Database Storage Models #
A censorship circumvention tool may be required to open the links in this post from mainland of china.
Overview #
A DBMS’s storage model specifies how it physically organizes tuples on disk and in memory
Different DBMS workloads would benefit from different storage models.
- Choice #1: N-ary Storage Model (NSM)
- Choice #2: Decomposition Storage Model (DSM)
- Choice #3: Hybrid Storage Model (PAX)
Basically, What data “looks” like determins almost a DBMS’s entire system architecture like
- Processing Model
- Tuple Materialization Strategy
- Operator Algorithms
- Data Ingestion / Updates
- Concurrency Control
- Query Optimization
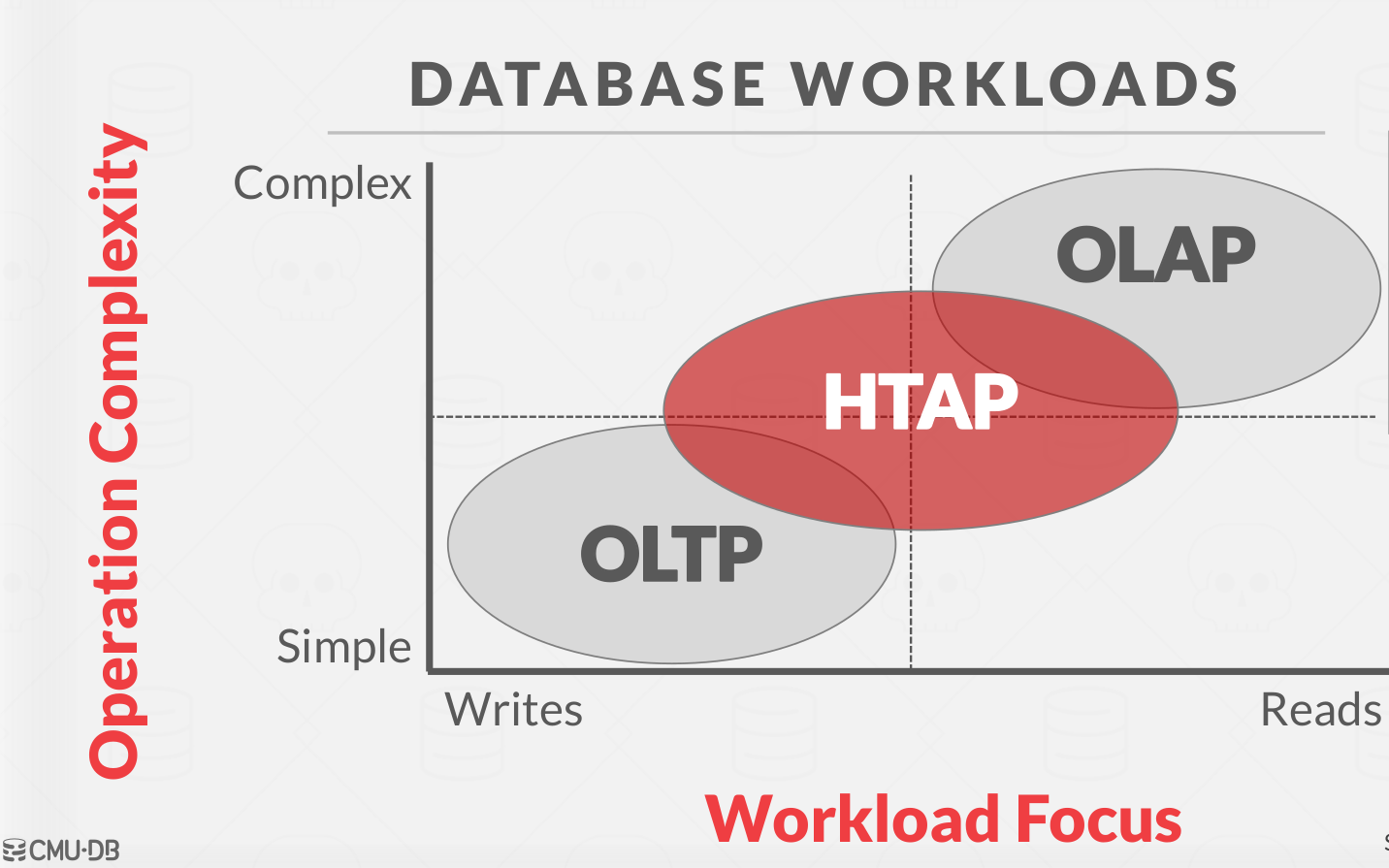
Database workloads #
 |
|---|
| Database workloads |
OLTP: Online Transaction Processing
An OLTP workload is characterized by fast, short running operations, simple queries that operate on single entity at a time, and repetitive operations. An OLTP workload will typically handle more writes than reads.
