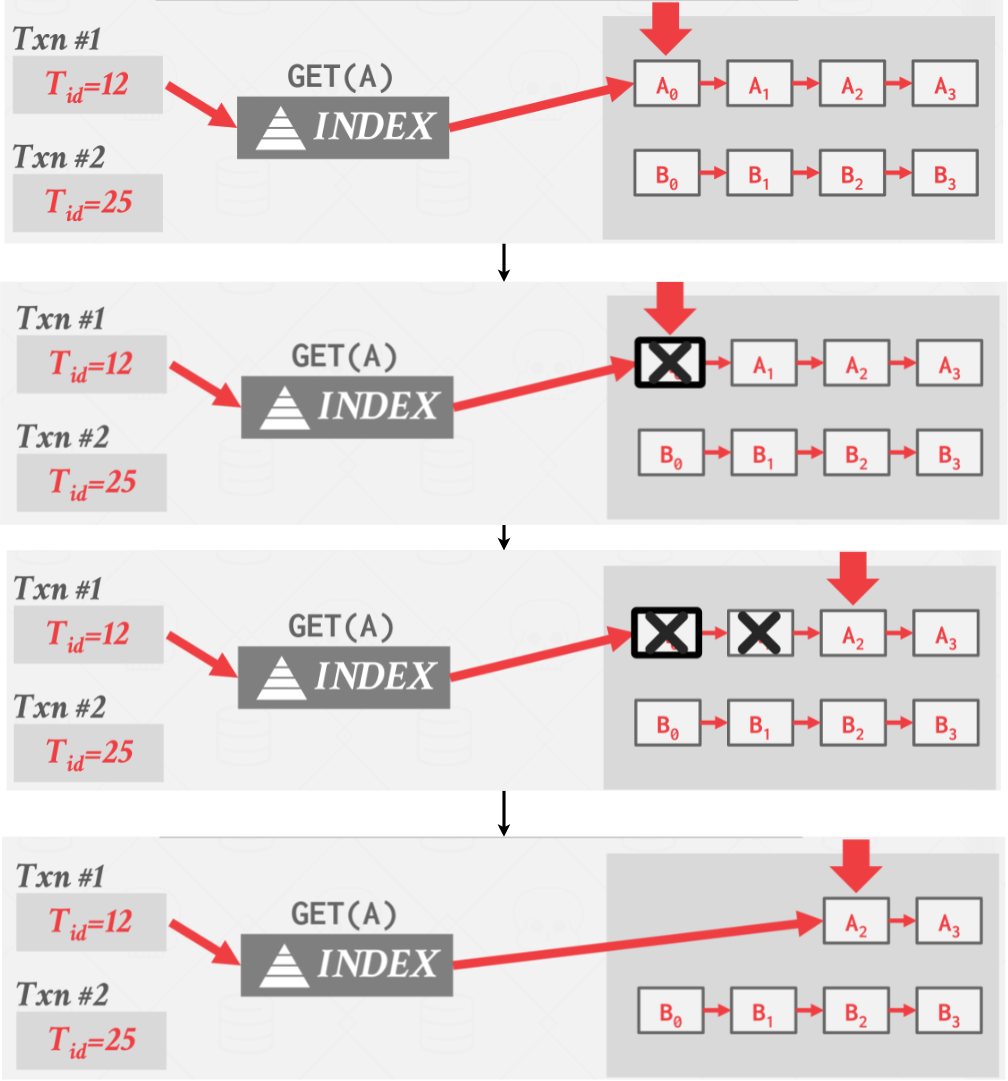
Cooperative Cleaning
Approach #2: Transaction-level GC
Under transaction-level garbage collection, each transaction is responsible for keeping track of their own old versions so the DBMS does not have to scan tuples. Each transaction maintains its own read/write set.
When a transaction completes, the garbage collector can use that to identify which tuples to reclaim. The DBMS determines when all versions created by a finished transaction are no longer visible.
