Database Storage Part 1 #
A censorship circumvention tool may be required to open the links in this post from mainland of china.
Overview #
In general the database management system is build by different layers
 |
|---|
| DBMS layers |
The Disk manager(a.k.a Storage manager) is responsible for how we actually represent a database on disk, what it means to get a page from disk, what’s inside of it, and so forth, these will affect how we architect the rest of the system. one key idea for the DBMS is that disk-based or disk-oriented database system, and this basically means that the software is going to be designed to assume that the primary storage location of the database is on some kind of non-volatile storage/disk and the components of the DBMS built to allow us to manage the movement of data back and forth from the non-volatile disk and the volatile storage(the memory). this is a classic non-volatile architecture where we have the data at rest setting on disk, anytime you want to manipulate it or do something with it, we have to bring it to the memory so the CPU can crunch on it.
1. Storage #
The DBMS assumes that the primary storage location of the database is on non-volatile disk(s).
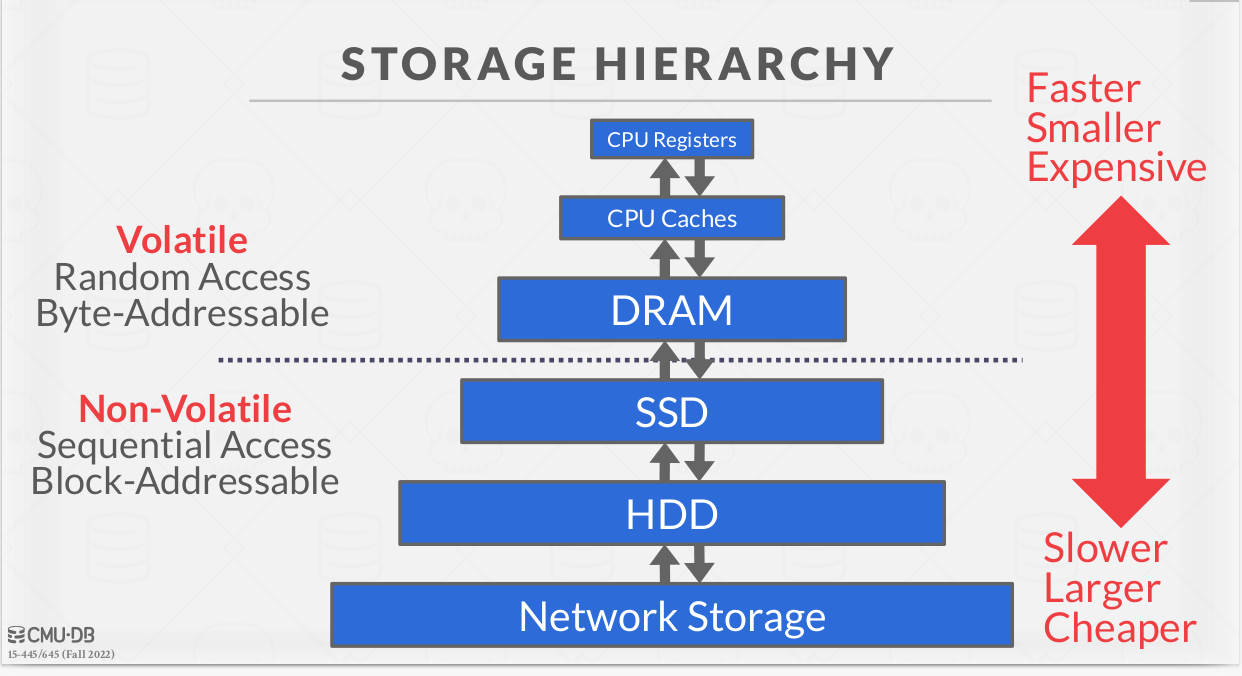 |
|---|
| Storage Hierarchy |
At the top of the storage hierarchy, you have the devices that are closest to the CPU. This is the fastest storage, but it is also the smallest and most expensive. The further you get away from the CPU, the larger but slower the storage devices get. These devices also get cheaper per GB.
Volatile Devices:
- Volatile means that if you pull the power from the machine, then the data is lost.