An example of an OLTP workload is the Amazon storefront. Users can add things to their cart, they can make purchases, but the actions only affect their account.
OLAP: Online Analytical Processing
An OLAP workload is characterized by long running, complex queries, reads on large portions of the database. In OLAP worklaods, the database system is analyzing and deriving new data from existing data collected on the OLTP side.
An example of an OLAP workload would be Amazon computing the most bought item in Pittsburgh on a day when its raining.
HTAP: Hybird Transaction + Analytical Processing
A new type of workload which has become popular recently is HTAP, which is like a combination which tries to do OLTP and OLAP together on the same database.
1. N-ary storage model(NSM, a.k.a, row storage) #
In the n-ary storage model, the DBMS stores all of the attributes for a single tuple contiguously in a single page. This approach is ideal for OLTP workloads where requests are insert-heavy and transactions tend to operate only an individual entity. It is ideal because it takes only one fetch to be able to get all of the attributes for a single tuple.
NSM database page sizes are typically some constant multiple of 4 KB hardware pages. For Example: Oracle (4 KB), Postgres (8 KB), MySQL (16 KB)
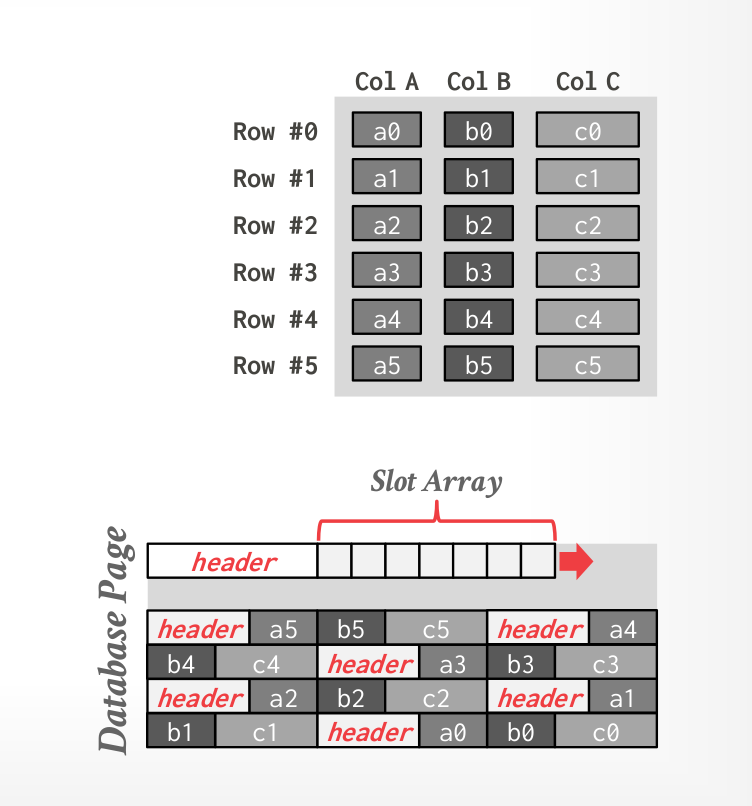
Physical oganization
 |
|---|
| NSM physical organization |
A disk-oriented NSM system stores a tuple’s fixed-length and variable-length attributes contiguously in a single slotted page(user overflow page for large variable-length attributes).
The tuple’s record id (page#, slot#) is how the DBMS uniquely identifies a physical tuple.
Advantages
- Fast inserts, updates, and deletes.
- Good for queries that need the entire tuple (OLTP).
- Can use index-oriented physical storage for clustering.
Disadvantages
- Not good for scanning large portions of the table and/or a subset of the attributes.
- Terrible memory locality in access patterns.
- Not ideal for compression because of multiple value domains within a single page.
Example: SELECT SUM(colA), AVG(colC) FROM xxx WHERE colA > 1000
2. Decompositioin storage model(DSM, a.k.a, columnar storage) #
In the decomposition storage model, the DBMS stores a single attribute (column) for all tuples contiguously in a block of data. Thus, it is also known as a “column store.” This model is ideal for OLAP workloads with many read-only queries that perform large scans over a subset of the table’s attributes.
File sizes are larger(100s of MBs), but it may still organize tuples within the file into smaller groups.
