Timestamp Ordering Concurrency Control #
A censorship circumvention tool may be required to open the links in this post from mainland of china.
1. Introduction #
2PL determine the serializability order of conflicting operations at runtime while transactions execute, and it is known as a Pessimistic concurrency control protocol, meaning DBMS assume that there are going to be conflicts in transactions, therefore, the DBMS will require the transactions to acquire the locks before they can do whatever it is that the transactions want to do and then DBMS can use the Two-Phase locking protocol to decide that is the transaction allowed acquire lock or not.
Timestamp ordering (T/O) is an optimistic class of concurrency control protocols where the DBMS assumes that transaction conflicts are rare. Instead of requiring transactions to acquire locks before they are allowed to read/write to a database object, the DBMS instead uses timestamps to determine the serializability order of transactions.
2. Timestamp Ordering Concurrency Control #
The T/O(Timestamp Ordering) Concurrency Control uses timestamps to determine the serializability order of transactions.
Each transaction \( T_i \) is assigned a unique fixed timestamp TS( \( T_i \) ) that is monotonically increasing. Different schemes assign timestamps at different times during the transaction. Some advanced schemes even assign multiple timestamps per transaction.
If TS( \( T_i \) ) < TS( \( T_j \) ), then the DBMS must ensure that the execution schedule is equivalent to the serial schedule where \( T_i \) appears before \( T_j \) .
There are multiple timestamp allocation implementation strategies.
- The DBMS can use the system clock as a timestamp, but issues arise with edge cases like daylight savings.
- Another option is to use a logical counter. However, this has issues with overflow and with maintaining the counter across a distributed system with multiple machines.
- There are also hybrid approaches that use a combination of both methods.
3. Basic Timestamp Ordering(BASIC T/O) #
The basic timestamp ordering protocol (BASIC T/O) allows reads and writes on database objects without using locks(without explicit locks).
Every object X is tagged with timestamp of the last transaction that successfully did read/write:
- W-TS(X) - Write timestamp on X
- R-TS(X) - Read timestamp on X
The DBMS then checks these timestamps for every operation. If a transaction tries to access an object in a way which violates the timestamp ordering, the transaction is aborted and restarted. The underlying assumption is that violations will be rare and thus these restarts will also be rare.
Read Operations
For read operations, if TS( \( T_i \) ) < W-TS(X), this violates timestamp order of \( T_i \) with regard to the previous writer of X (do not want to read something that is written in the “future”). Thus, \( T_i \) is aborted and restarted with a new timestamp.
Otherwise, the read is valid and \( T_i \) perform:
- Allow \( T_i \) to Read X.
- Updates R-TS(X) to be the max of R-TS(X) and TS( \( T_i \) ).
- Make a local copy of X in a private workspace to ensure repeatable reads for \( T_i \)
Write Operations
For write operations, if TS( \( T_i \) ) < R-TS(X) or TS( \( T_i \) ) < W-TS(X), \( T_i \) must be restarted (do not want to overwrite “future” change).
Otherwise, the write is valid and \( T_i \) perform:
- Allows \( T_i \) to write X
- Updates W-TS(X).
- Again, it needs to make a local copy of X to ensure repeatable reads for \( T_i \) .
Basic T/O example #1
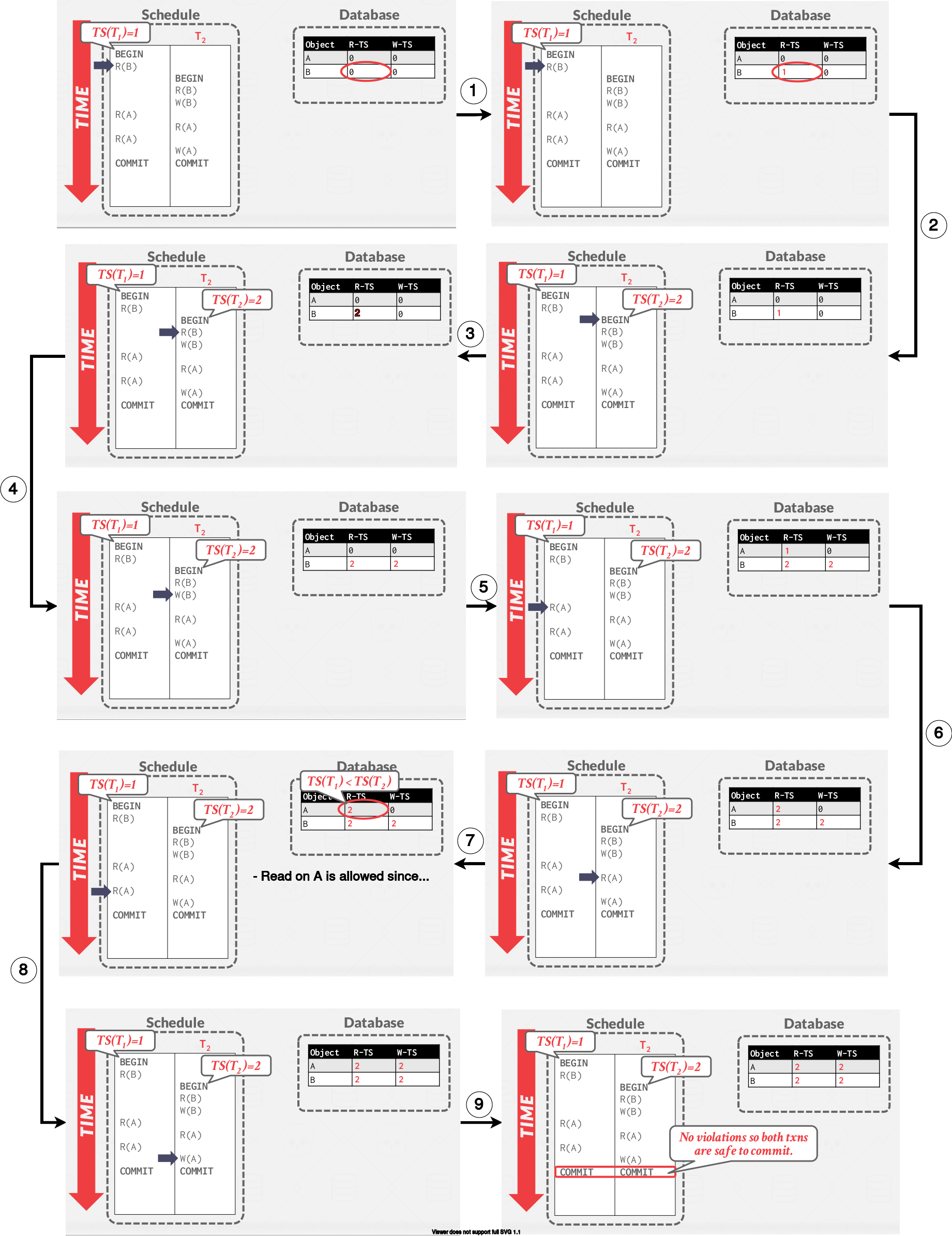 |
|---|
| Basic T/O example #1 |
Basi T/O example #2
Let’s take a look at another example where we do abort.