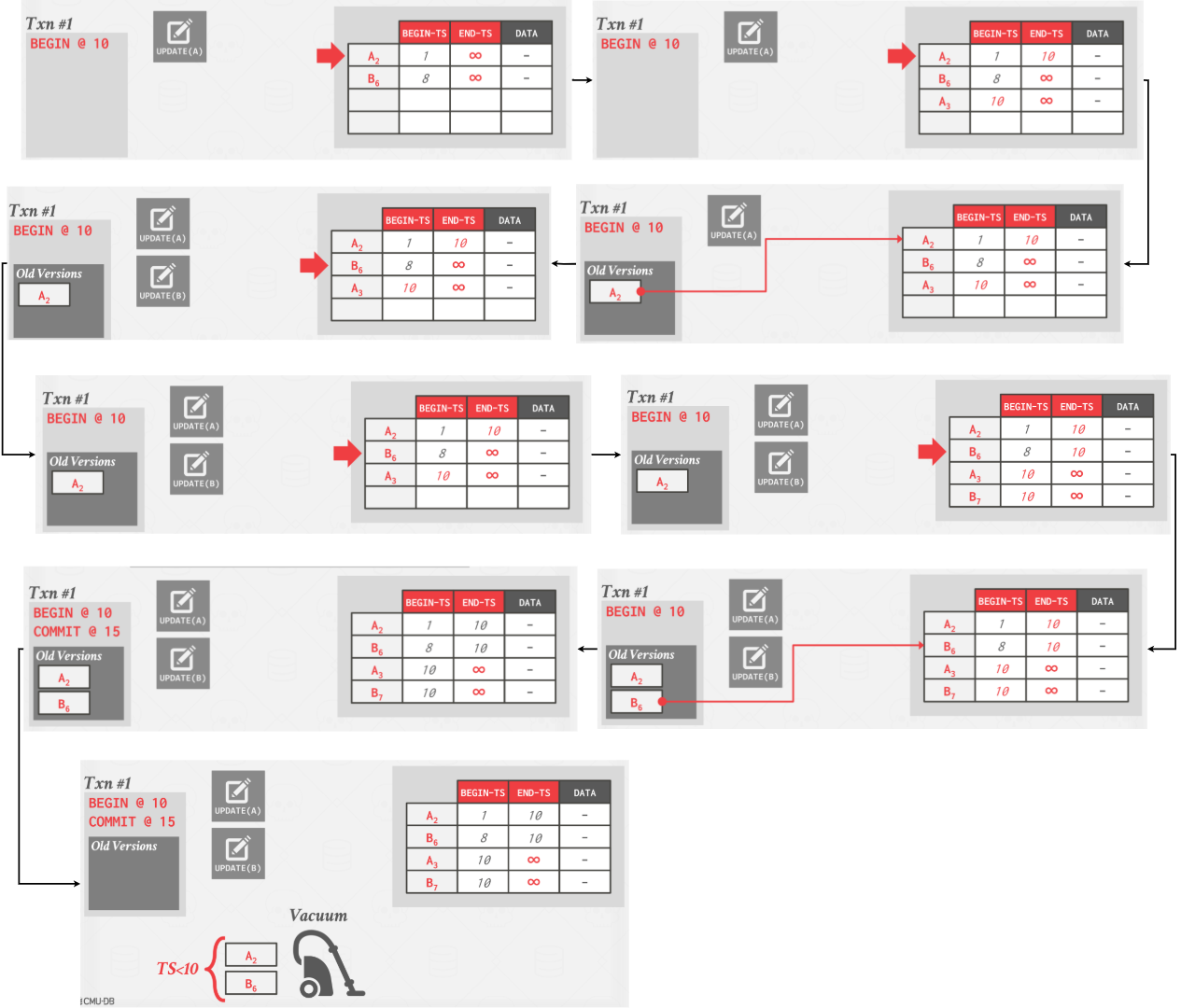 |
|---|
| Transaction-level GC |
6. Index management #
All primary key (pkey) indexes always point to version chain head. How often the DBMS has to update the pkey index depends on whether the system creates new versions when a tuple is updated. If a transaction updates a pkey attribute(s), then this is treated as a DELETE followed by an INSERT.
