Database Storage Part 2 #
A censorship circumvention tool may be required to open the links in this post from mainland of china.
Overview #
The DBMS assumes that the primary storage location of the database is on non-volatile disk and the DBMS’s components manage the momvent of data between non-volatile and volatile storage.
The Disk manager(a.k.a Storage manager) is responsible for how we actually represent a database on disk, what it means to get a page from disk, what’s inside of it, and so forth, these will affect how we architect the rest of the system.
We discussed the Slotted-Page as the page layout architecture in Part 1) and leaving the Log-structured page layout for this Part 2.
1. Slotted-Page Design #
Insert a new tuple:
- Check page directory to find a page with a free slot.
- Retrive the page from disk(if not in memory)
- Check slot array to find empty space in page that will fit.
Update an existing tuple using its record id:
- Check page directory to find location page.
- Retrive the page from disk(if not in memory)
- Find offset in page using slot array
- Overwrite existing data(if new data fits)
Some problems associated with the Slotted-Page Design are:
- Fregmentation: Deletion of tuples can leave gaps in the pages.
- Useless Disk I/O: Due to the block-oriented nature of non-volatile storage, the whole block needs to be read to fetch a tuple.
- Random Disk I/O: E.g., Update 20 tuples on 20 pages
What if we were working on a system which only allows creation of new data and no overwrites, e.g., Cloud storage(S3), HDFS? The log-structured storage model works with this assumption and addresses some of the problems listed above.
2. Log-structured storage #
- Stores records to file of how the database was modified (put and delete). Each log record contains the tuple’s unique identifier.
- To read a record, the DBMS scans the log file backwards from newest to oldest and “recreates” the tuple.
- Fast writes, potentially slow reads. Disk writes are sequential and existing pages are immutable which leads to reduced random disk I/O.
- Works well on append-only storage because the DBMS cannot go back and update the data.
- To avoid long reads, the DBMS can have indexes to allow it to jump to specific locations in the log. It can also periodically compact the log. (If it had a tuple and then made an update to it, it could compact it down to just inserting the updated tuple.)
- The database can compact the log into a table sorted by the id since the temporal information is not needed anymore. These are called Sorted String Tables (SSTables) and they can make the tuple search very fast.
- The issue with compaction is that the DBMS ends up with write amplification. (It re-writes the same data over and over again.)