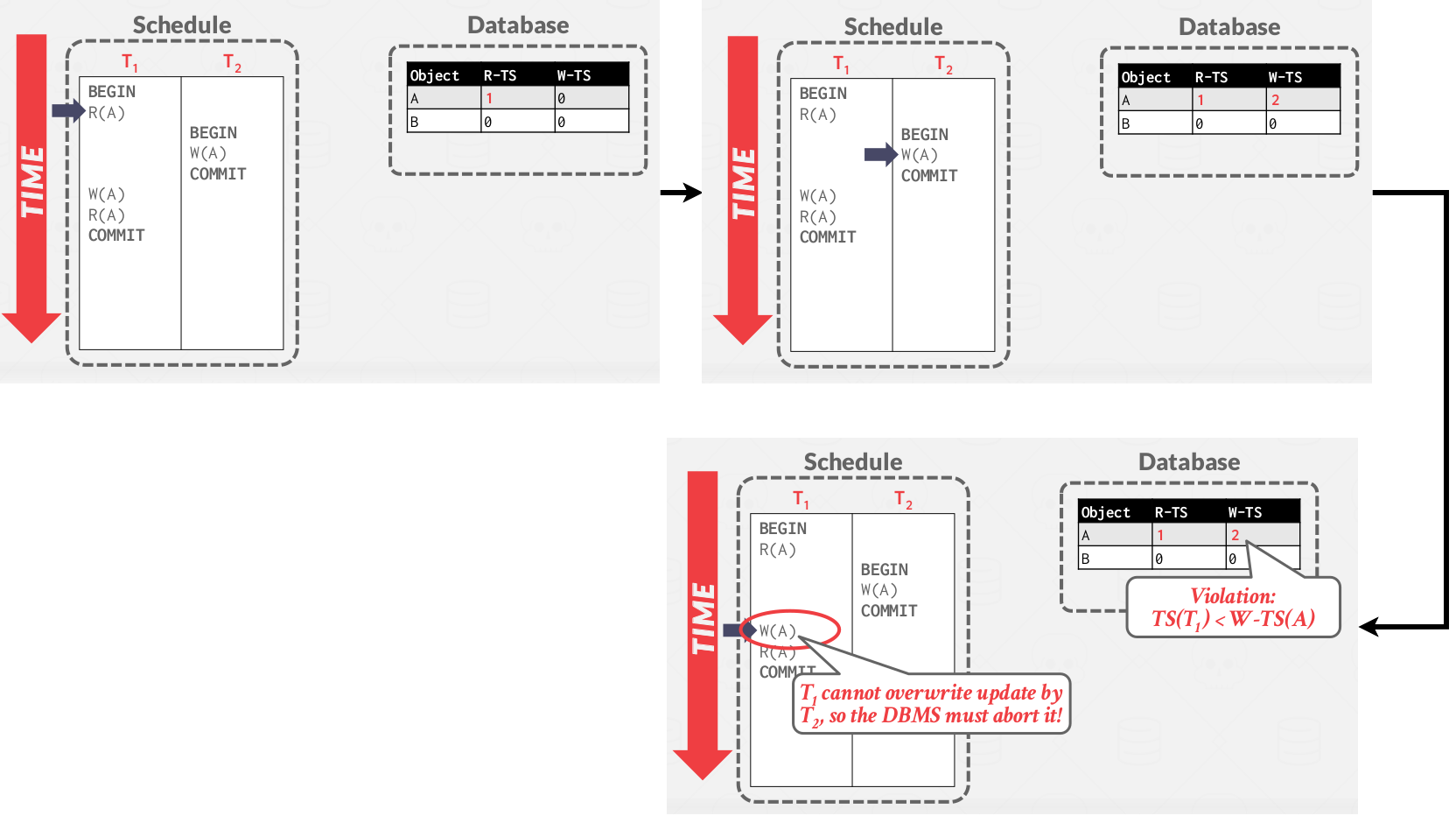 |
|---|
| Basic T/O example #2 |
Optimization: Thomas Write Rule:
If TS( \( T_i \) ) < R-TS(X)
- Abort and restart TS( \( T_i \) )
If TS( \( T_i \) ) < W-TS(X)
- Thomas Write Rule: Ignore the write to allow the txn to continue executing without aborting.
- This violates timestamp order of \( T_i \)
Else
- Allows \( T_i \) to write X and Update W-TS(X)
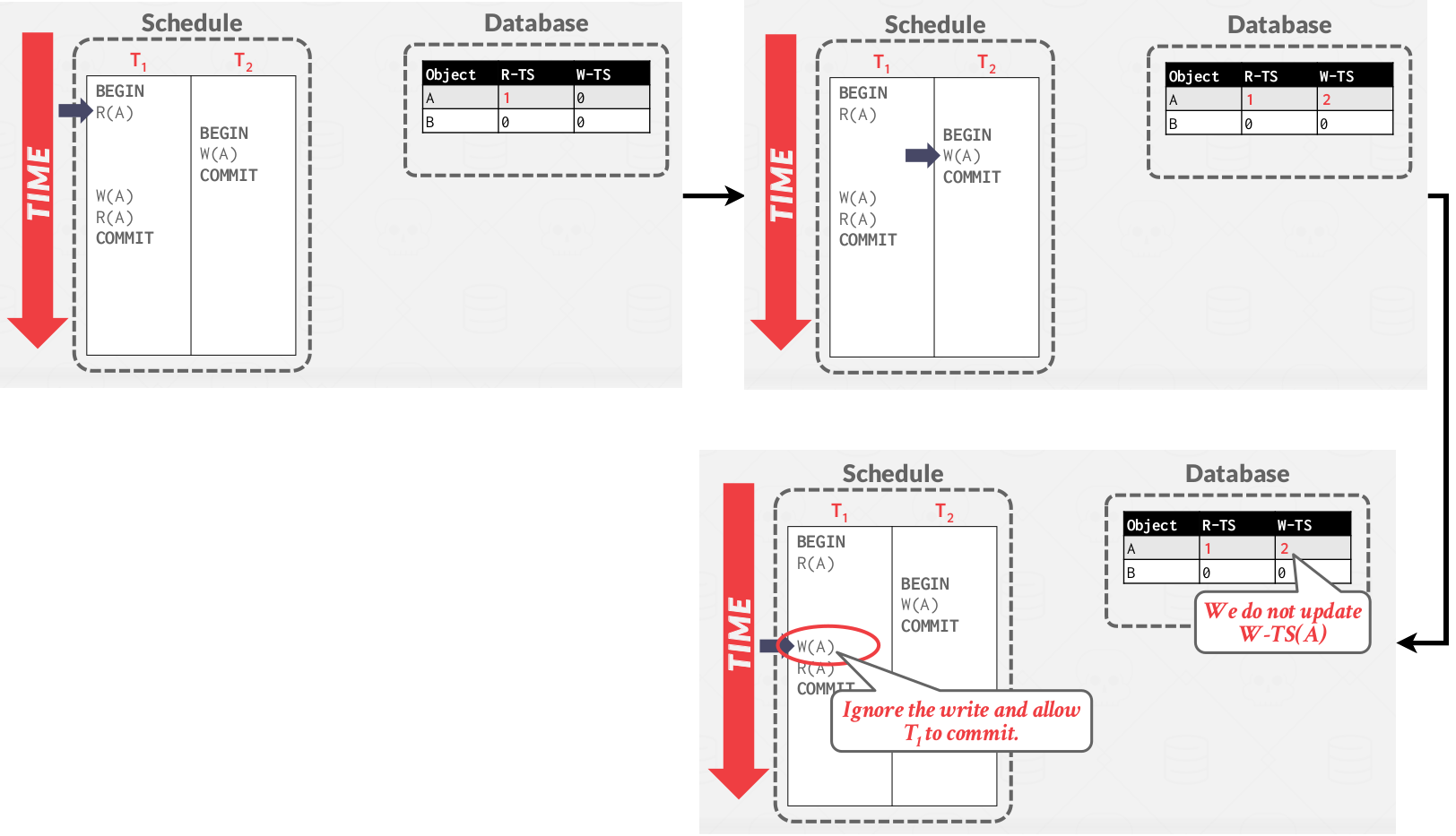 |
|---|
| Basic T/O example #2 With Tomas Write Rule |
Notes:
- Logically, it is equal to the serial order of TS( \( T_1 \) ) followed by TS( \( T_2 \) ).
- The Read on A that is followed by Write on A of TS( \( T_1 \) ) will read his own writes. Although, it violates the read rules(TS( \( T_i \) ) < W-TS(X)), it is okay to allow it if it is reading his own write(this could lead to the View Serializable land).
Recap on Basic T/O
The Basic T/O protocol generates a schedule that is conflict serializable if it does not use Thomas Write Rule. It cannot have deadlocks because no transaction ever waits. However, there is a possibility of starvation for long transactions if short transactions keep causing conflicts.
Andy is not aware of any DBMS that uses the basic T/O protocol described here. But it provides the building blocks for OCC/MVCC.
Basic T/O Performance Issues
- High overhead from copying data to transaction’s workspace and from updating timestamps. Every read requres the txn to write to database, i.e, every read becomes to write.
- Long running transactions can get starved. The likelihood that a transaction will read something from a newer transaction increases.
- Suffers from the timestamp allocation bottleneck on highly concurrent systems.
4. Optimistic Concurrency Control(OCC) #
If you assume that conflicts between txns are rare and that most txns are short-lived, then forcing txns to acquire locks or update timestamps adds unnecessary overhead.
A better approach is to optimize for the no-conflict case.
Optimistic concurrency control (OCC) is another optimistic concurrency control protocol which also uses timestamps to validate transactions. OCC works best when the number of conflicts is low.
This is when either all of the transactions are read-only or when transactions access disjoint subsets of data. If the database is large and the workload is not skewed, then there is a low probability of conflict, making OCC a good choice.
In OCC, the DBMS creates a private workspace for each transaction.
- All modifications of the transaction are applied to this workspace.
- Any object read is copied into workspace and any object written is copied to the workspace and modified there. No other transaction can read the changes made by another transaction in its private workspace.
When a transaction commits, the DBMS compares the transaction’s workspace write set to see whether it conflicts with other transactions. If there are no conflicts, the write set is installed into the “global” database.