- Volatile storage supports fast random access with byte-addressable locations. This means that the program can jump to any byte address and get the data that is there.
- For our purposes, we will always refer to this storage class as “memory.”
Non-Volatile Devices:
- Non-volatile means that the storage device does not require continuous power in order for the device to retain the bits that it is storing.
- It is also block/page addressable. This means that in order to read a value at a particular offset, the program first has to load the page, e.g., 4KB, into memory that holds the value the program wants to read.
- Non-volatile storage is traditionally better at sequential access (reading multiple contiguous chunks of data at the same time).
- We will refer to this as “disk.” We will not make a (major) distinction between solid-state storage (SSD) and spinning hard drives (HDD).
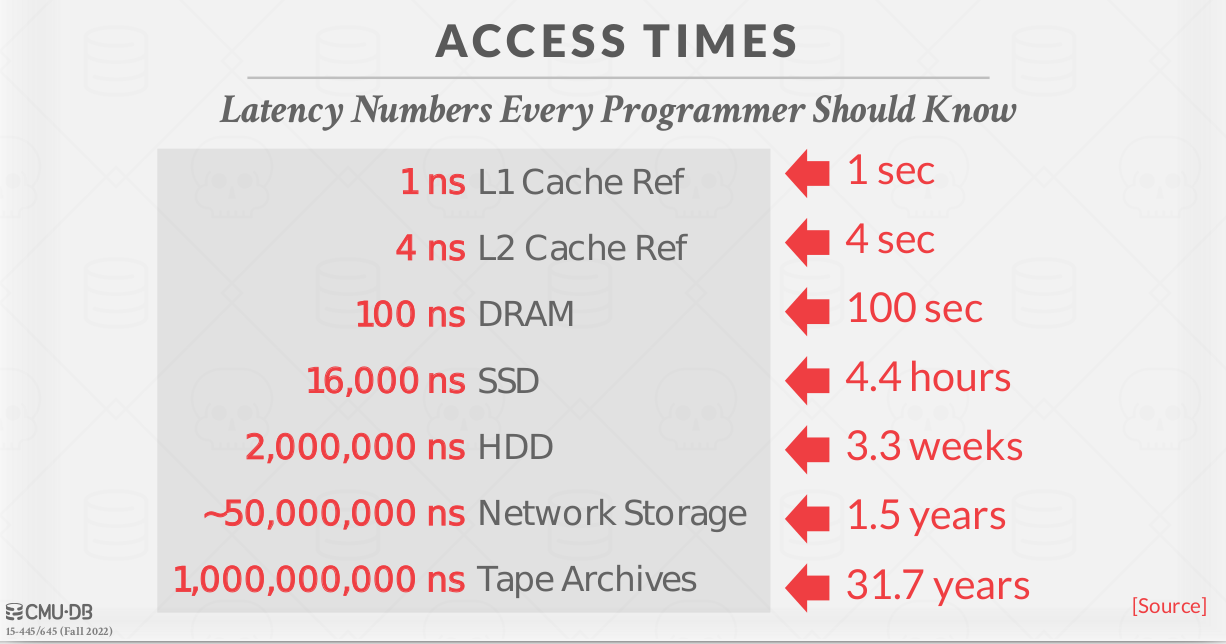 |
|---|
| Storage Access Time – source |
You may see references to NVMe SSDs, where NVMe stands for non-volatile memory express. These NVMe SSDs are not the same hardware as persistent memory modules. Rather, they are typical NAND flash drives that connect over an improved hardware interface. This improved hardware interface allows for much faster transfers, which leverages improvements in NAND flash perfomance.
Since our DBMS architecture assumes that the database is stored on disk, the components of the DBMS are responsible for figuring out how to move data between non-volatile disk and volatile memory since the system cannot operate on the data directly on disk.
We will focus on hiding the latency of the disk rather than optimizations with registers and caches since getting data from disk is so slow. If reading data from the L1 cache reference took one second, reading from an SSD would take hours, and reading from an HDD would take weeks.
System Design goals
- Allow the DBMS to manage databases that exceed the amount of memory available.
- Reading/writing to disk is expensive, so it must be managed carefully to avoid large stalls and performance degradation.