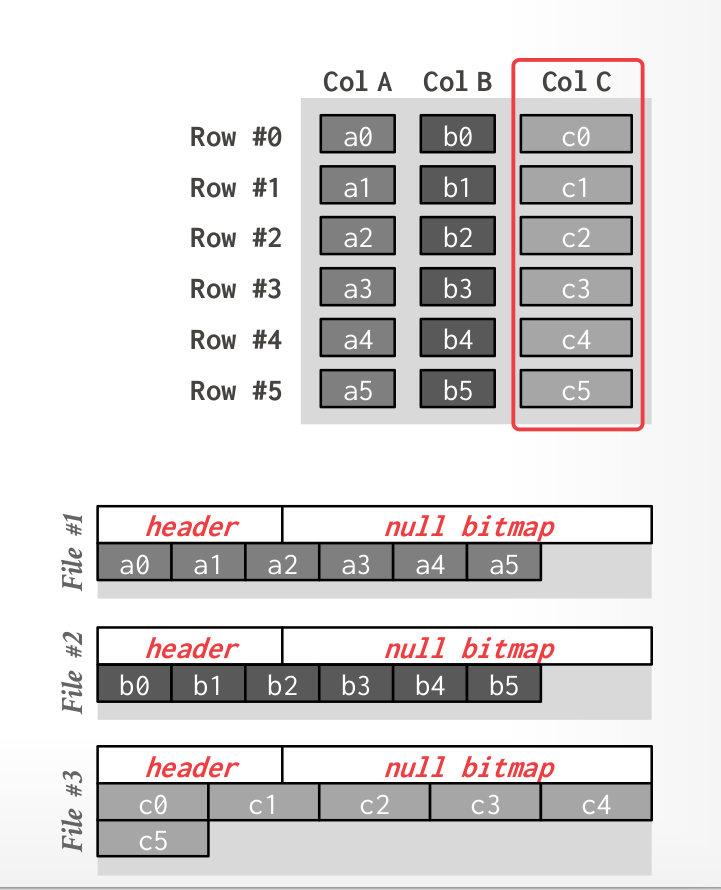
Physical oganization
 |
|---|
| DSM physical organization |
Store attributes and meta-data (e.g.,nulls) in separate arrays of fixed-length values.
- Most systems identify unique physical tuples using offsets into these arrays.
- Need to handle variable-length values…
Maintain a separate file per attribute with a dedicated header area for meta-data about entire column.
Tuple identification
- Choice #1: Fixed-length Offsets: Each value is the same length for an attribute – Everyone use this one.
- Choice #2: Embedded Tuple Ids: Each value is stored with its tuple id in a column – Nobody implement it this way so far, because of the huge storage overhead of maintaining the embedded ids and the index.
|
|---|
| DSN tuple identification |
Regarding the variable-length values for Choice/approach #1, Padding variable-length fields to ensure they are fixed-length is wasteful, especially for large attributes. A better approach is to use dictionary compression to convert repetitive variable-length data into fixed-length values (typically 32-bit integers).
Advantages
- Reduces the amount wasted I/O per query because the DBMS only reads the data that it needs.
- Faster query processing because of increased locality and cached data reuse.
- Better data compression
Disadvantages
- Slow for point queries, inserts, updates, and deletes because of tuple splitting/stitching/reorganization.
3. PAX storage model(A de-facto columnar storage) #
OLAP queries almost never access a single column in a table by itself. At some point during query execution, the DBMS must get other columns and stich the original tuple back togther. But we still need to store data in a columnar format to get storage + execution benefits.
We need columnar scheme that still stores attributes separately but keeps the data for each tuple physically close to each other…
So this is where the Partition Attributes Across(PAX) comes in to play.
PAX is a hybrid storage model that vertically partitions attributes within a database page, e.g., this is what Parqquet and Orc use.
The goal of PAX is to get the benefit of faster processing on columnar storage while retaining the spatial locality benefits of row storage.