OCC consists of three phases:
- Read Phase: Here, the DBMS tracks the read/write sets of transactions and stores their writes in a private workspace.
- Validation Phase: When a transaction commits, the DBMS checks whether it conflicts with other transactions.
- Write Phase: If validation succeeds, the DBMS applies the private workspace changes to the database. Otherwise, it aborts and restarts the transaction.
An example of OCC:
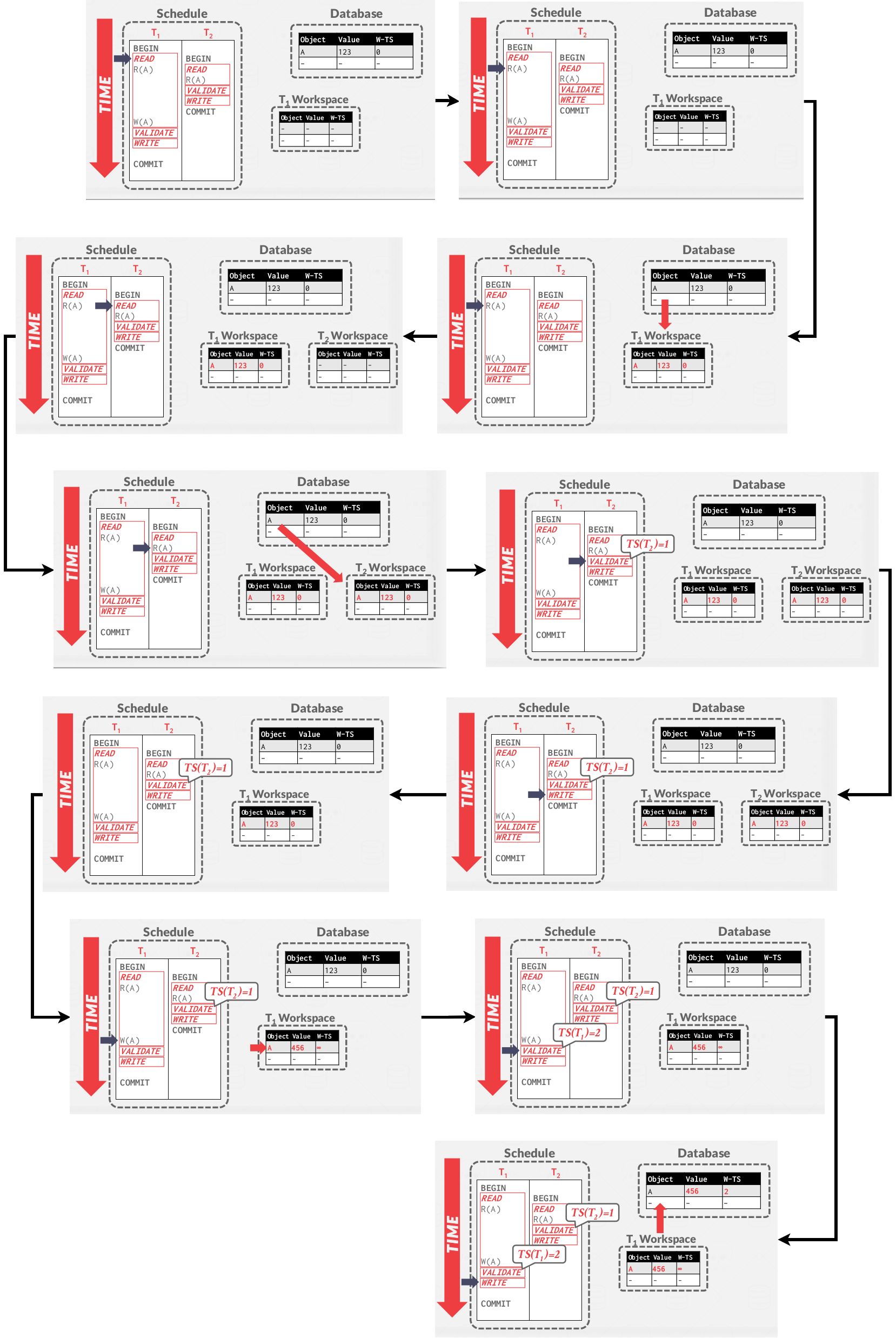 |
|---|
| An example of OCC |
Read Phase
The DBMS copies every tuple that the txn accesses from the shared database to its workspace ensure repeatable reads. and track the read/write sets of txns and store their writes in a private workspace.
We can ignore for now what happens if a txn reads/writes tuples via indexes(it will be covered in the MVCC).
Validation Phase
The DBMS assigns transactions timestamps when they enter the validation phase. To ensure only serializable schedules are permitted, the DBMS checks \( T_i \) against other transactions for RW and WW conflicts and makes sure that all conflicts go one way.
- Approach 1: Backward validation(from younger transactiions to older transactions). Check whether the committing txn intersects its read/write sets with those of any txns that have already committed.
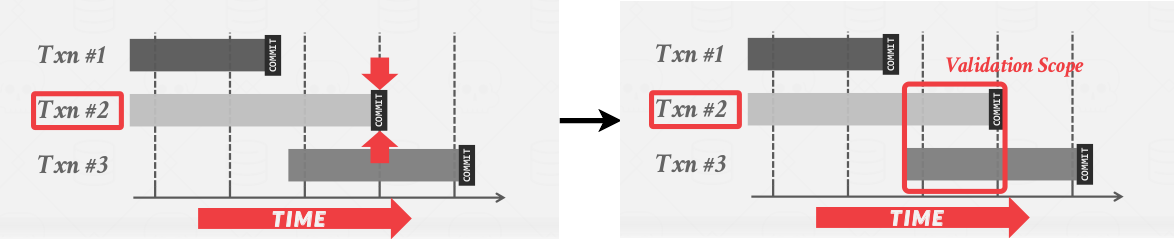 |
|---|
| Backward validation |
- Approach 2: Forward validation(from older transactions to younger transactions). Check whether the committing txn intersects its read/write sets with any active txns that have not yet committed.
|
|---|
| Forward validation |
Here we describes how forward validation works. The DBMS checks the timestamp ordering of the committing transaction with all other running transactions. Transactions that have not yet entered the validation phase are assigned a timestamp of \( \infty \) .
If TS( \( T_i \) ) < TS( \( T_j \) ), then one of the following three conditions must hold:
-
\( T_i \) completes all three phases before \( T_j \) begins its execution (serial ordering). This just means that there is serial ordering.
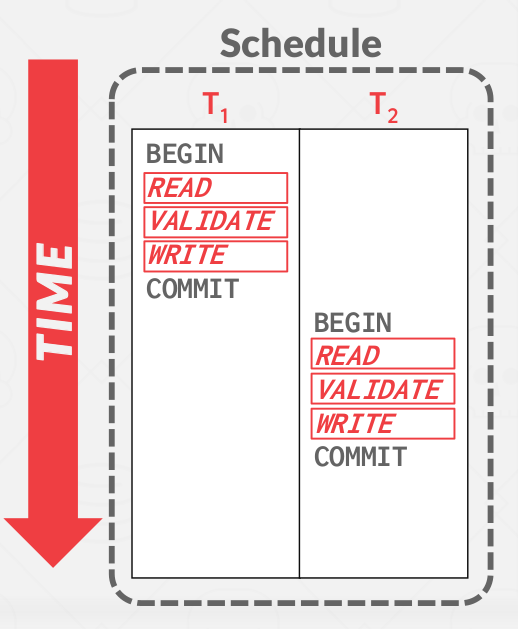
Validation case #1 -
\( T_i \) completes before \( T_j \) starts its Write phase, and \( T_i \) does not write to any object read by \( T_j \) .
- WriteSet( \( T_i \) ) \( \cap \) ReadSet( \( T_j \) ) = \( \varnothing \) .