Managing secondary indexes is more complicated. There are two approaches to handling them.
Approach #1: Logical Pointers
- Use a fixed identifier per tuple that does not change.
- Requires an extra indirection layer.
- Primary Key vs. Tuple Id
The DBMS uses a fixed identifier per tuple that does not change. This requires an extra indirection layer that maps the logical id to the physical location of the tuple. Then, updates to tuples can just update the mapping in the indirection layer.
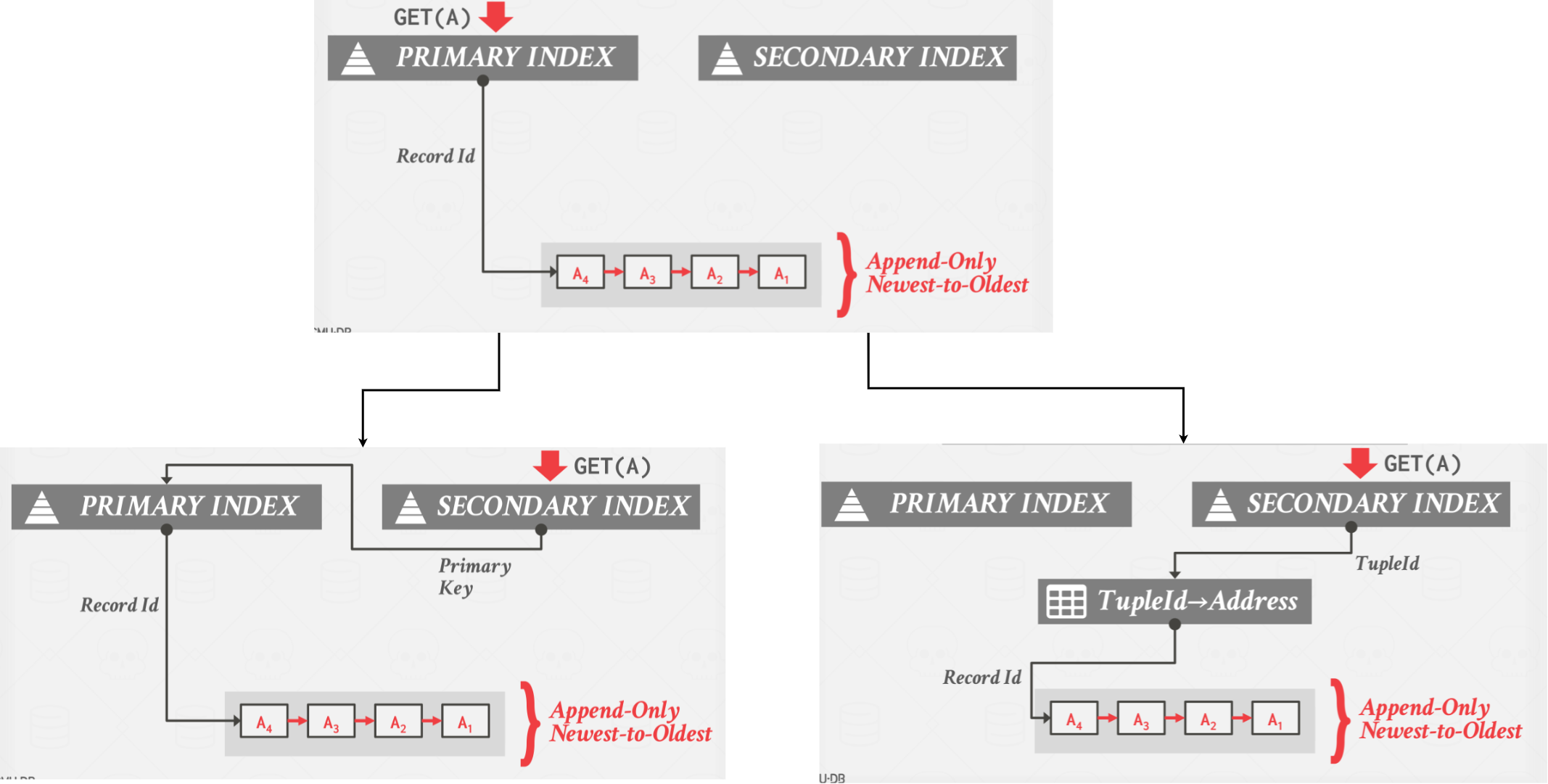 |
|---|
| Index Logical Pointers |
Approach #2: Physical Pointers
- Use the physical address to the version chain head.