- Random access on disk is usually much slower than sequential access, so the DBMS will want to maximize sequential access.
2. Disk-Oriented DBMS overview #
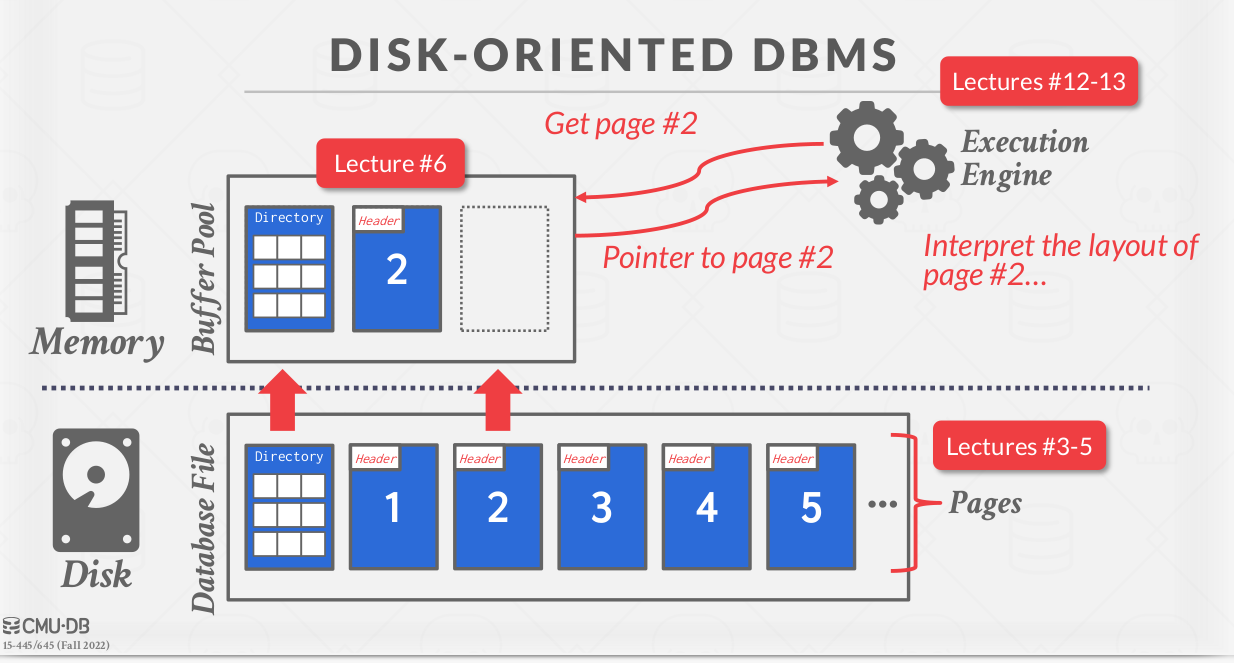 |
|---|
| Disk oriented archtecture |
The database is all on disk, and the data in database files is organized into pages, with the first page being the directory page. To operate on the data, the DBMS needs to bring the data into memory. It does this by having a buffer pool that manages the data movement back and forth between disk and memory. The DBMS also has an execution engine that will execute queries. The execution engine will ask the buffer pool for a specific page, and the buffer pool will take care of bringing that page into memory and giving the execution engine a pointer to that page in memory. The buffer pool manager will ensure that the page is there while the execution engine operates on that part of memory.
3. DMBS vs. OS #
This high-level design goal and overview above are like virtual memory, where there is a large address space and a place for the OS to bring in pages from disk.
One way to achieve this virtual memory is by using mmap to map the contents of a file in a process’ address space, which makes the OS responsible for moving pages back and forth between disk and memory.
Unfortunately, this means that if mmap hits a page fault, the process/thread will be blocked.