Validate violation example:
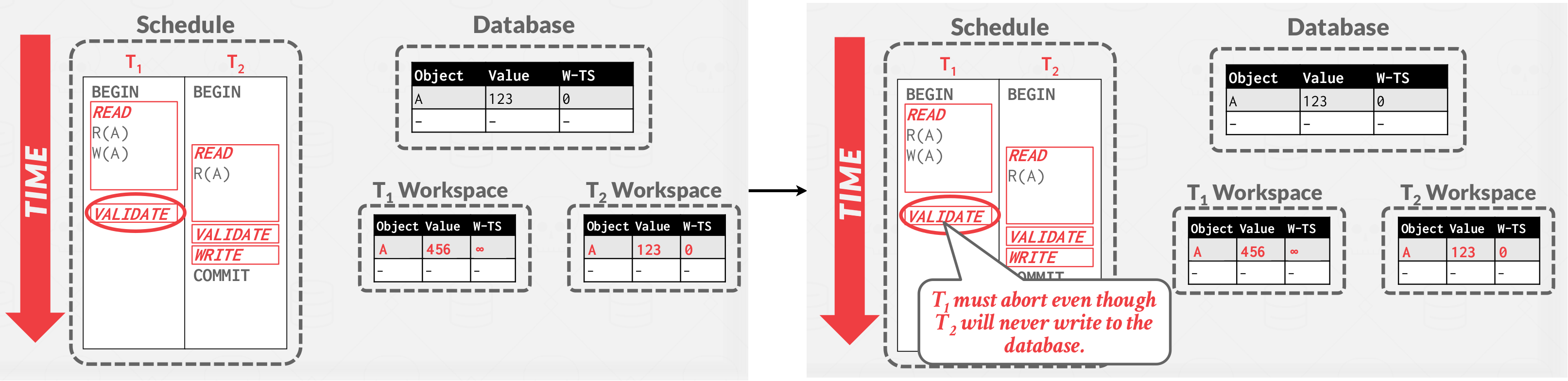
Validate violation example: WriteSet( \( T_1 \) ) \( \cap \) ReadSet( \( T_2 \) ) \( \ne \) \( \varnothing \) Validate pass example:
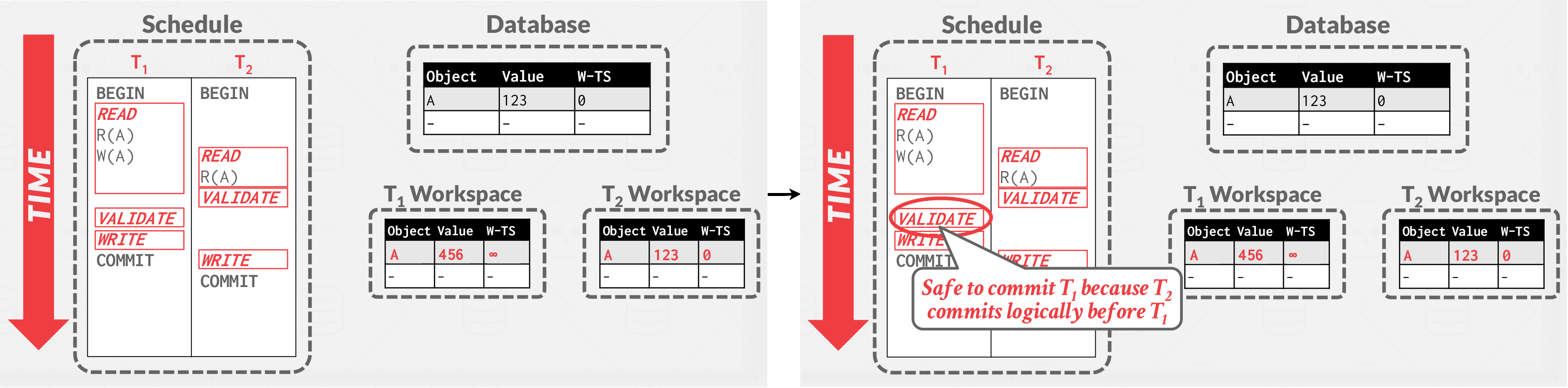
Validate pass example: WriteSet( \( T_1 \) ) \( \cap \) ReadSet( \( T_2 \) ) = \( \varnothing \) -
\( T_i \) completes its Read phase before \( T_j \) completes its Read phase, and \( T_i \) does not write to any object that is either read or written by \( T_j \) .
- WriteSet( \( T_i \) ) \( \cap \) ReadSet( \( T_j \) ) = \( \varnothing \) , and WriteSet( \( T_i \) ) \( \cap \) WriteSet( \( T_j \) ) = \( \varnothing \) .
Validate pass example:
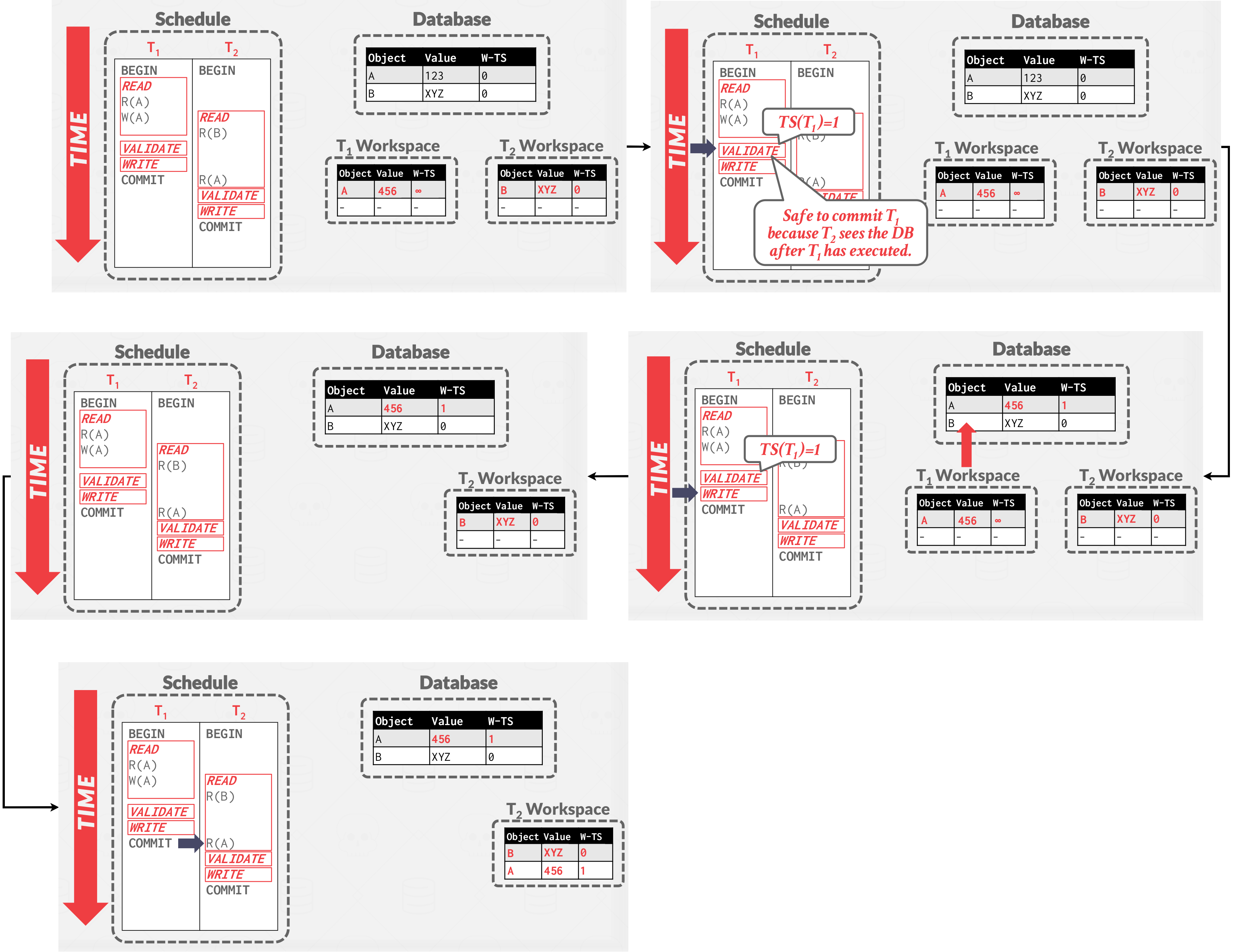
Validate pass example: \( T_1 \) does not write to any object that is either read or written by \( T_2 \)
Write Phase
The DBMS applies the private workspace changes to the database. Otherwise, propagate changes in the txn’s write set to database to make them visible to other txns.
- Serial Commits: Use a global latch to limit a single txn to be in the Validation/Write phases at a time.
- Parallel Commits: Use fine-grained write latches to support parallel Validation/Write* phases, transactions acquire latchs in primary key order to avoid deadlocks.
Observations
OCC works well when the number of confilicts is low, e.g., All transactions are read-only(ideal) or transactions access sisjoint subsets of data.
If the database is large and the workload is not skewed, then there is a low probability of conflict, so again locking is wateful.
Performance Issues
- High overhead for copying data locally into the transaction’s private workspace.
- Validation/Write phase bottlenecks, because the validation process need to check all the active transactions.
- Aborts are potentially more wasteful than in other protocols(e.g. 2PL) because they only occur after a transaction has already executed
- Suffers from timestamp allocation bottleneck.