- This requires updating every index when the version chain head is updated.
 |
|---|
| Index Physical Pointers |
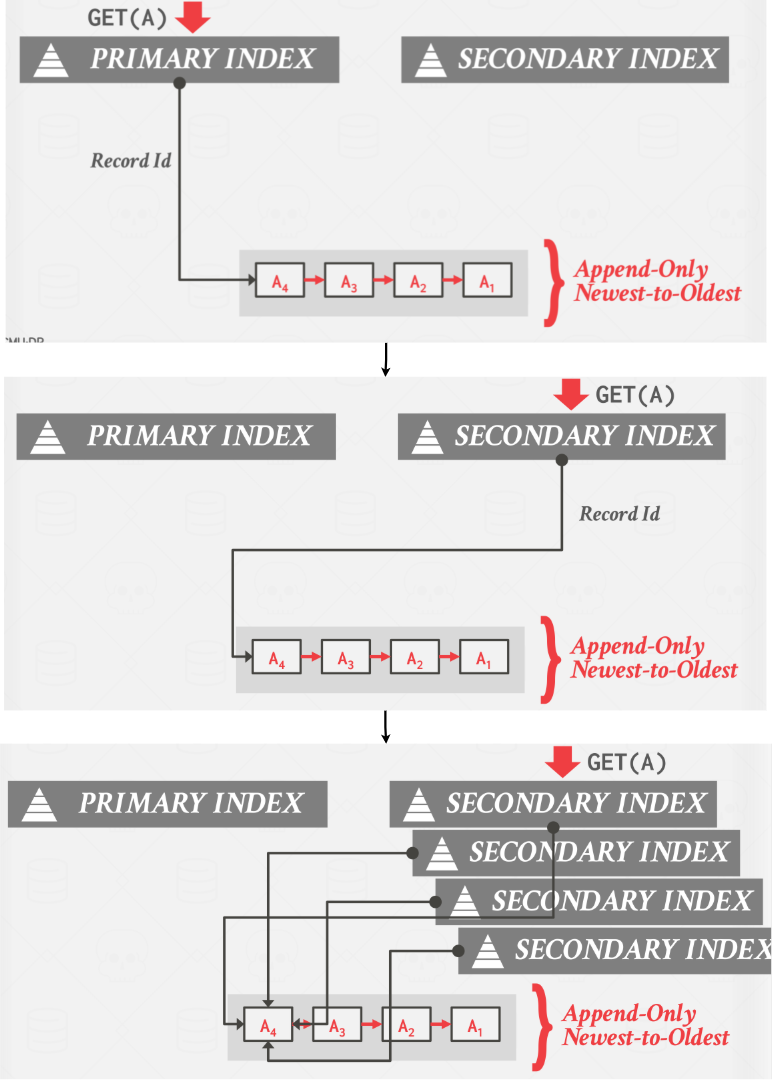
MVCC Indexes
MVCC DBMS indexes (usually) do not store version information about tuples with their keys, except Index-organized tables (e.g., MySQL).
Every index must support duplicate keys from different snapshots, because the same key may different logical tuples in different snapshots.