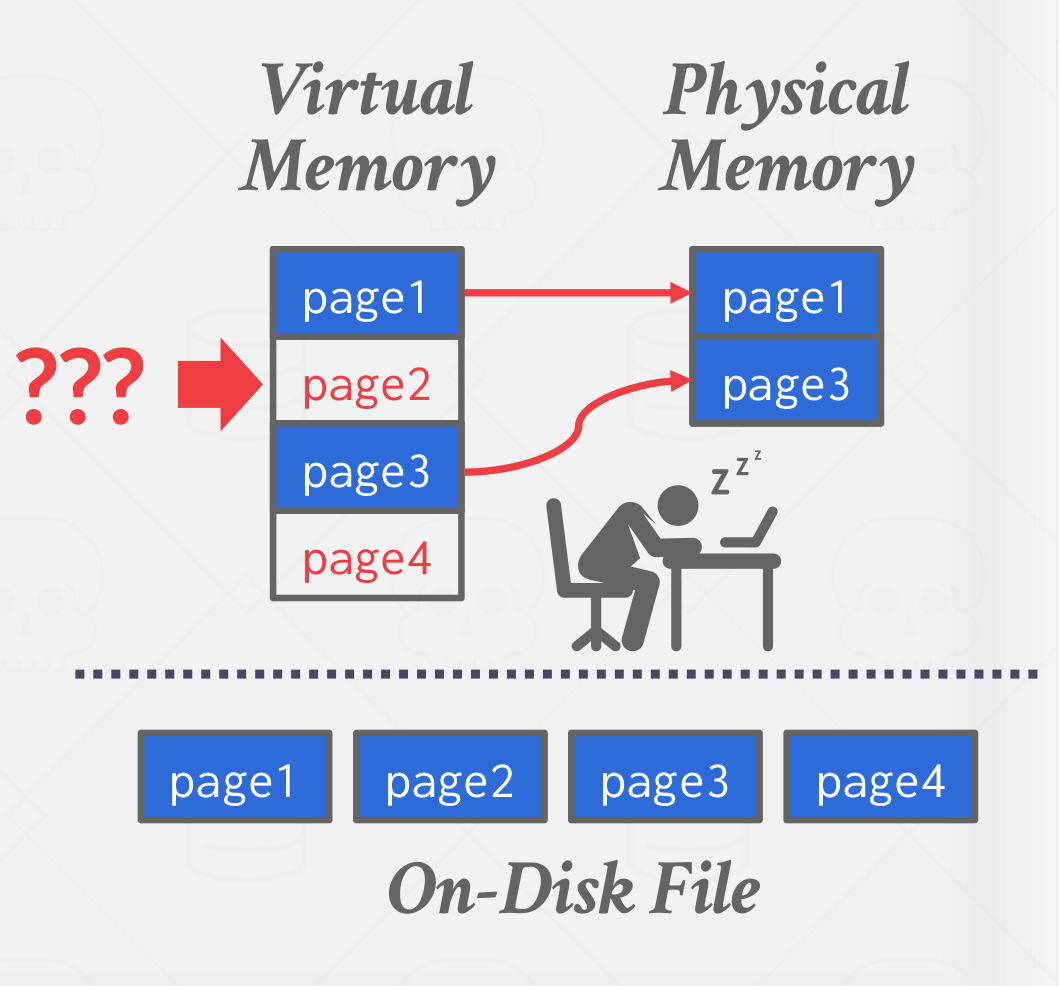 |
|---|
| mmap stall the process/thread caused by a page fault |
Memory mapped I/O problems
- Problem #1: Transaction safety
- OS can flush dirty pages at any time
- Problem #2: I/O Stall
- DBMS doesn’t know which pages are in memory.
- The OS will stall a thread on page fault.
- Problem #3: Error Handling
- Difficult to validate pages.
- Any access can cause a
SIGBUSthat DBMS must handle.
- Problem #4: Performance Issues
- OS data structure contention.
- TLB shootdowns.
The DBMS (almost) always wants to control things itself and can do a better job at it since it knows more about the data being accessed and the queries being processed.
- Flushing dirty pages to disk in the correct order.
- Specialized prefetching.
- Buffer replacement policy.
- Thread/process scheduling.
4. File Storage #
In its most basic form, a DBMS stores a database as files on disk. Some may use a file hierarchy, others may use a single file (e.g., SQLite). The OS does not know anything about the contents of these files. Only the DBMS knows how to decipher their contents, since it is encoded in a way specific to the DBMS.