5. The Phantom problem #
Recall that so far, we have only dealt with transactions that read and update existing objects in the database.
But now if transactions perform insertion, updates and deletiions, we have new problems…
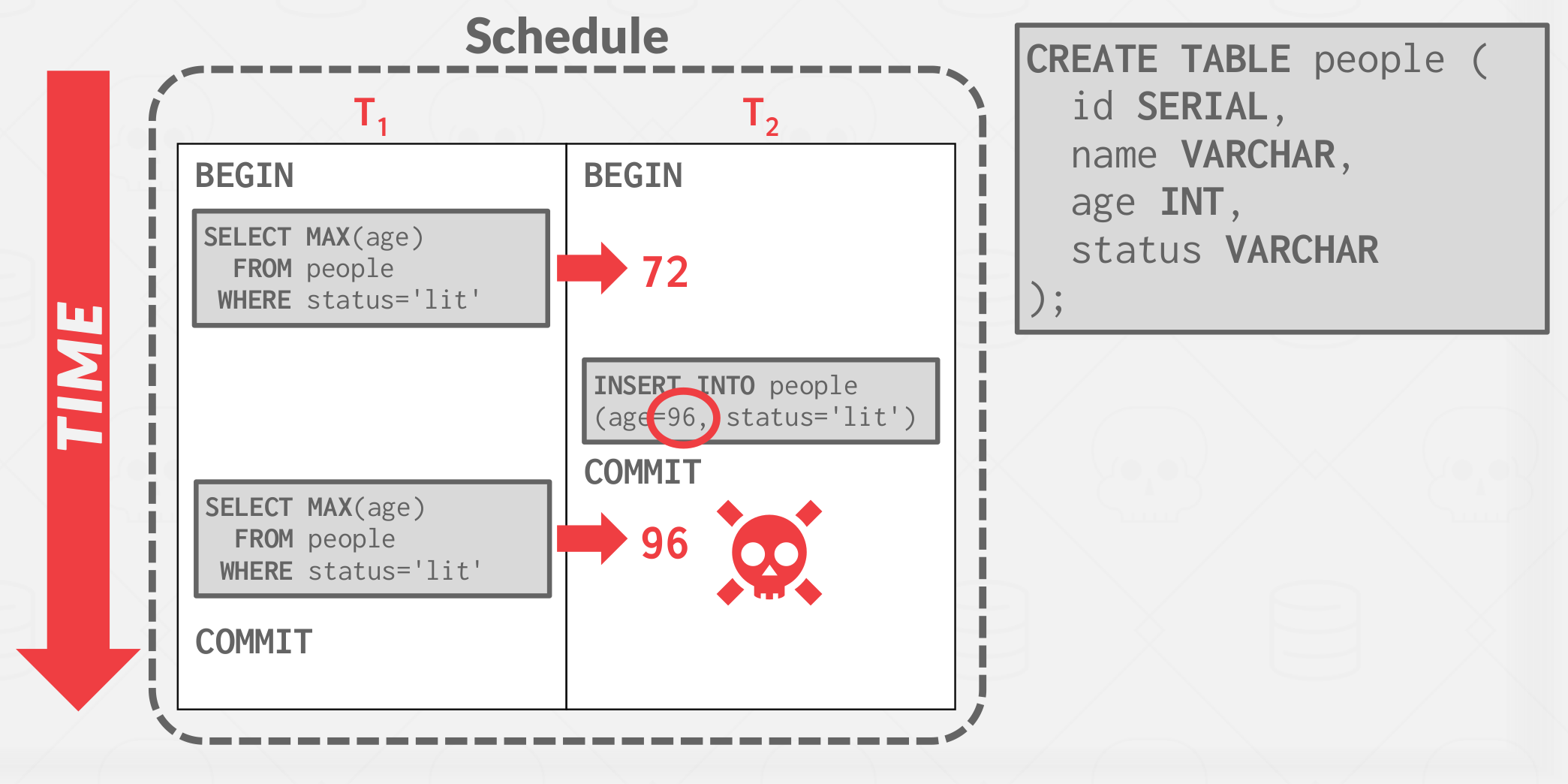 |
|---|
| Phantom problem |
The reason that why we have the phantom problem is because \( T_1 \) locked only existing records and not ones under way! The Conflict serializability on reads and writes of individual items guarantees serializability only if the set of objects is fixed.
There are three ways to address the Phantom problem
- Approach 1: Re-Execute Scans, Run queries again at commit to see whether they produce a different result to identify missed changes. The DBMS tracks the
WHEREclause for all queries that the transaction executes and retain the scan set for every range query in a transaction. Upon commit, it re-execute just the scan portion of each query and check whether it generates the same results. e.g., Run the scan for anUPDATEquery but do not modify matching tuples. Currently it is Not used/implemented by any DBMS. - Approach 2: Predicate Locking, Logically determine the overlap of predicates before
queries start running. This is a proposed locking scheme from System R. It acquire shared lock on the predicate in a
WHEREclause of aSELECTquery and exclusive lock on the predicate in aWHEREclause of anyUPDATE,INSERT, orDELETEquery. it is Never implemented in any system except for Hyper(precision locking)
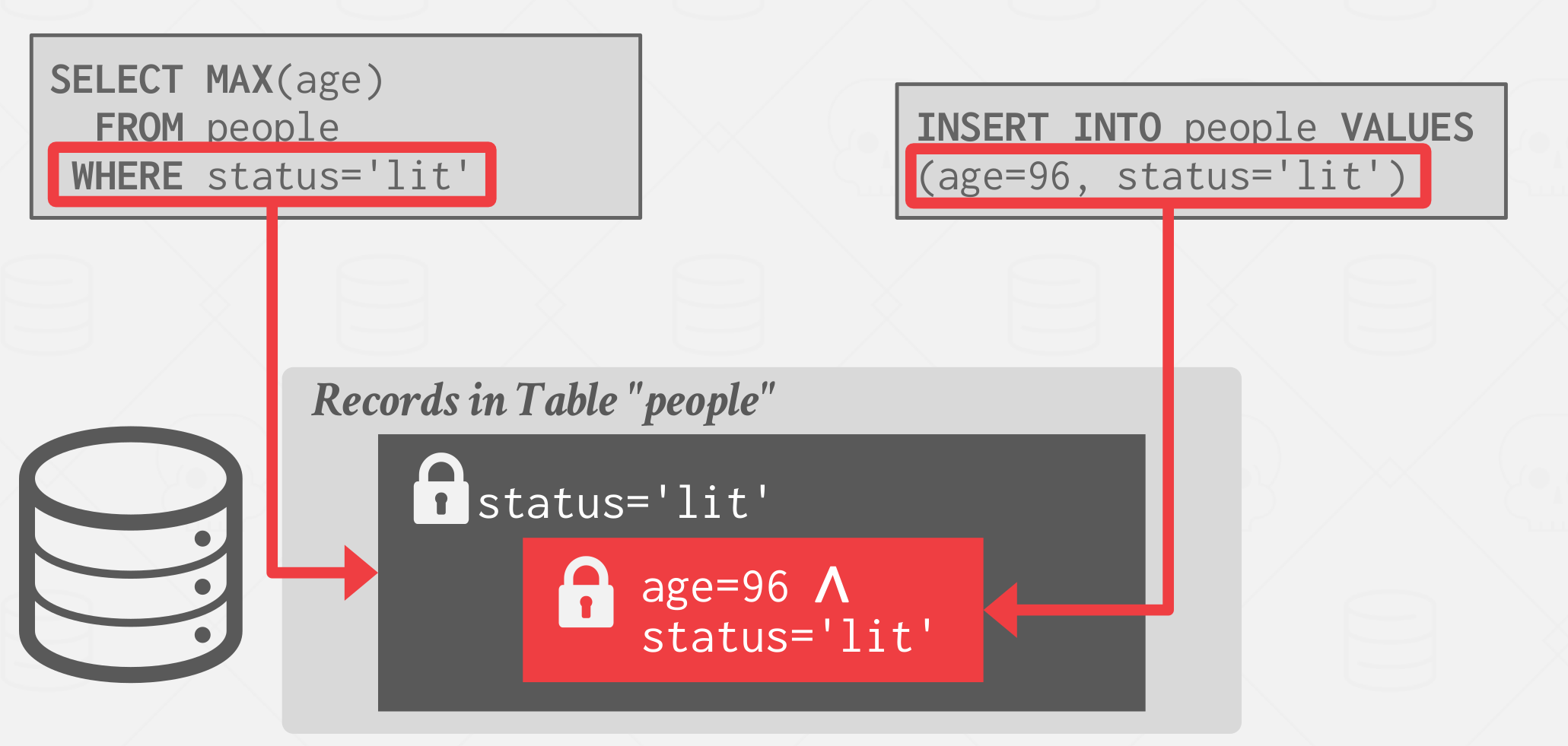 |
|---|
| Predicate Locking |
- Approach 3: Index Locking Schemes, Use keys in indexes to protect ranges. it consists four locking schema:
- Key-Value Locks
- Gap Locks
- Key-Range Locks
- Hierarchical Locking
Key-Value Locks
Locks that cover a single key-value in an index, Need/Uses “virtual keys” for non-existent values.