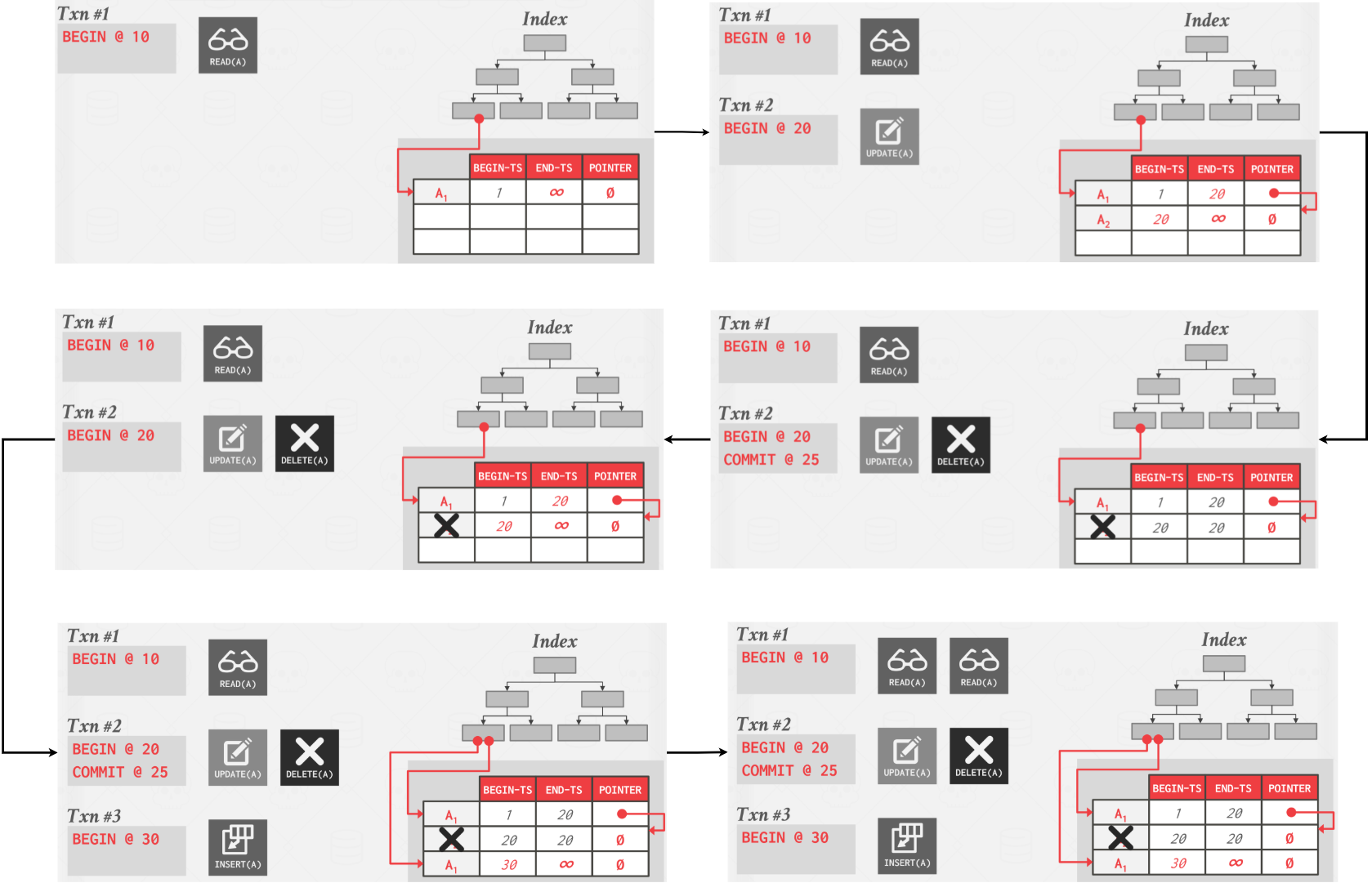 |
|---|
| MVCC duplicate key problem |
Each index’s underlying data structure must support the storage of non-unique keys.
Use additional execution logic to perform conditional inserts for pkey / unique indexes, e.g., Atomically check whether the key exists and then insert.
Workers may get back multiple entries for a single fetch. They then must follow the pointers to find the proper physical version.
MVCC Deletes
The DBMS physically deletes a tuple from the database only when all versions of a logically deleted tuple are not visible.
- If a tuple is deleted, then there cannot be a new version of that tuple after the newest version.
- No write-write conflicts / first-writer wins
We need a way to denote that tuple has been logically delete at some point in time.
- Approach #1: Deleted Flag
- Maintain a flag to indicate that the logical tuple has been deleted after the newest physical version.