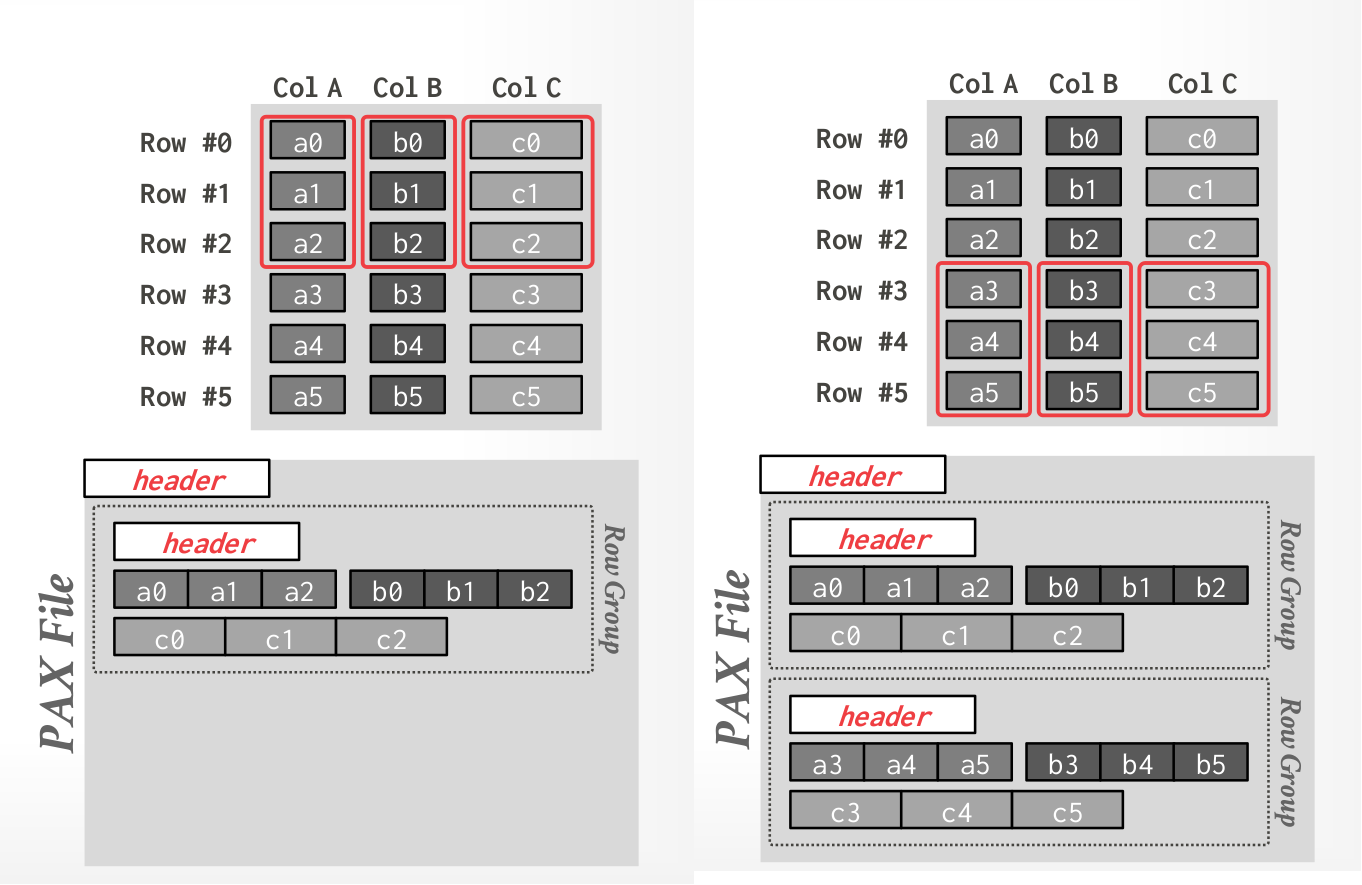
Physical oganization
 |
|---|
| PAX physical organization |
Horizontally partition rows into groups. Then vertically partition their attributes into columns.
Global header contains directory with the offsets to the file’s row groups. This is stored in the footer if the file is immutable (Parquet, Orc).
Each row group contains its own meta-data header about its contents.