Storage manager
The DBMS’s storage manager is responsible for managing a database’s files. It represents the files as a collection of pages. It also keeps track of what data has been read and written to pages as well how much free space there is in these pages. It may do their own scheduling for reads and writes to improve spatial and temporal locality of pages.
5. Database Pages #
The DBMS organizes the database across one or more files in fixed-size blocks of data called pages. Pages can contain different kinds of data (tuples, indexes, etc). Most systems will not mix these types within pages. Some systems will require that pages are self-contained, meaning that all the information needed to read each page is on the page itself.
Each page is given a unique identifier, a.k.a page number or page id. If the database is a single file, then the page id can just be the file offset. Most DBMSs have an indirection layer that maps a page id to a file path and offset. The upper levels of the system will ask for a specific page number. Then, the storage manager will have to turn that page number into a file and an offset to find the page.
Most DBMSs uses fixed-size pages to avoid the engineering overhead needed to support variable-sized pages. For example, with variable-size pages, deleting a page could create a hole in files that the DBMS cannot easily fill with new pages.
There are three concepts of pages in DBMS:
- Hardware page (usually 4 KB).
- OS page(4 KB).
- Database page(1-16KB).
 |
|---|
| Database page size |
The storage device guarantees an atomic write of the size of the hardware page. If the hardware page is 4KB and the system tries to write 4KB to disk, either all 4KB will be written, or none of it will. This means that if our database page is larger than our hardware page, the DBMS will have to take extra measures to ensure that the data gets written out safely since the program can get partway through writing a database page to disk when the system crashes.
6. Database Heap #
Different DBMSs manage pages in files on disk in different ways.
There are a couple of ways to find the location of the page a DBMS wants on the disk, and heap file organization is one of those ways.
A heap file is an unordered collection of pages where tuples are stored in random order. it supports operations like
- Create/Get/Write/Delete Page
- Must also support iterating over all pages.
In order to find pages with given page page number in case of multiple database files, DBMS need meta-data to keep trck of what pages exists in multipe files and which ones have free space. the most common approach is called page directory
Page Directory
The DBMS maintains special pages that track locations of data pages along with the amount of free space on each page. DBMS must make sure that the directory pages are in sync with the data pages.
The directory also records meta-data about the available space:
- The number of free slots per page.
- List of free / empty pages
7. Page layout #
Every page includes a header that records meta-data about the page’s contents:
- Page size.
- Checksum.
- DB-MS version
- Transaction visibility.
- Compression Information
Some systems require pages to be self-contained(e.g., Oracle)
There are two main approaches to laying out data in pages. i.e., how to organize the data inside of the page:
- Slotted-page
- Log-structured(Covered in Part 2)
Slotted pages: Page maps slots to offsets.
- Most common approach used in DBMSs today.
- Header keeps track of the number of used slots, the offset of the starting location of the last used slot, and a slot array, which keeps track of the location of the start of each tuple.
- To add a tuple, the slot array will grow from the beginning to the end, and the data of the tuples will grow from end to the beginning. The page is considered full when the slot array and the tuple data meet.