Instead of storing tuples, the DBMS only stores log records that contains changes to tuples(PUT, DELETE)
- Each log record must contain the tuple’s unique identifier.
- Put records contain the tuple contents.
- Deletes mark the tuple as deleted.
 |
|---|
| Append log record(PUT, DELETE) |
When the page gets full, the DBMS writes it out disk and starts filling up the next page with records
- All disk writes are sequential
- On-disk pages are immutable
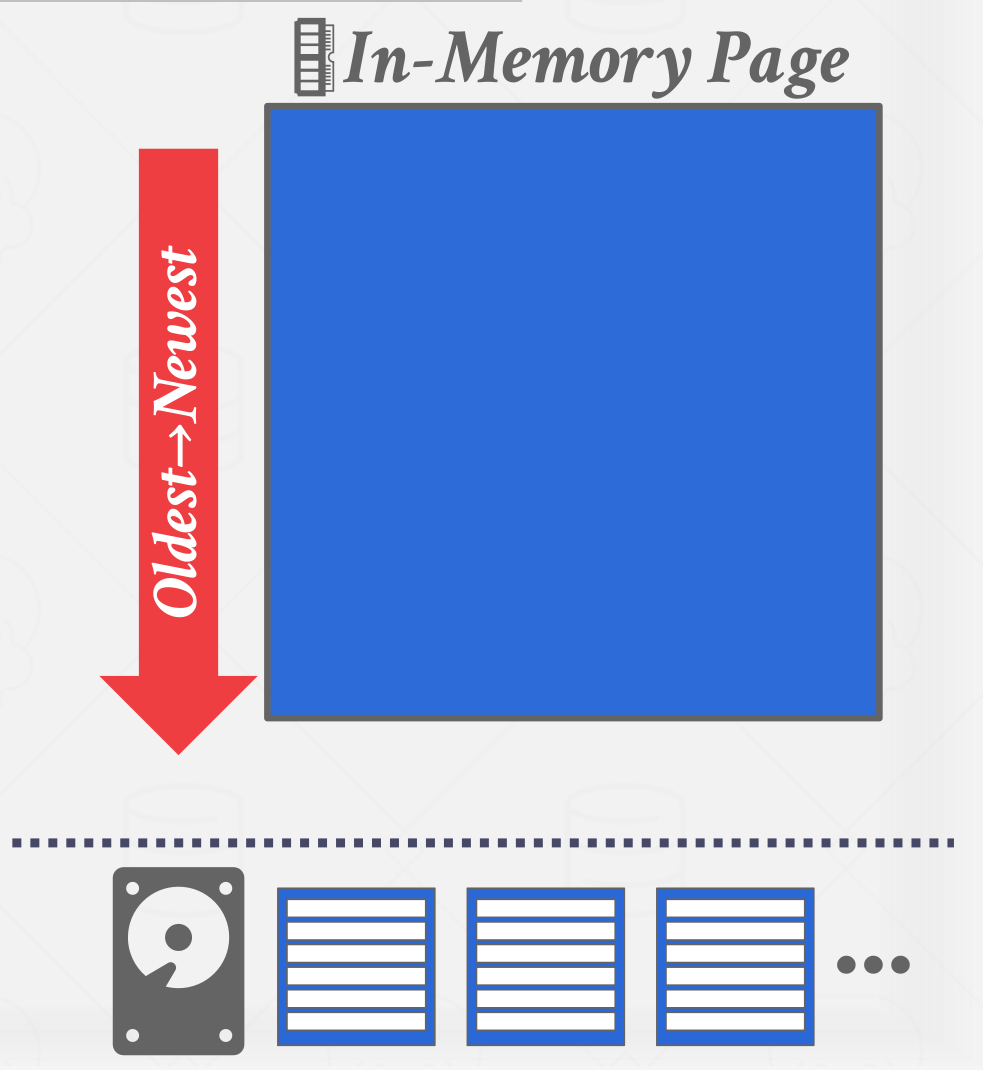 |
|---|
| When the page gets full, the DBMS writes it out disk |
To read a tuple with a given id, the DBMS finds the newest log record coresponding to that id.
- Scan log from newest to oldest
- Maybe maintain an index that maps a tuple id to the newest log record
- If log record is in-memory, just read it.
- If log record is on a disk page, retrive it.
 |
|---|
| Read a tuple with a given id |
3. Log-structured compaction #
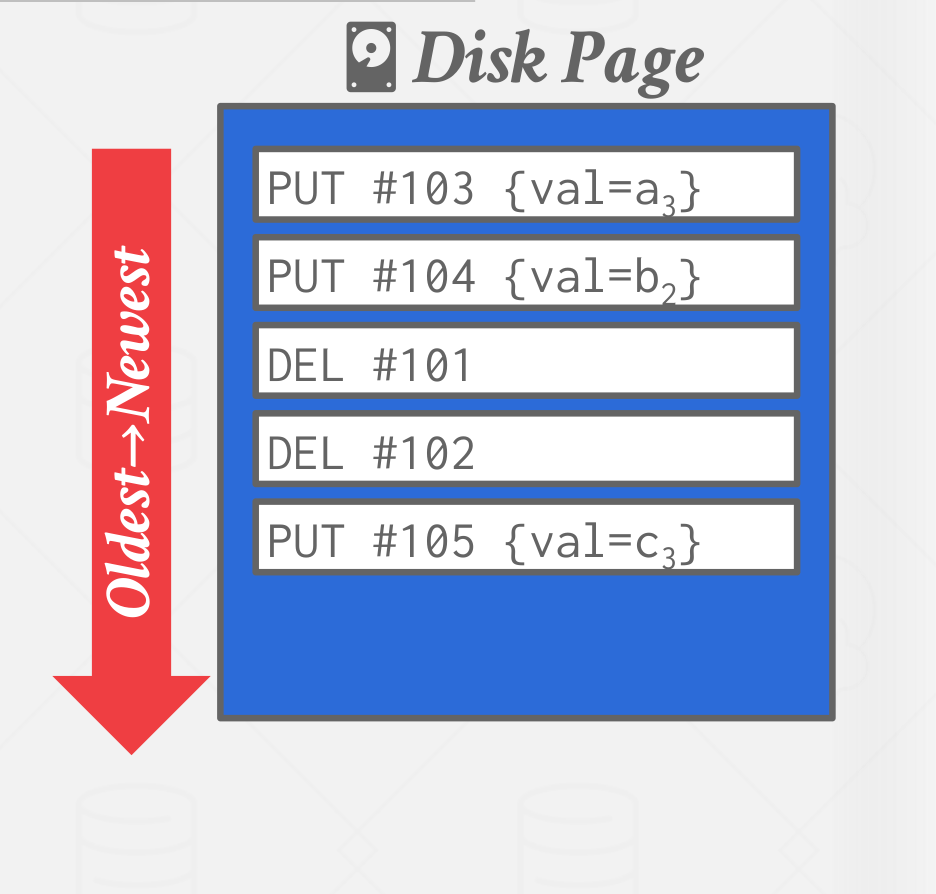
The log will grow forever. The DBMS needs to periodically compact pages to reduce wasted space.
 |
|---|
| Log compaction |
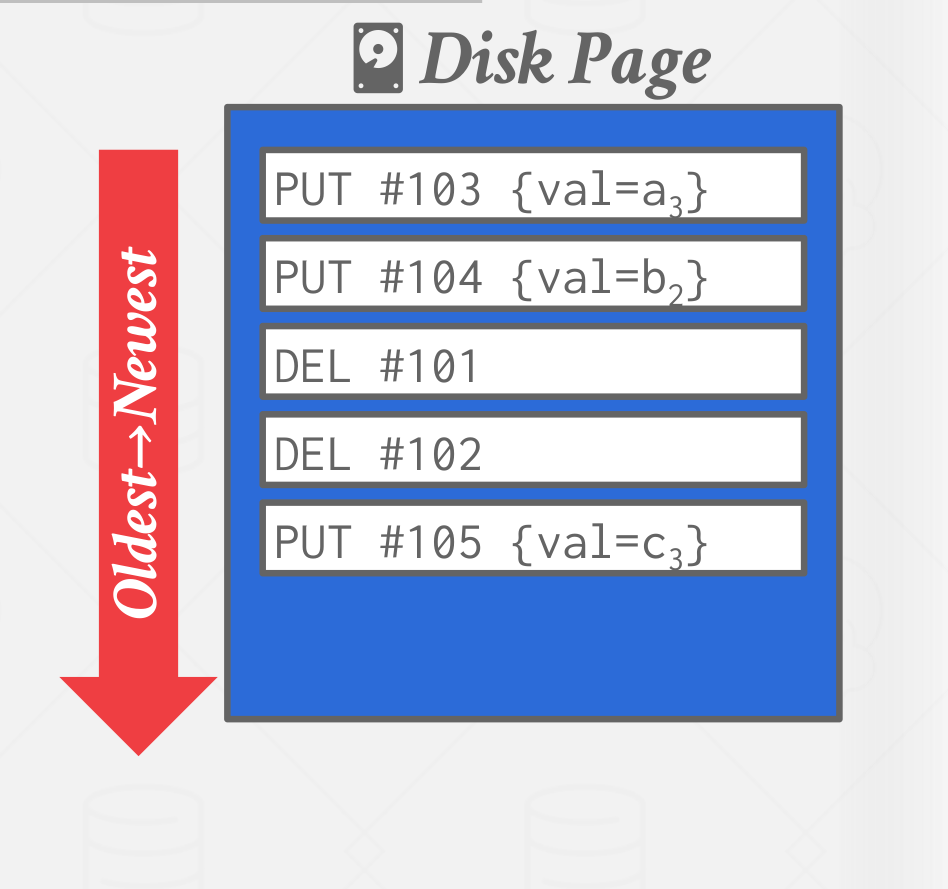
After a page is compacted, the DBMS does need to maintain temporal ordering of records within the page, Each tuple id is guaranteed to appear at most oncein the page.