Here is a example for the Parquet file
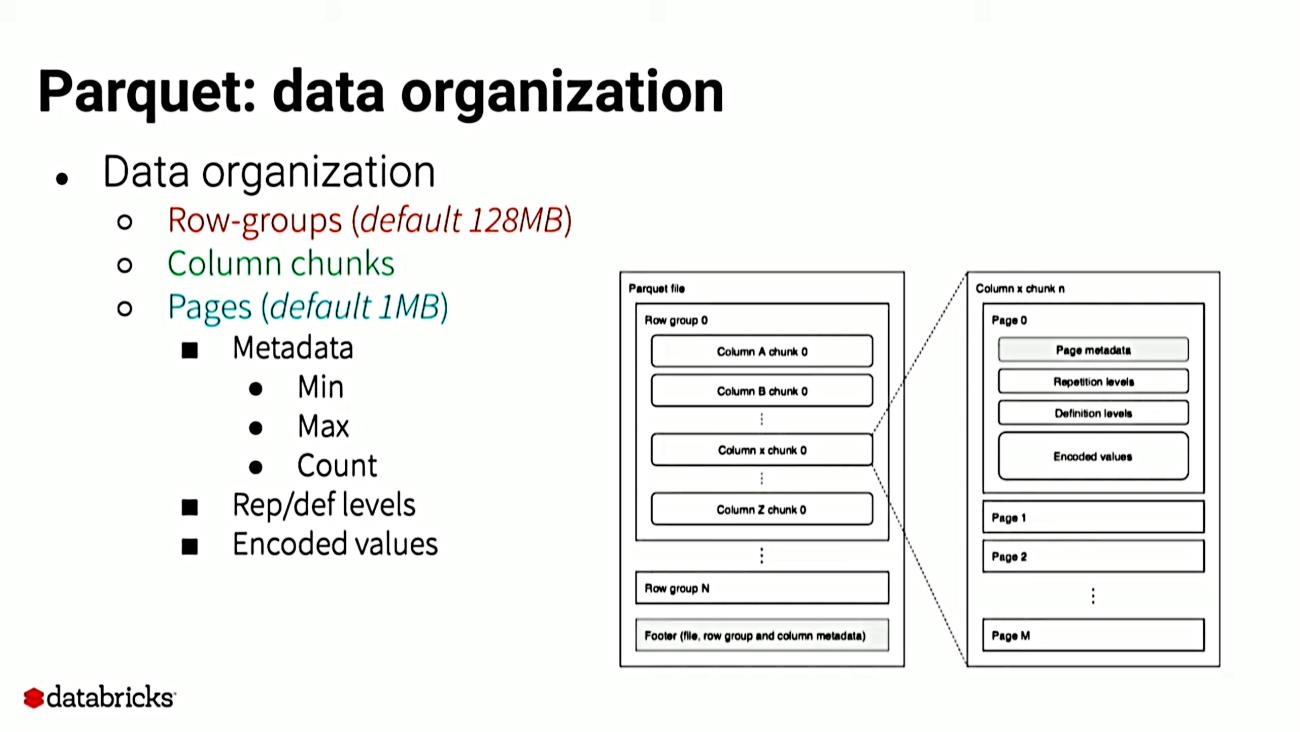 |
|---|
| An example file for parquet |
4. Transparent Huge Pages(THP) #
An OLAP DBMS uses the buffer pool manager methods that we discussed in the intro course.OS maps physical pages to virtual memory pages. The CPU’s MMU maintains a TLB that contains the physical address of a virtual memory page.
- The TLB resides in the CPU caches.
- It cannot obviously store every possible entry for a largememory machine.
When you allocate a block of memory, the allocator keeps that it aligned to page boundaries.
Instead of always allocating memory in 4 KB pages, Linux supports creating larger pages (2MB to 1GB)
- Each page must be a contiguous blocks of memory.
- Greatly reduces the # of TLB entries
With THP, the OS reorganizes pages in the background to keep things compact(Source: Alexandr Nikitin).
- Split larger pages into smaller pages.
- Combine smaller pages into larger pages.
- Can cause the DBMS process to stall on memory access.
Historically, every DBMS advises you to disable this THP on Linux(Source: Evan Jones):
- Oracle, SingleStore, NuoDB, MongoDB, Sybase, TiDB.
- Vertica says to enable THP only for newer Linux distros.
Recent research from Google suggests that huge pages improved their data center workload by 7%, 6.5% improvement in Spanner’s throughput(huge page is a good idea)
5. Hybrid Storage Model #
Use separate execution engines that are optimized for either NSM or DSM databases.
- Store new data in NSM for fast OLTP.
- Migrate data to DSM for more efficient OLAP.
- Combine query results from both engines to appear as a single logical database to the application.
Choice #1: Fractured Mirrors, Examples: Oracle, IBM DB2 Blu, Microsoft SQL Server
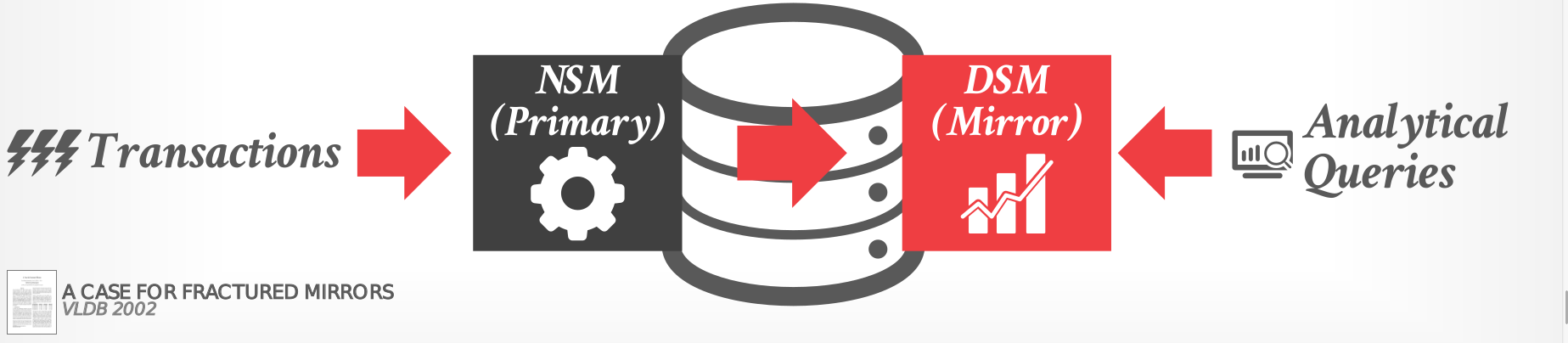 |
|---|
| Fractured mirrors |
Store a second copy of the database in a DSM layout that is automatically updated.