- Can either be in tuple header or a separate column.
- Approach #2: Tombstone Tuple
- Create an empty physical version to indicate that a logical tuple is deleted.
- Use a separate pool for tombstone tuples with only a special bit pattern in version chain pointer to reduce the storage overhead.
7. MVCC Implementations #
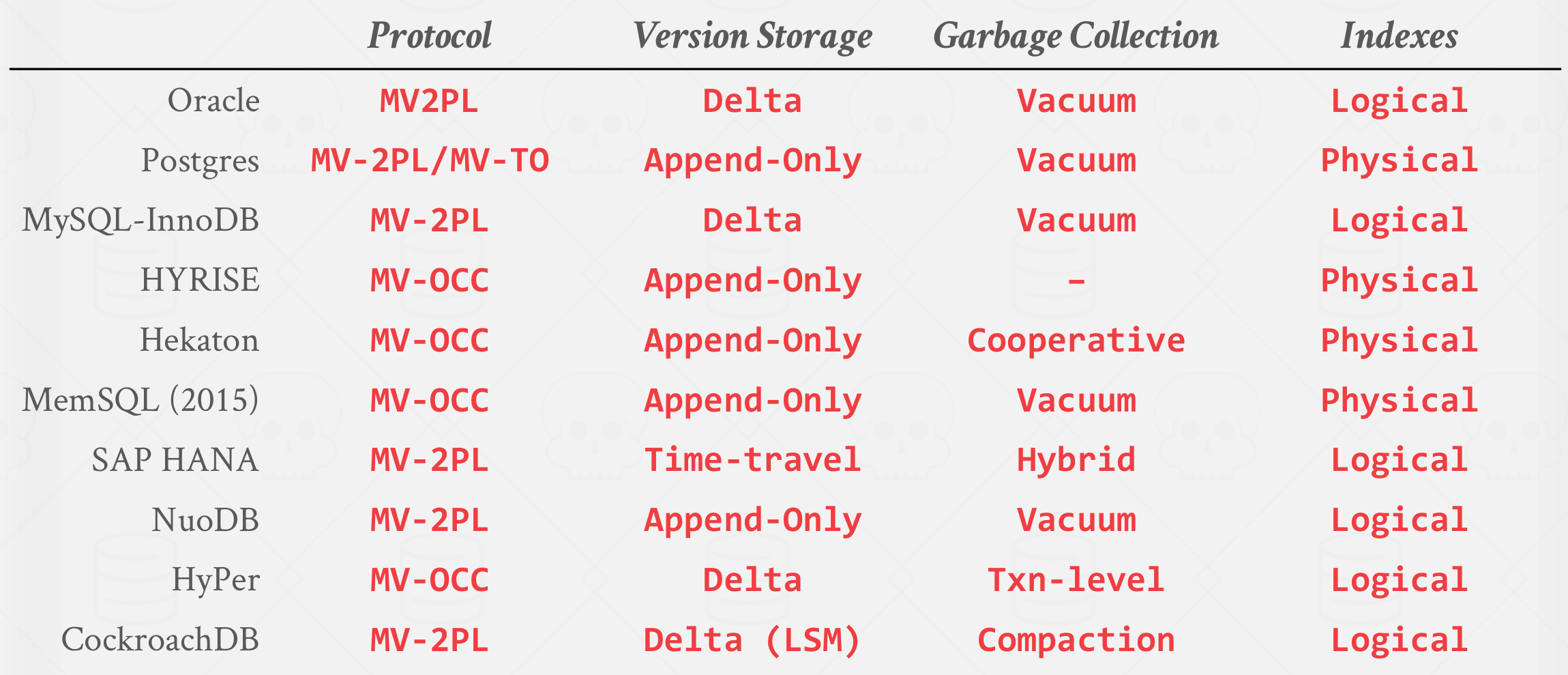 |
|---|
| MVCC Implementations |
8. Conclusion #
MVCC is the widely used scheme in DBMSs. Even systems that do not support multi-statement transactions (e.g., NoSQL) use it.