 |
|---|
| Compacted page |
The DBMS can instead sort the page based on id order to improveefficiency of future look-ups.Called Sorted String Tables (SSTables)
 |
|---|
| Sorted String Tables (SSTables) |
Compaction coalesces larger log files into smaller files by removing unnecessary records.
Two common approachs for compaction are Universal Compaction and Level Compaction
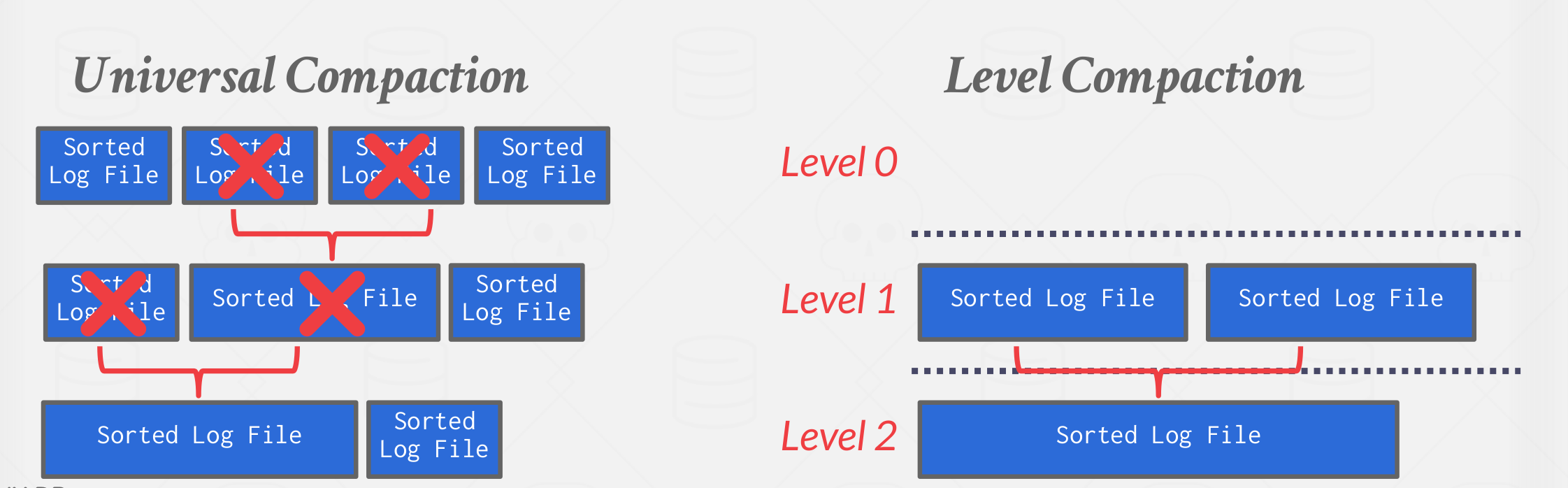 |
|---|
| Universal & level Compaction |
Downsides of this approach
- Write amplification(It re-writes the same data over and over again)
- Compaction is Expensive(It requires quite a lot of engineering efforts to tune for performance).
- Although it fast writes, potentially slow reads