- All updates are first entered in NSM then eventually copied into DSM mirror.
- If the DBMS supports updates, it must invalidate tuples in the DSM mirror.
Check here for a Fractured Mirrors use case.
Choice #2: Delta Store, Examples: SAP HANA, Vertica, SingleStore, Databricks, Google Napa
 |
|---|
| Delta Store |
Stage updates to the database in an NSM table.
A background thread migrates updates from delta store and applies them to DSM data. e.g., Batch large chunks and then write them out as a PAX file.
6. Database Partitioning #
Split database across multiple resources:
- Disks, nodes, processors.
- Often called “sharding” in NoSQL systems.
The DBMS executes query fragments on each partition and then combines the results to produce a single answer.
The DBMS can partition a database physically (shared nothing) or logically (shared disk).
Horizontal Partitioning
Split a table’s tuples into disjoint subsets based on some partitioning key and scheme. e.g., Choose column(s) that divides the database equally in terms of size, load, or usage.
Partitioning Schemes:
- Hashing
- Ranges
- Predicates
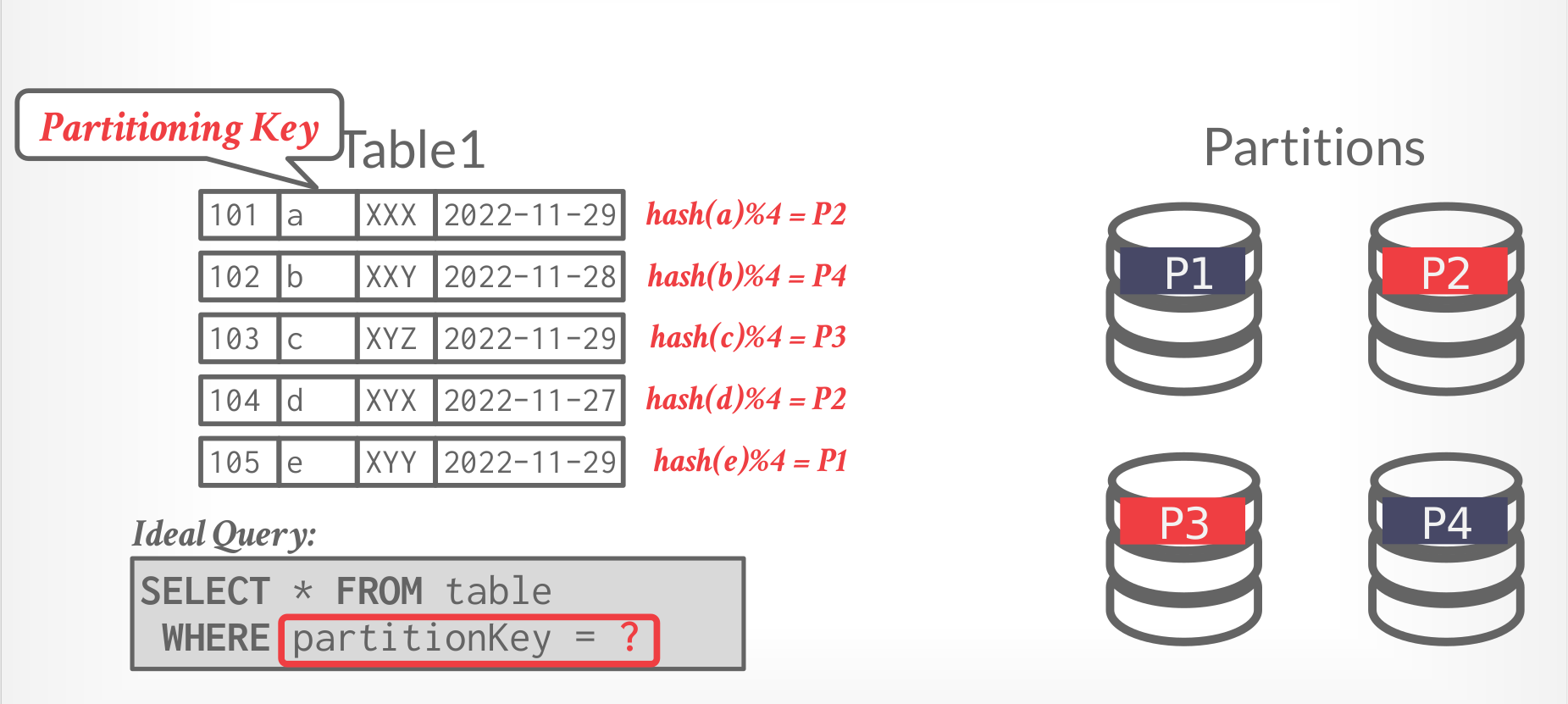 |
|---|
| Horizontal Partitioning |
Logical Partitioning