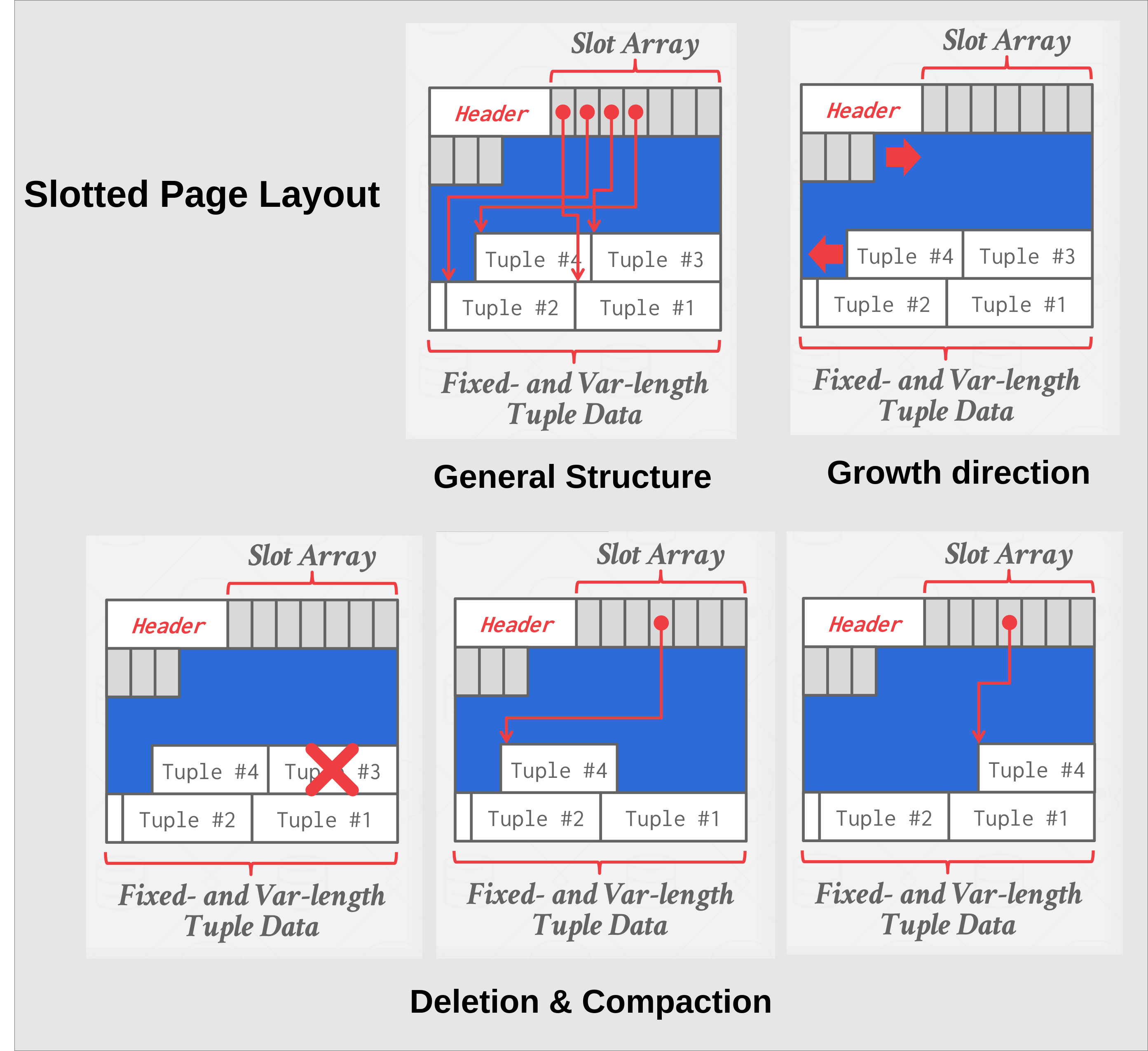 |
|---|
| Slotted page layout |
The DBMS needs a way to keep track of individual tuples. Each tuple is assigned a unique record identifier.
- Most common: page_id + offset/slot
- Can also contain file location info
An application cannot rely on these IDs to mean anything.
8. Tuple layout #
A tuple is essentially a sequence of bytes. It is the DBMS’s job to interpret those bytes into attribute types and values.
Tuple Header: Contains meta-data about the tuple.
- Visibility information for the DBMS’s concurrency control protocol (i.e., information about which transaction created/modified that tuple).
- Bit Map for NULL values. -Note that the DBMS does not need to store meta-data about the schema of the database here.
Tuple Data: Actual data for attributes.
- Attributes are typically stored in the order that you specify them when you create the table.
- Most DBMSs do not allow a tuple to exceed the size of a page.
Unique Identifier:
- Each tuple in the database is assigned a unique identifier.
- Most common: page id + (offset or slot).
- An application cannot rely on these ids to mean anything.
Denormalized Tuple Data: If two tables are related, the DBMS can “pre-join” them, so the tables end up on the same page. This makes reads faster since the DBMS only has to load in one page rather than two separate pages. However, it makes updates more expensive since the DBMS needs more space for each tuple.
9. Conclusion #
- Database is organized in pages.
- Track pages with Heap file and page directory.
- Using slotted page and log-structured page as the page layout.
- Tuple layout.