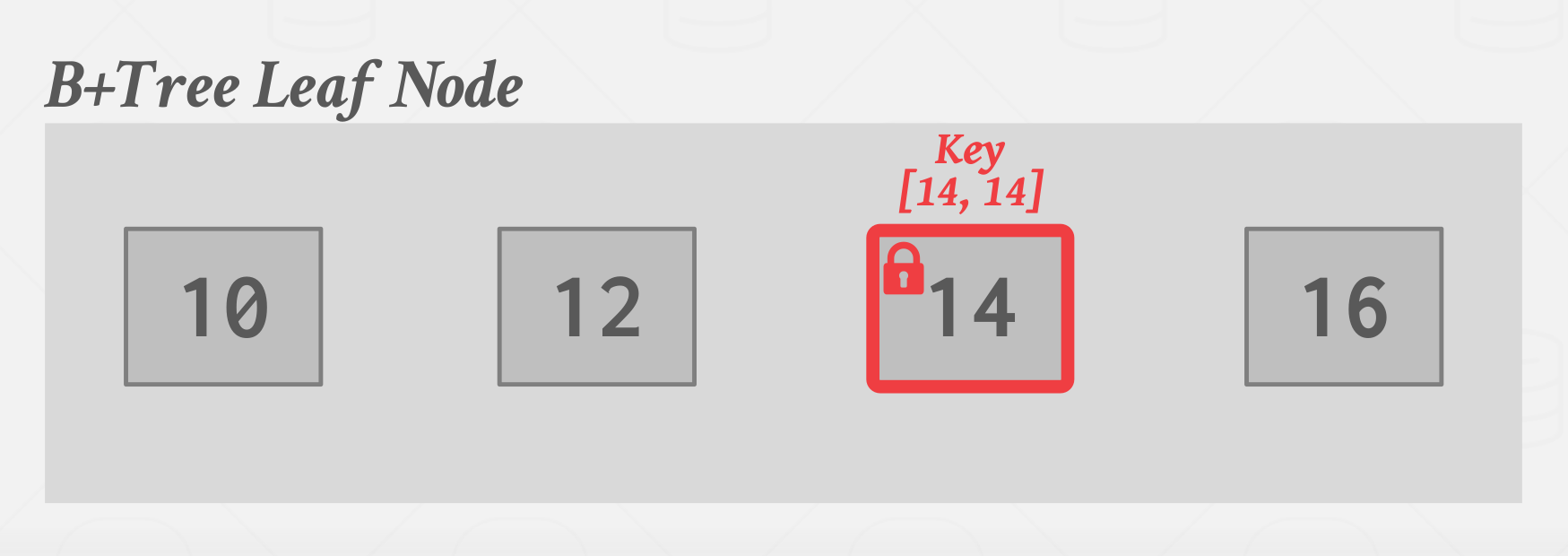 |
|---|
| Key-Value Locks |
In the above example, the basic idea is, the DBMS wouldn’t actually store the key 14 in the index itself, it stores it in the Lock Manager. it is sort of a logical comcept, the DBMS know how to got to the lock mangager and find the lock.
GAP Locks
Each transaction acquires a key-value lock on the single key that it wants to access. Then get a gap lock on the next key gap.
 |
|---|
| GAP Locks |
In the above example, the DBMS can prevent anybody from inserting or deleting right in the Gap(14, 16).
Key-Range Locks
A transaction take locks on ranges in the key space, a sort of combination of Key-value locks and Gap locks. it support take an actual key or multiple keys and multiple ranges at the same time in a single lock-acquire request.
- Each ranges if from one key that appears in the relation, to the next that appears.
- Define lock modes so conflict table will capture commutativity of the operation available.
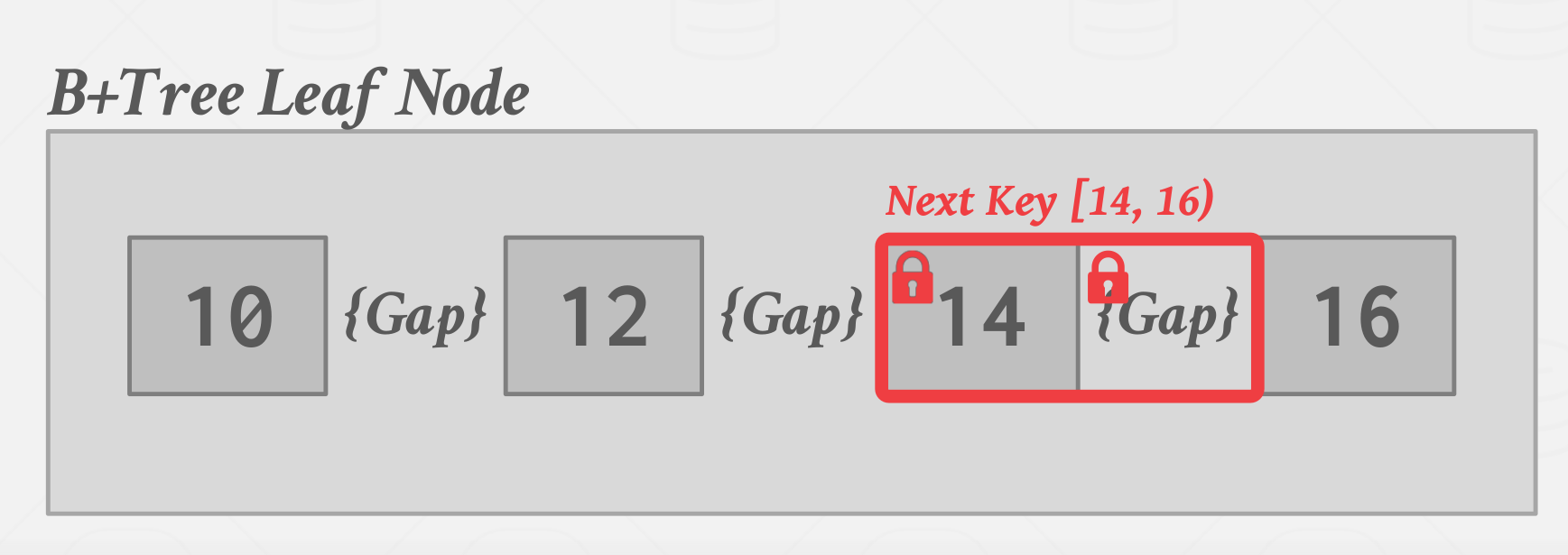 |
|---|
| Key-Range Locks, Next Key example [14, 16) |
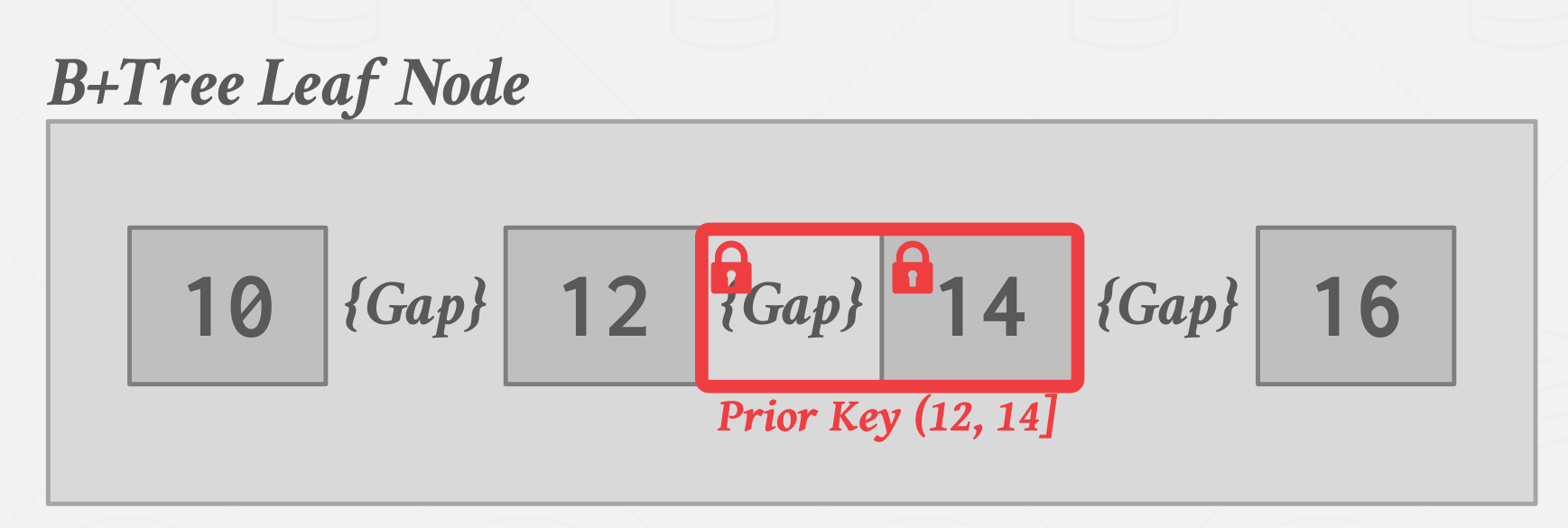 |
|---|
| Key-Range Locks, Prior Key example (12, 14) |
Note: Typically, you only take the locks in One Direction, either the Next-Key lock or the Prior-Key lock, to avoid deadlocks.