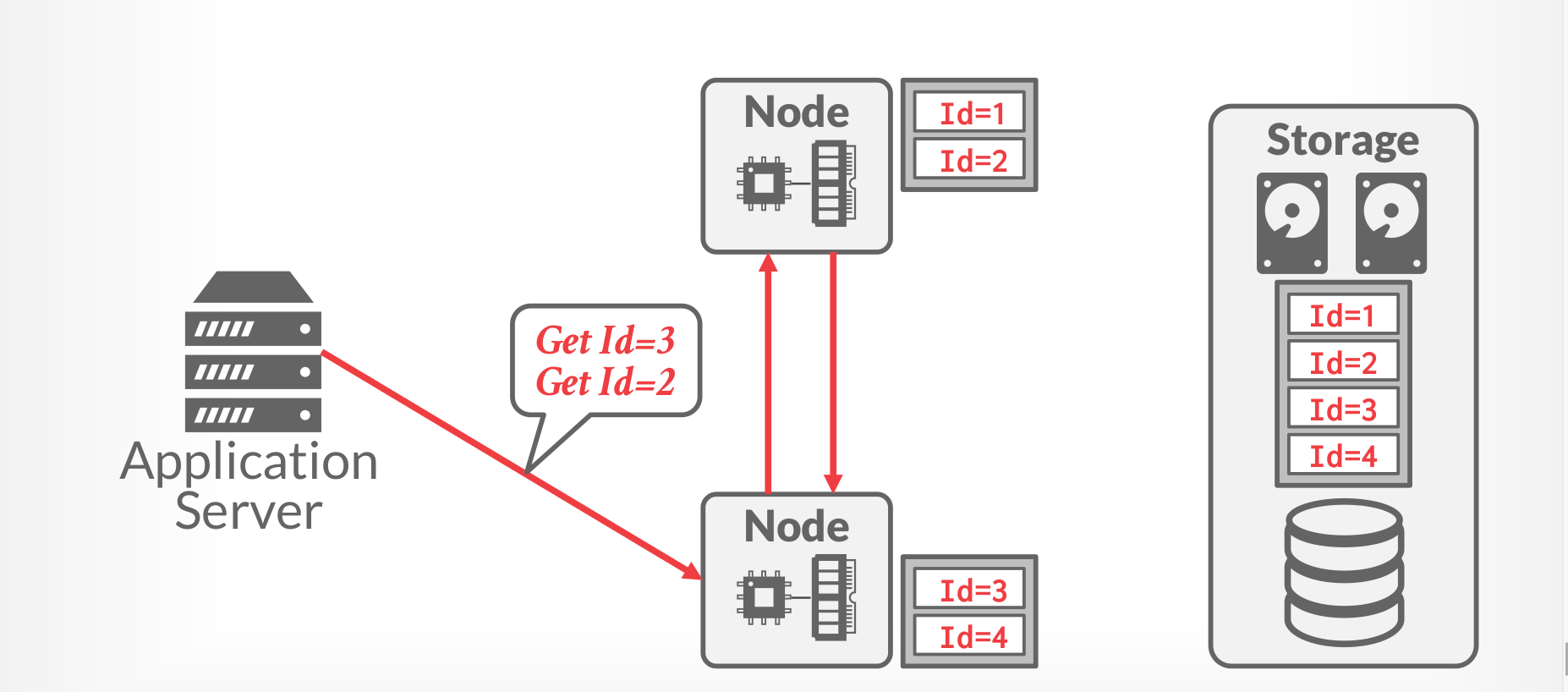 |
|---|
| Locical Partitioning |
Common approaches
- Push query to data
- Pull data to query
Physical Partitioning
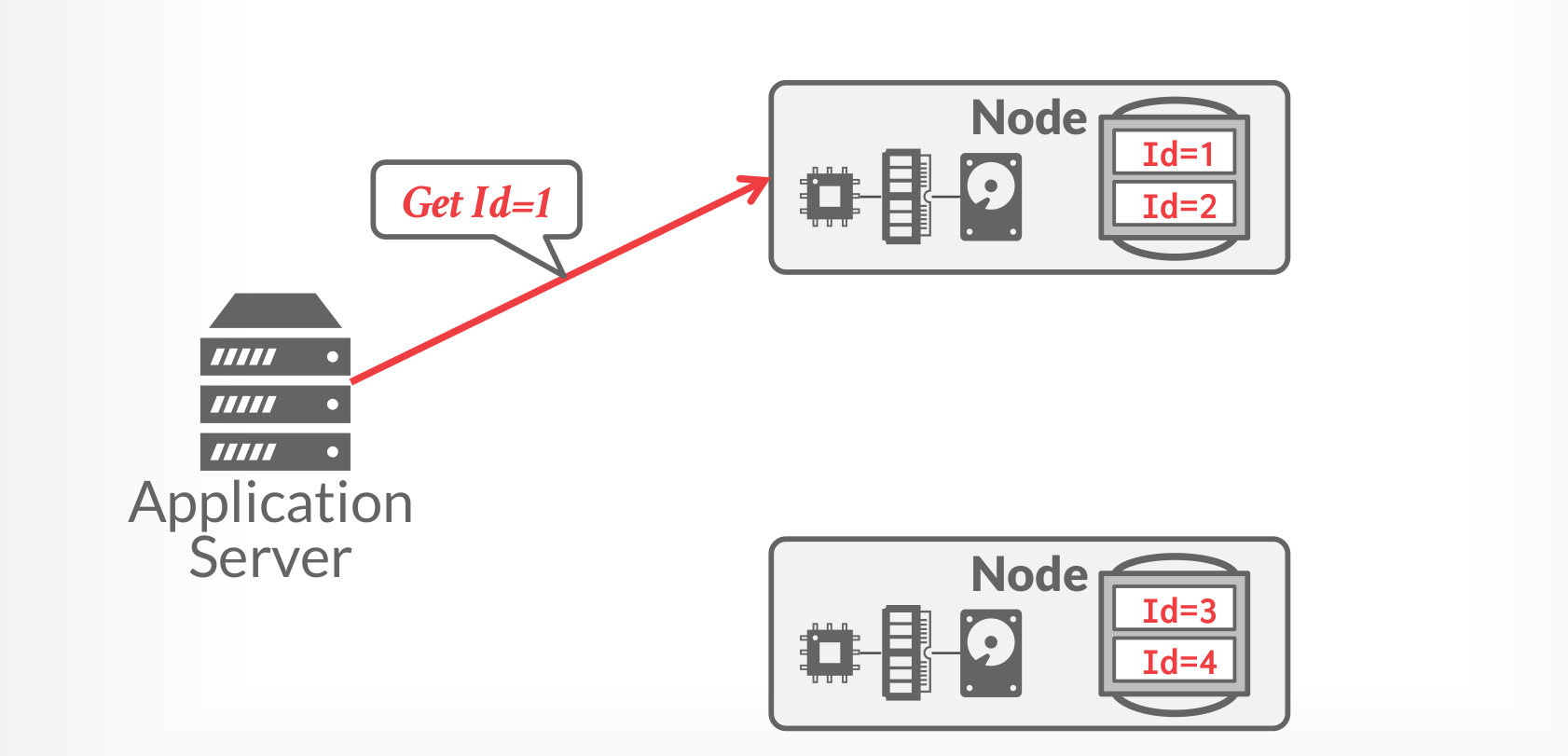 |
|---|
| Physical Partitioning |
7. Reference #
- https://www.youtube.com/watch?v=q4W5r3GR0OU&list=PLSE8ODhjZXjaKScG3l0nuOiDTTqpfnWFf&index=5
- https://15445.courses.cs.cmu.edu/fall2022/slides/05-storage3.pdf
- https://15445.courses.cs.cmu.edu/fall2022/notes/05-storage3.pdf
- https://www.youtube.com/watch?v=oWaeWlvPCyk&list=PLSE8ODhjZXjYzlLMbX3cR0sxWnRM7CLFn&index=3
- https://15721.courses.cs.cmu.edu/spring2023/slides/03-storage.pdf