Hierarchical locking
The DBMS can combine all the above schems and apply the actually hierarchical locking technique that we talked about under 2PL where we can take intention locks on wider ranges and get more fine-grained locks that are are at a higher level as we go down. Allow for a txn to hold wider key-range locks with different locking modes.
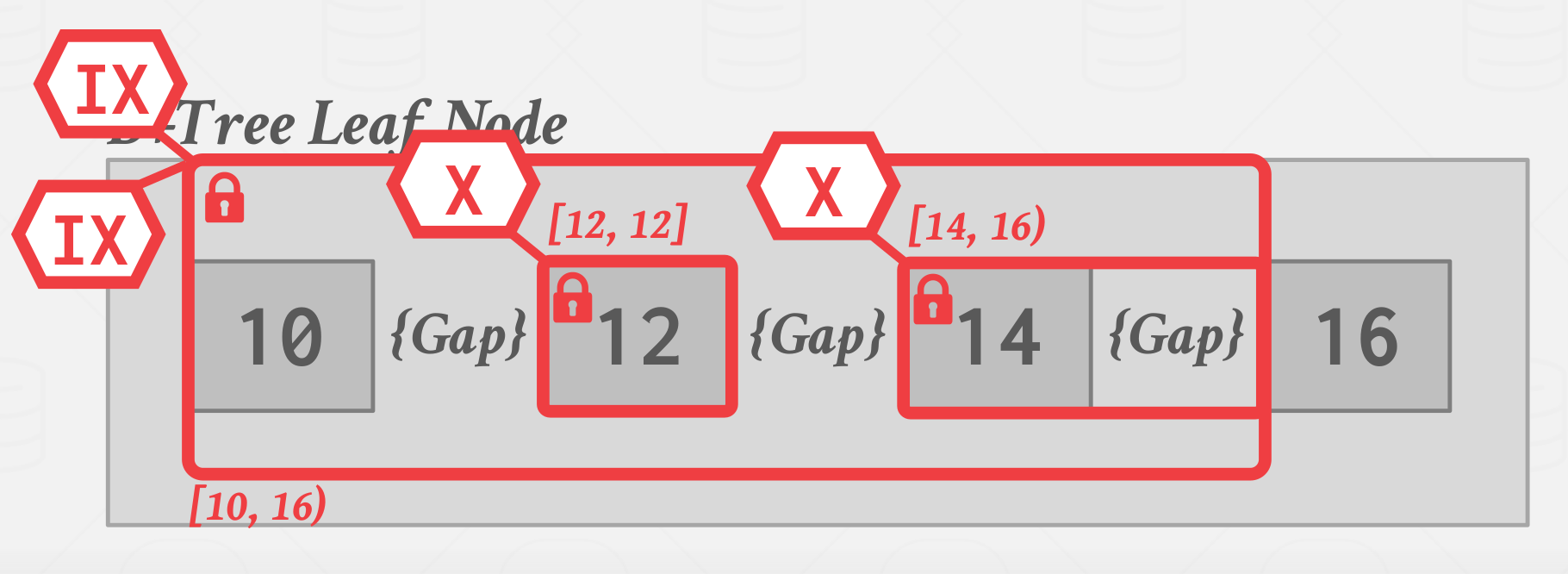 |
|---|
| Hierarchical locking |
6. Isolation Levels #
Serializability is useful because it allows programmes to ignore concurrency issues. but enforcing it may allow too little concurrency and limit performance. We may want to use a weaker level of consistency to improve scalability.
Isolation levels control the extent that a transaction is exposed to the actions of other concurrent trasactions.
A Weaker levels of isolation provides for greater concurrency at the cot of exposing transactions to potential anomalies:
- Dirty Read: Reading uncommitted data.
- Unrepeatable Reads: Redoing a read results in a different result.
- Phantom Reads: Insertion or deletions result in different results for the same range scan queries.
Isolation Levels(Stringest to Weakest)
SERIALIZABLE: No Phantoms, all reads repeatable, and no dirty reads.REPEATABLE READS: Phantoms may happen.READ-COMMITTED: Phantoms and unrepeatable reads may happen.READ-UNCOMMITTED: All anomalies may happen.
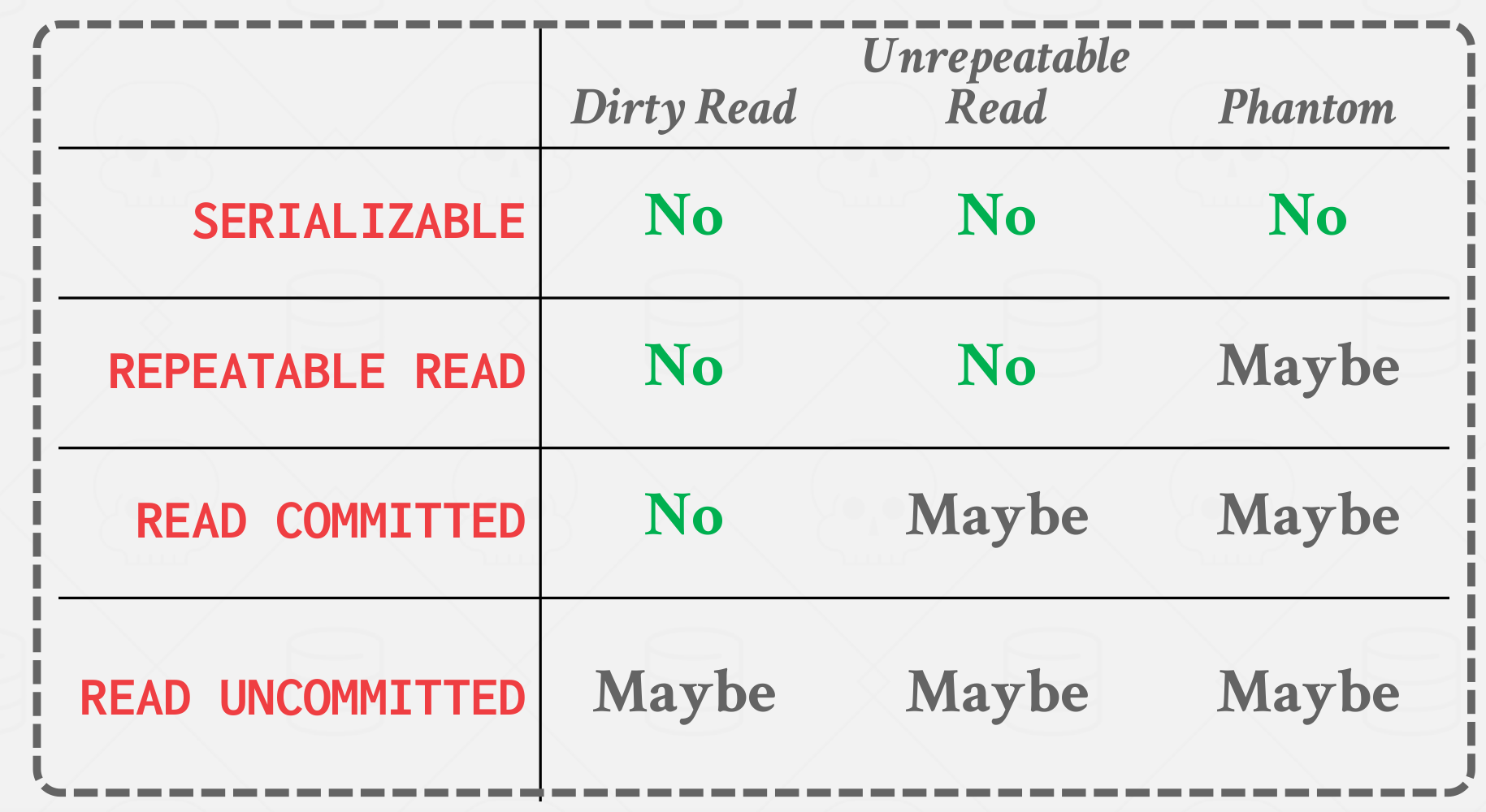 |
|---|
| Isolation Levels |
A intuition isolation levels implement strategy
SERIALIZABLE: Obtain all locks first; pluse index lock, plus strict 2PL.REPEATABLE READS: Same as above, but no index locks.READ-COMMITTED: Same as above, butSlocks are released immediately.READ-UNCOMMITTED: Same as above, but allows dirty reads(noSlocks).
SQL-92 isolation levels
The isolation levels defined as part of SQL-92 standard only focused on anomalies that can occur in a 2PL-based DBMS. There are two additional isolation levels:
-
CURSOR STABILITY- Between repeatable reads and read committed
- Prevents Lost Update Anomaly.
- Default isolation level in IBM DB2.
-
SNAPSHOT ISOLATION- Guarantees that all reads made in a transaction see a consistent snapshot of the database that existed at the time the transaction started.
- A transaction will commit only if its writes do not conflict with any concurrent updates made since that snapshot.
- Susceptible to write skew anomaly.
Not all DBMS support all isolation levels in all execution scenarios. the default depends on implementations…
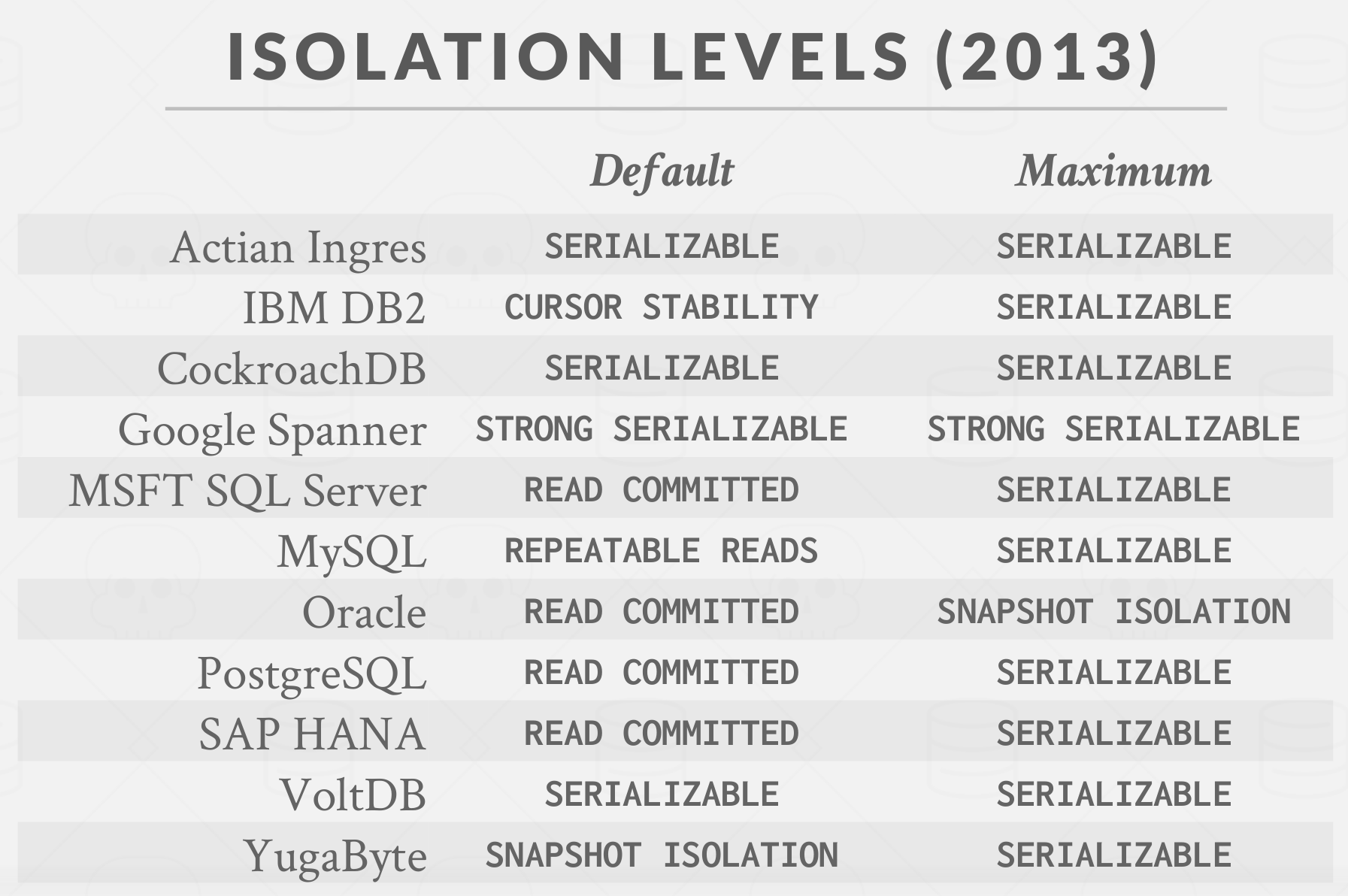 |
|---|
| Default Isolation Levels |
Database admin survey
What isolation level do transactions execute at on this DBMS?
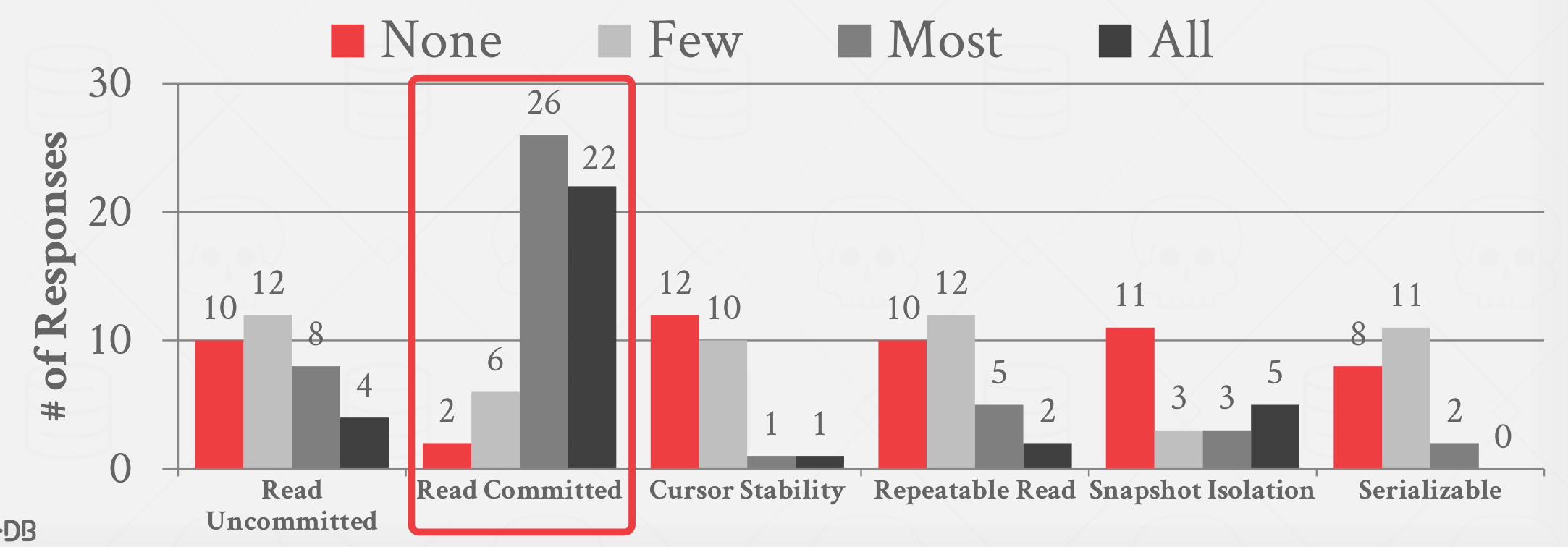 |
|---|
| Isolation Levels survey |
SQL-92 Access modes
You can provide hints to the DBMS about whether a txn will modify the database during its lifetime. There are only two possible modes:
READ WRITE(Default)READ ONLY
Not all DBMSs will optimize execution if you set a txn to in READ ONLY mode.